采用pytorch搭建神经网络,解决kaggle平台手写字识别问题。
数据来源:https://www.kaggle.com/competitions/digit-recognizer/data
参考pytorch官网:https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
数据预处理
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
输出:
/kaggle/input/digit-recognizer/sample_submission.csv
/kaggle/input/digit-recognizer/train.csv
/kaggle/input/digit-recognizer/test.csv
读取数据查看数据结构
train_df = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
train_df.head(5)
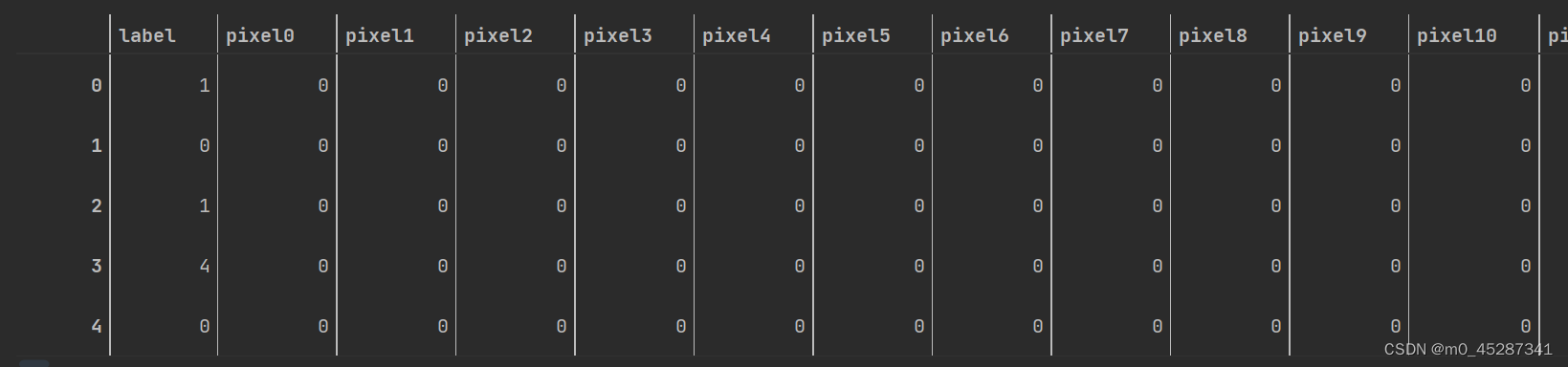
可以出第一行为标签,后面的pixel0~783为像素点灰度值
对数据进行归一化和预处理
train_feature_df = train_feature_df/255.0
train_feature_df = train_feature_df.apply(lambda x: x.values.reshape(28, 28),axis=1)
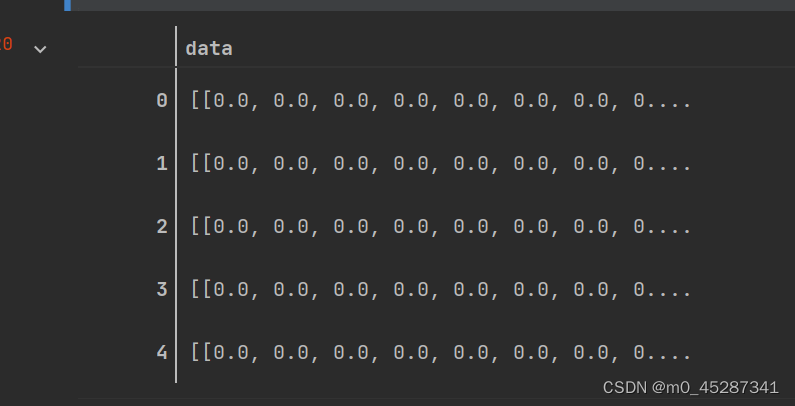
此时的数据格式为data列中存储的是28*28的numpy类型的矩阵
自定义DataSet
在pytorch官网手册中的Dataset部分有关于自定义Dataset的详细讲解(https://pytorch.org/tutorials/beginner/basics/data_tutorial.html)。
import pandas as pd
import torch
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, img_label, img_data, transform=None, target_transform=None):
self.img_labels = img_label
self.images = img_data
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
# 两个均为series类型所以不能调用loc函数,直接索引取即可
image = self.images[idx]
label = self.img_labels[idx]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
使用我们自定的Dataset对数据进行转换,转换为Dataset类型
from torchvision.transforms import ToTensor
train_dataset = CustomImageDataset(train_label_df, train_feature_df, ToTensor())
train_dataset[0]
查看数据结构可知,数据为[(*label数据(数值类型),图像数据(tensor类型))]
查看数据的图像
此部分代码也可在pytorch官网中查看详细讲解
import matplotlib.pyplot as plt
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(train_dataset), size=(1,)).item()
img, label = train_dataset[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(label)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
输出图像:

将Dataset转化为可迭代图像dataloader
先对训练集数据按训练集:测试集=8:2的比例进行分割,分割后的数据分别转换为dataloader。
from torch.utils.data import DataLoader
from torch.utils.data import random_split
train_dataset, test_dataset = random_split(train_dataset, [int(0.8*len(train_dataset)), int(0.2*len(train_dataset))])
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=True)
构建标准神经网络(SNN)
import torch.optim as optim
from torch import nn
class NeuralNetWork(nn.Module):
def __init__(self):
super(NeuralNetWork, self).__init__()
self.flatten = nn.Flatten() # 把28*28压平成784
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512,256),
nn.ReLU(),
nn.Linear(256, 10),
nn.Softmax(dim=1)
)
def forward(self,x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device:{device}")
model = NeuralNetWork().to(device)
定义超参数、损失函数和优化器
迭代次数:n_epochs=0
学习率:learn_rate=0.01
批处理个数:batch=64 #在上方dataloader定义时已指定
损失函数这里使用交叉熵损失函数(CrossEntropyLoss)
优化器使用随机梯度优化器(SGD)
# 定义参数
n_epochs = 10
learn_rate = 0.01
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch,(X,y) in enumerate(dataloader):
X = X.float().to(device)
y = y.to(device)
pred = model(X)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch%64 == 0:
# current代表当前是第几条数据
loss,current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
# test中总的size表示总的图像数
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X = X.float().to(device)
y = y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size # 小数的形式,下面*100是转成百分数的形式
print(f"Test Error: n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} n")
loss_fn = nn.CrossEntropyLoss()
# 随机梯度下降进行反向传播
optimizer = optim.SGD(model.parameters(), lr=learn_rate, momentum=0.5)
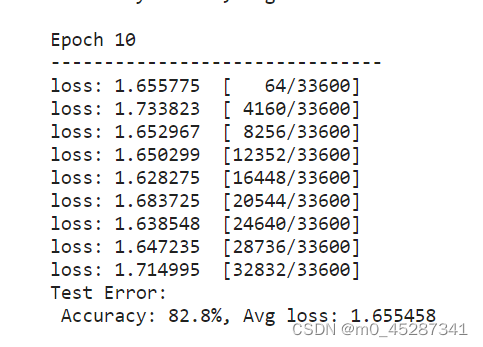
for t in range(n_epochs):
print(f"Epoch {t+1}n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
从输出的结构可以看出我们预测的准确率可以达到82.8%,属于很不错的结果了。
数据预测
对test.scv文件中的数据进行预测
# 对数据进行预测
test_df = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
test_ts = torch.from_numpy(test_df.values).reshape(len(test_df),28,28).float().to(device)
print(f"test_ts.shape:{test_ts.shape}")
pred = model(test_ts)
print(f"result:{pred}",f"pred.shape{pred.shape}")
# 将数据从独热编码的格式中还原
pred_data = pred.argmax(1)
# 注意这里的+1是为了和赛题的文件的预测格式保持一致
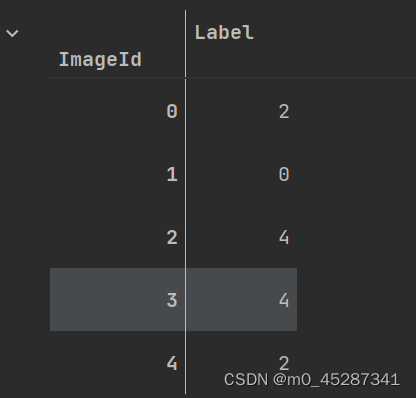
result_df = pd.DataFrame({}, index=test_df.index+1)
result_df.index.name = "ImageId"
result_df["Label"] = pred_data.cpu().detach().numpy()
result_df.head()
保存结果
result_df.to_csv("./data/output/result.csv")
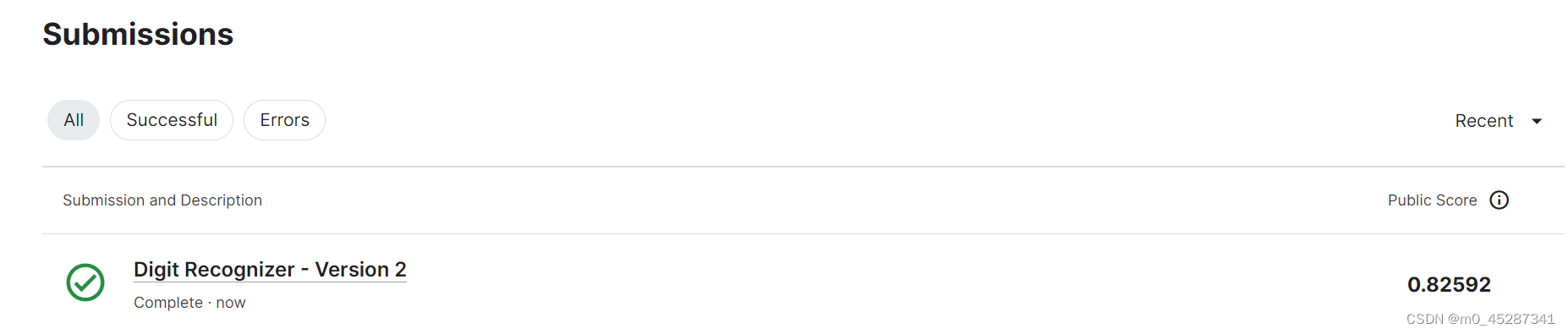
上传提交
查看kaggle得分82.59还算不错的分数,后续可以对算法进行改进使用卷积神经网络可能会得到更高的分数哦。
最后
以上就是搞怪棉花糖最近收集整理的关于Pytorch入门练习-kaggle手写字识别神经网络(SNN)实现的全部内容,更多相关Pytorch入门练习-kaggle手写字识别神经网络(SNN)实现内容请搜索靠谱客的其他文章。






![[管理笔记] 03.如何选择乙方1.如何选择乙方2.如何帮甲方理清需求相关阅读](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)

发表评论 取消回复