重学深度学习系列-- AlexNet猫狗分类(TensorFlow2)
文章目录
- 重学深度学习系列-- AlexNet猫狗分类(TensorFlow2)
- 一、我的环境
- 二、工程结构
- 三、AlexNet介绍
- 3.1 主要贡献
- 3.2 网络结构
- 四、AlexNet的TensorFlow2代码实现
- 五、训练
- 5.1 开始训练
- 5.2 适当调参优化
- 5.3 设置动态的学习率
- 六、调用图片进行预测
- image-20220301170230560
- 参考资料
一、我的环境
windows10 + pycharm , TensorFlow2.3.0
二、工程结构
整个工程项目已分享在百度网盘:(含数据集和模型一共有128MB)
链接:https://pan.baidu.com/s/114TZ4KTpm0Ha0SGsFhn9fQ
提取码:fnvj
–来自百度网盘超级会员V4的分享
三、AlexNet介绍
AlexNet论文下载链接:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。
AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN(Local Response Normalization)等Trick。同时AlexNet也使用了GPU进行运算加速。
3.1 主要贡献
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:(来自百度百科的总结)
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256×256的原始图像中截取224×224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
3.2 网络结构
在论文中AlexNet的网络结构图如下:
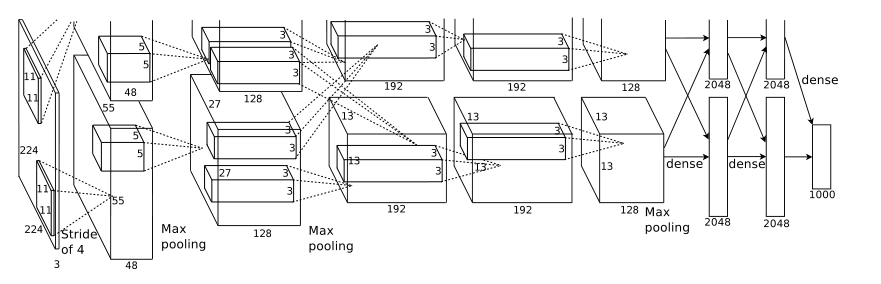
主要有五个卷积层+三个全连接层:
输入图像尺寸:224×224×3
第1层:卷积层
卷积核个数:96
卷积核尺寸:11×11
步长:4
是否使用全零填充:否
接着使用了3×3的最大池化,步长为2,不使用全零填充。
第2层:卷积层
卷积核个数:256
卷积核尺寸:5×5
步长:1
是否使用全零填充:是
接着使用了3×3的最大池化,步长为2,不使用全零填充。
第3层:卷积层
卷积核个数:384
卷积核尺寸:3×3
步长:1
是否使用全零填充:是
第4层:卷积层
卷积核个数:384
卷积核尺寸:3×3
步长:1
是否使用全零填充:是
第5层:卷积层
卷积核个数:256
卷积核尺寸:3×3
步长:1
是否使用全零填充:是
接着使用了3×3的最大池化,步长为2,不使用全零填充。
第6层:全连接层
神经元个数:4096
droput:0.5
第7层:全连接层
神经元个数:4096
droput:0.5
第8层:全连接层
神经元个数:1000 (输出1000分类)
值得注意的是,以上参数是在使用两块GPU的环境下选择的,目前我只是在笔记本上一块GPU上跑,所以参数选择其中的一半即可,例如我的卷积核个数为原来的一半,全连接层的个数也可以调整为原来的一半或者是四分之一甚至更小。
四、AlexNet的TensorFlow2代码实现
卷积核个数和全连接层的个数都经过了一部分调整,要么为原来的一半,要么是四分之一。
# 构建模型
model = tf.keras.models.Sequential([
# 第一层
tf.keras.layers.Conv2D(48, (11, 11), input_shape=(224, 224, 3),strides=4,padding='valid',activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
# 第二层
tf.keras.layers.Conv2D(128, (5, 5),activation='relu',padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
# 第三层
tf.keras.layers.Conv2D(192, (3, 3),padding='same',activation='relu'),
# 第四层
tf.keras.layers.Conv2D(192, (3, 3),padding='same',activation='relu'),
# 第五层
tf.keras.layers.Conv2D(128, (3, 3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
tf.keras.layers.Flatten(),
# 第六层
tf.keras.layers.Dense(1024,activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第七层
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第八层
tf.keras.layers.Dense(1, activation='sigmoid')
])
由于是猫狗分类,所以最后一层可以输出1,也可以输出2,输出1时直接输出是哪一类,输出2时是输出两类各自的概率。
五、训练
5.1 开始训练
以下是train.py:
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
from tensorflow.keras import regularizers
# 加载数据集
base_dir = './datasets/cats_and_dogs/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 构建模型
model = tf.keras.models.Sequential([
# 第一层
tf.keras.layers.Conv2D(48, (11, 11), input_shape=(224, 224, 3),strides=4,padding='valid',activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
# 第二层
tf.keras.layers.Conv2D(128, (5, 5),activation='relu',padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
# 第三层
tf.keras.layers.Conv2D(192, (3, 3),padding='same',activation='relu'),
# 第四层
tf.keras.layers.Conv2D(192, (3, 3),padding='same',activation='relu'),
# 第五层
tf.keras.layers.Conv2D(128, (3, 3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D((3,3),strides=2,padding='valid'),
tf.keras.layers.Flatten(),
# 第六层
tf.keras.layers.Dense(1024,activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第七层
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第八层
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 总结输出网络参数
model.summary()
# 配置模型训练的参数
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=1e-4), metrics=['acc'])
# 进行数据增强
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
img_size = (224, 224)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=img_size, # 与网络的固定输入一致
batch_size=8,
class_mode='binary' # one-hot编码格式,在预测时输出也要注意
)
validation_generator = train_datagen.flow_from_directory(
validation_dir,
target_size=img_size,
batch_size=8,
class_mode='binary'
)
# 加载训练数据
history = model.fit_generator(
train_generator,
steps_per_epoch=100, # 2000 images = batchsize * steps
epochs=100,
validation_data=validation_generator, # 1000 images = batchsize * steps
validation_steps=50,
verbose=2
)
# 保存训练好的模型
model.save('./model.h5')
# 将训练结果可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
以下是训练100轮后的结果:

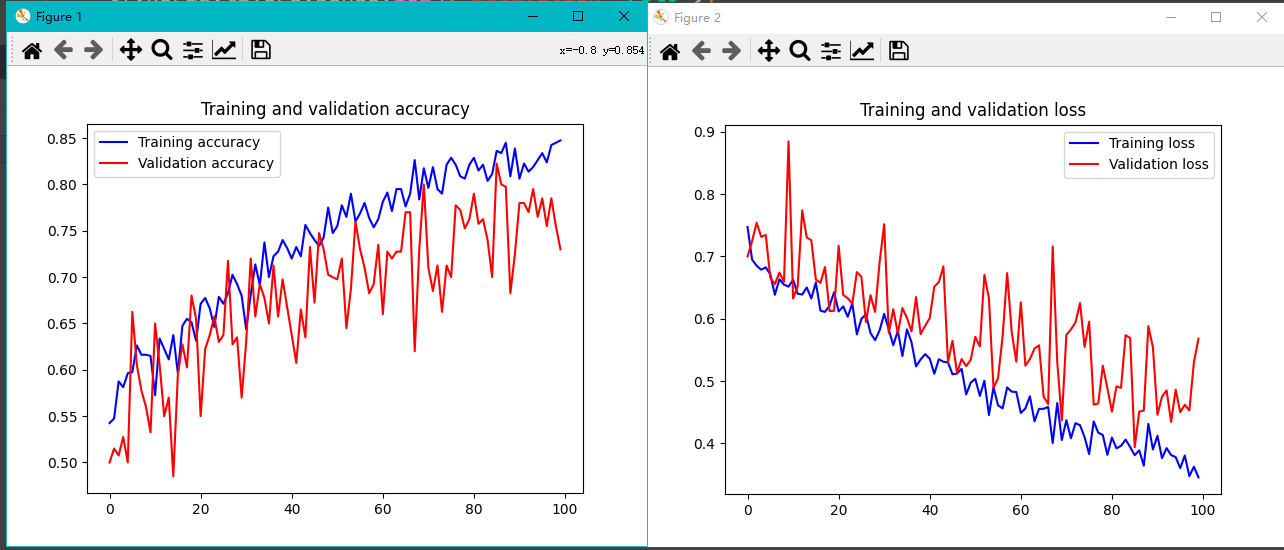
从上面的结果看出有些过拟合了。
5.2 适当调参优化
由于有些过拟合了,所以我加入了正则化和BN,(读者可以尝试relu放在BN之前和之后,效果可能会不一样)并重新训练:
# 构建模型
model = tf.keras.models.Sequential([
# 第一层
tf.keras.layers.Conv2D(48, (11, 11), input_shape=(224, 224, 3), strides=4, padding='valid',activation='relu',
kernel_regularizer=regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3, 3), strides=2, padding='valid'),
# 第二层
tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='relu',kernel_regularizer=regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3, 3), strides=2, padding='valid'),
# 第三层
tf.keras.layers.Conv2D(192, (3, 3), padding='same',activation='relu', kernel_regularizer=regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
# 第四层
tf.keras.layers.Conv2D(192, (3, 3), padding='same', activation='relu',kernel_regularizer=regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
# 第五层
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation='relu',kernel_regularizer=regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((3, 3), strides=2, padding='valid'),
tf.keras.layers.Flatten(),
# 第六层
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第七层
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dropout(0.25),
# 第八层
tf.keras.layers.Dense(1, activation='sigmoid')
])
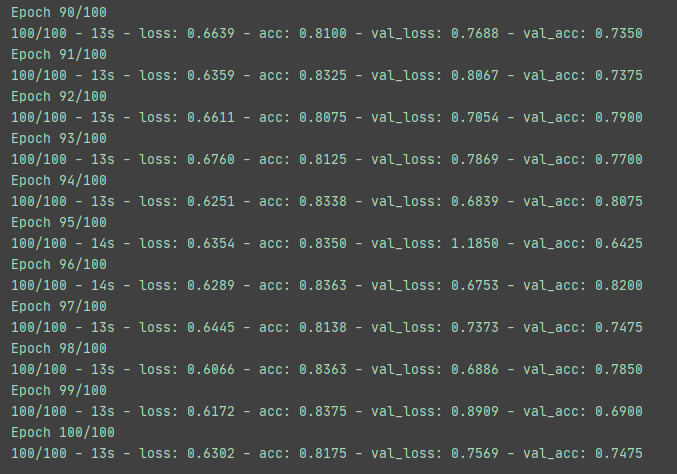
可以看到过拟合有了一定程度的缓解。但是这中间过程有点抖动得厉害,所以如果要是可以设置动态的学习率那么应该会好一点。
5.3 设置动态的学习率
设置动态的学习率有多种办法,我这里采用ReduceLROnPlateau这个API。
官网给出的例子:
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001)
model.fit(X_train, Y_train, callbacks=[reduce_lr])
ReduceLROnPlateau()参数说明:
monitor:监测的值,可以是loss,acc,val_loss,val_acc,lr
factor:缩放学习率的值,学习率将以lr = lr*factor的形式被减少
patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
mode:‘auto’,‘min’,‘max’之一 默认‘auto’就行
epsilon:阈值,用来确定是否进入检测值的“平原区”
cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
min_lr:学习率最小值,能缩小到的下限
verbose: 详细信息模式,0 或者 1 。
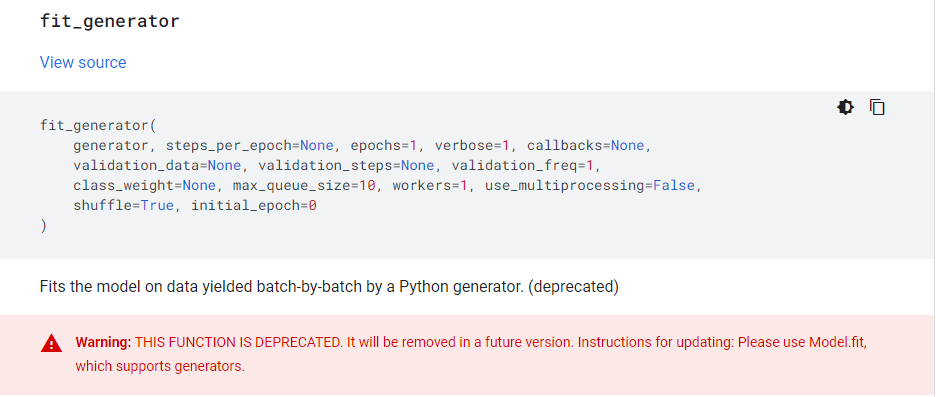
值得注意的是,TensorFlow2.3.0版本中官网有介绍说model.fit_generator这个API在后续版本中不再支持,建议使用model.fit(),所以我后面也改为使用model.fit()这个API。(参看下图warning:)
设置动态的学习率:
from tensorflow.keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=5, min_lr=1e-5, verbose=1)
history = model.fit(
train_generator,
steps_per_epoch=100, # 2000 images = batchsize * steps
epochs=100,
validation_data=validation_generator, # 1000 images = batchsize * steps
validation_steps=50,
callbacks=[reduce_lr], # 设置动态的学习率
verbose=2)
设置完成后再训练,可以看到曲线更平滑了一些:
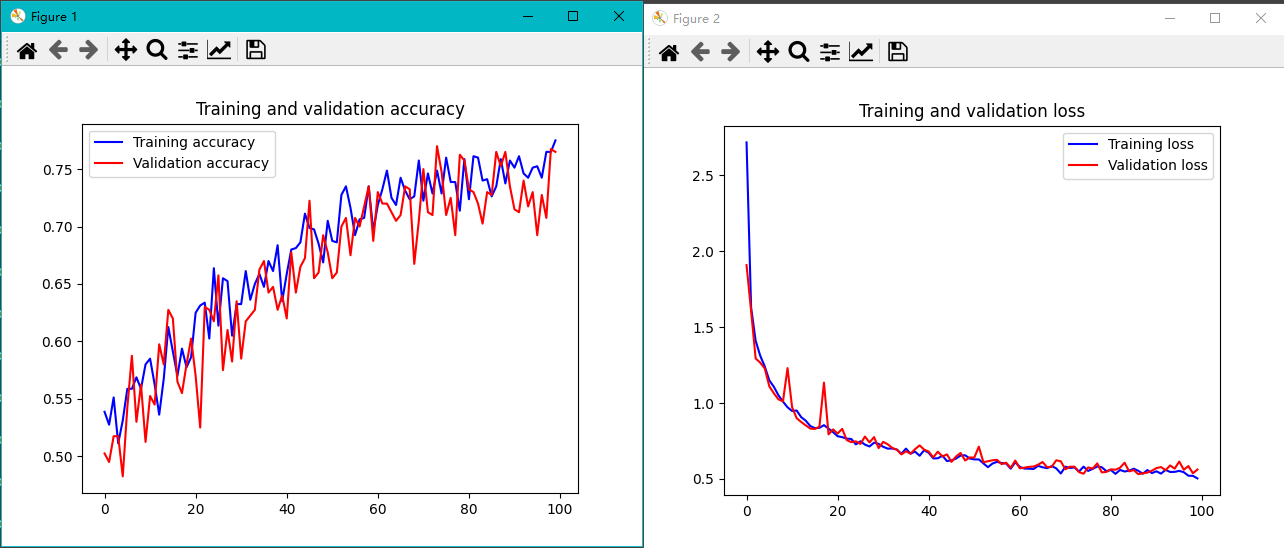
但是准确率却有所下降:

但是,不难看出模型还能进一步收敛,读者可以尝试延长epoch,或者把学习率适当调大一点。
六、调用图片进行预测
import numpy as np
from tensorflow.keras.models import load_model
import cv2
# 种类字典
class_dict = {0: '猫', 1: '狗'}
def predict(img_path):
# 载入模型
model = load_model('./model.h5')
# 载入图片,并处理
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_nor = img_RGB / 255
img_nor = np.expand_dims(img_nor, axis=0)
# 预测
# print((np.argmax(model.predict(img_nor))))
# print(model.predict(img_nor))
y = model.predict_classes(img_nor)
print(class_dict.get(y[0][0])) # 直接输出种类 0是猫 1是狗
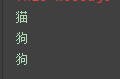
if __name__ == "__main__":
predict('./datasets/cats_and_dogs/test/cat.1500.jpg') # 0
predict('./datasets/cats_and_dogs/test/dog.1500.jpg') # 1
predict('./datasets/cats_and_dogs/test/dog.1504.jpg') # 1
参考资料
1.AlexNet论文:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
2.动态学习率参数说明参考:https://blog.csdn.net/qq_40128284/article/details/117018755
3.动态学习率设置官方API文档:https://tensorflow.google.cn/versions/r2.3/api_docs/python/tf/keras/callbacks/ReduceLROnPlateau
最后
以上就是平常雨最近收集整理的关于重学深度学习系列-- AlexNet猫狗分类(TensorFlow2)重学深度学习系列-- AlexNet猫狗分类(TensorFlow2)的全部内容,更多相关重学深度学习系列--内容请搜索靠谱客的其他文章。








发表评论 取消回复