记录了一些问题,笔记内容基本都是来自于UVM实战,不得不说,这书真香!
1. `uvm_fatal(参数1,参数2) ,打印完第2个参数后,就会直接调用Verilog的finish函数来结束仿真(P60)
2. 无论传递给run_test的参数是什么,创建的实例的名字都为uvm_test_top.
3. 在drive_one_pkt 中,先将tr中所有的数据压入队列data_q中,之后再将data_q中所有的数据弹出并驱动。将tr中的数据压入队列data_q中的过程相当于打包成一个byte流的过程。这个过程还可以使用SystemVerlog提供的流操作符实现。(P68)
4. driver,monitor等众多组件为什么不在top_tb中例化? 在top_tb中使用run_test进行实例化显然是不行的,因为run_test函数虽然强大,但也只能实例化一个实例(P70)。
5. phase的执行顺序:build_phase的执行遵照从树根到树叶的顺序,即先执行my_env的build_phase,再执行 my_driver的build_phase。当把整棵树的build_phase都执行完毕后,再执行后面的phase(P73);与build_phase不同的是,connect_phase的执行顺序并不是从树根到树叶,而是从树叶到树根——先执行driver和monitor的connect_phase,再执行agent的connect_phase,最后执行env的connect_phase。(P95)
6. 数据的发送有多种方式,其中一种是使用uvm_analysis_port,write是其内建函数;数据接收方式也有多种,其中一种就是使用uvm_blocking_get_port,在main_phase中,通过port.get任务来得到从i_agt的monitor中发出的transaction;在my_monitor和my_model中定义并实现了各自的端口之后,通信的功能并没有实现,还需要在my_env中使用fifo将两个端口联系在一起。为什么这里需要一个fifo呢?不能直接把my_monitor中的analysis_port和my_model中的blocking_get_port相连吗?由于 analysis_port是非阻塞性质的,ap.write函数调用完成后马上返回,不会等待数据被接收。假如当write函数调用时,blocking_get_port正在忙于其他事情,而没有准备好接收新的数据时,此时被write函数写入my_transaction就需要一个暂存的位置,这就是fifo。(P95)
7. 每一个 sequence都有一个body任务,当一个sequence启动之后,会自动执行body中的代码,body中的代码可以自定义,添加`uvm_do,`uvm_do 它用于:①创建一个my_transaction的实例m_trans;②将其随机化;③最终将其送给 sequencer。(P116)
8. driver如何向sequencer申请transaction呢?在uvm_driver中有成员变量seq_item_port,而在uvm_sequencer中有成员变量seq_item_export,这两者之间可以建立一个“通道”,二者连接好之后,就可以在driver中通过get_next_item任务向sequencer申请新的transaction.(P117)
9. sequence的启动方式:1)调用start任务。start任务的参数是一个sequencer指针,如果不指明此指针,则sequence不知道将产生的transaction交给哪个sequencer。例如:seq.start(i_agt.sqr) P119; 2)第一种启动方式,sequence是在my_env的main_phase中手工启动的,实际应用中使用最多的还是通过default_sequence的方式启动sequence。使用default_sequence的方式非常简单,只需要在某个component(如my_env)的build_phase中设置如下代码即可:(P122)
virtual function void build_phase (uvm_phase phase);
super .build_phase (phase);
uvm_config_db# (uvm_object_wrapper) : :set (this,"i_agt .sqr .main_phase","default_sequence",my_sequence : :type_id : :get ());
endfunction
9. 设置UVM_ERROR 仿真退出的阈值,两种方法:1)在测试用例的build_phase中添加一行代码 set_report_max_quit_count(5),表示当UVM_ERROR达到5个后,仿真退出,除了build_phase外,在其他phase也可以设置;2)第2种方法是仿真命令行中添加+UVM_MAX_QUIT_COUNT=6,NO 其中第一个参数6表示退出阈值,而第二个参数NO表示此值是不可以被后面的设置语句重载,其值还可以是YES。(P198)
10. UVM支持内建的断点功能,当执行到断点时,自动停止仿真,进入交互模式。(P203)
11. UVM提供将特定信息输出到特定日志文件的功能,例如,可以将UVM_INFO、UVM_WARNING、UVM_ERROR及UVM_FATAL分类输出到指定的不同文件中,还可以根据id进行分类。(P205)
12. cfg_db的set/get的4个参数分别代表什么意思?
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
set: 其中第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信。第一个参数必须是一个uvm_component实 例的指针,第二个参数是相对此实例的路径。第三个参数表示一个记号,用以说明这个值是传给目标中的哪个成员的,第四个参数是要设置的值。
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
get: get函数中的第一个参数和第二个参数联合起来组成路径。第一个参数也必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。一般的,如果第一个参数被设置为this,那么第二个参数可以是一个空的字符串。第三个参数就是set函数中的第三个参数,这两个参数必须严格匹配,第四个参数则是要设置的变量。(P215)
13. 当要在test中添加内容,而这种改动会涉及到所有的testcase时,这个时候可以从两方面去考虑,1)要添加或修改的内容是否可以移植到base_test中,因为用户自己写的testcase都是继承于base_test,2)要添加的内容是否可以用仿真命令行的方式实现。
14. PORT和EXPORT体现的是控制流而不是数据流。因为在put操作中,数据流是从PORT流向EXPORT的,而在get操作中,数据是从EXPORT流向PORT的。但是无论是get还是put操作,其发起者拥有的都是PORT端口,而不是EXPORT。作为一个EXPORT来说,只能被动地接收PORT的命令。(P249)
15. UVM把一个端口固定为只能执行某种操作,如对于uvm_blocking_put_port#(T),它只能执行阻塞的put操作,想要执行非阻塞的put操作是不行的,想要执行get操作,也是不行的,更不用提执行transport操作了。如果想要其执行另外的操作,那么最好的方式是再另外使用一个端口。
16. 对于blocking系列端口来说,可以定义函数或者任务,对于nonblocking系列端口来说,只能定义函数,因为它是要立即返回,没有耗时。(P270)
17. UVM中端口类型主要有blocking/unblocking_get_port/export/imp,blocking/unblocking_put_port/export/imp,blocking/unblocking_transport_port/export/imp,除此之外,还有两种特殊的端口:analysis_port和analysis_export,特点是:1)一个analysis_port(analysis_export)可以连接多个IMP,2),没有阻塞和非阻塞的概念,3)只有一种操作:write,定义在analysis_imp所在的component中。(P291)
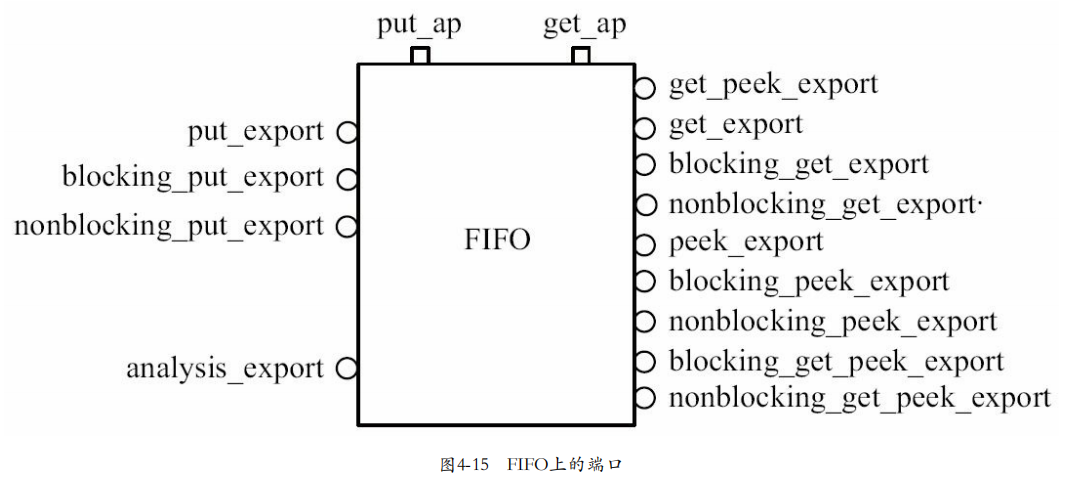
18. uvm_tlm_analysis_fifo有众多端口,如图所示:虽然名字中有export,但是本质上都是IMP(P307)
最后
以上就是明亮鼠标最近收集整理的关于UVM笔记的全部内容,更多相关UVM笔记内容请搜索靠谱客的其他文章。







![[UVM]UVM TLM FIFO使用方法總結 UVM TLM FIFO用法總結](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)
发表评论 取消回复