这里有一个灰度图像的集合,每个图像都是一个2x2的像素网格,每个像素在0(白色)和255(黑色)之间有一个强度值。我们的目标是建立一个模型,利用“阶梯”模式识别图像。

在这篇文章,我们只关心是否能够合理地匹配数据的模型。
预处理
对于每个图像,我们将像素用x1、x2、x3、x4标记,并生成一个输入向量mathbf{x}
mathbf{x} = begin{bmatrix}x_1 & x_2 & x_3 & x_4end{bmatrix}
这将是我们的模型的输入。我们期望我们的模型能够预测真(图像有阶梯模式)或假(图像没有阶梯模式)。

| 图像ID | x1 | x2 | x3 | x4 | 具有阶梯模式 |
| 1 | 252 | 4 | 155 | 175 | 真 |
| 2 | 175 | 10 | 186 | 200 | 真 |
| 3 | 82 | 131 | 230 | 100 | 假 |
| … | … | … | … | … | … |
| 498 | 36 | 187 | 43 | 249 | 假 |
| 499 | 1 | 160 | 169 | 242 | 真 |
| 500 | 198 | 134 | 22 | 188 | 假 |
单层感知器(模型迭代0)
我们构建一个简单的模型,是一个单层感知器。感知器使用输入的加权线性组合来返回一个预测值。如果预测的分数超过了选定的阈值,感知器就能预测为真,否则预测为假。
f(x)={begin{cases} 1 &{text{if }} w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 > threshold\ 0 & {text{otherwise}} end{cases}}
让我们把它重新表述如下:
widehat y = mathbf w cdot mathbf x + b
f(x)={begin{cases} 1 &{text{if }} widehat{y} > 0\ 0 & {text{otherwise}} end{cases}}
widehat{y} 是我们的预测分数。
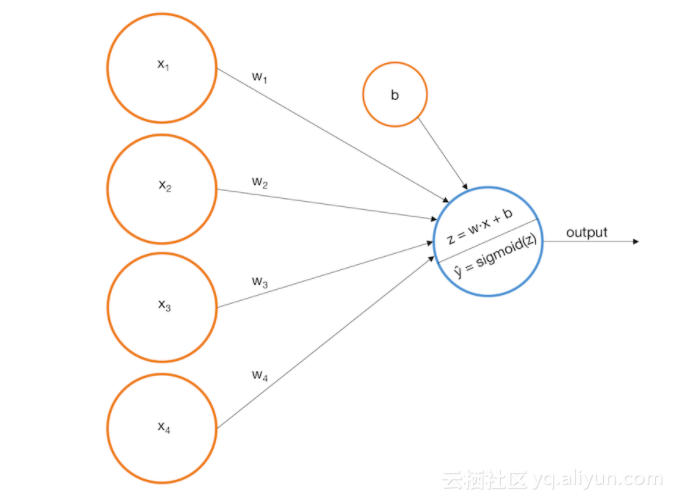
从以下图像上来说,我们可以把一个感知器作为输入节点。
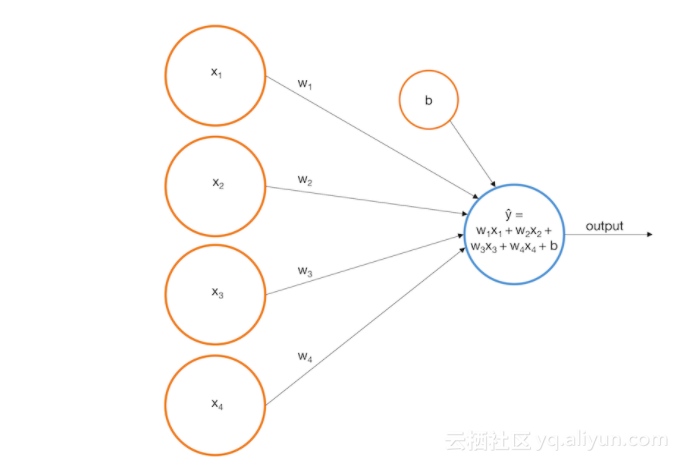
假设我们构建了以下感知器:
widehat{y} = -0.0019x_1 + -0.0016x_2 + 0.0020x_3 + 0.0023x_4 + 0.0003
以下是感知器在一些训练图像上的表现:
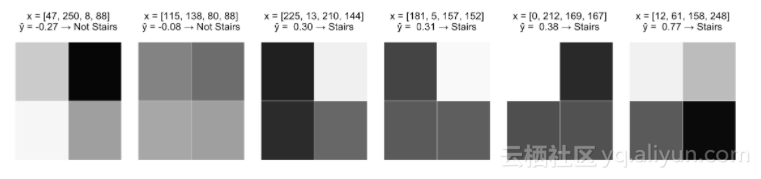
这肯定比随机猜测要好,而且也有一定的逻辑意义,但是这个模型还是存在一些明显的问题。
1.模型输出一个实数,其值与可能性的概念相关联(较高的值意味着图像代表阶梯的可能性更大),但不能将这些值作为概率的基础,因为它们可以在0-1范围之外。
2.该模型不能反映变量与目标之间的非线性关系。
请考虑以下情况:
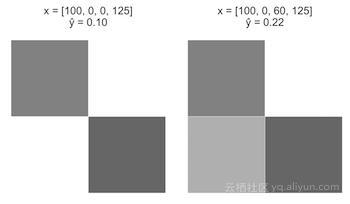
情况A:
从一个图像开始,x=[100,0,0,125]。将x_3从0增加到60。
情况B:
从上个图像开始,x=[100,0,60,125]。将x_3从60增加到120。
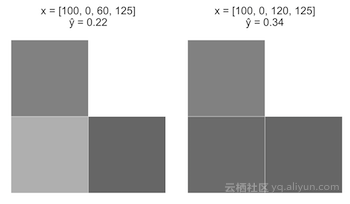
直观地说,在 widehat{y} 中,A的值应该比情形B大得多。然而,由于我们的感知器模型是一个线性方程,所以x_3的改变在这两种情况下,在widehat{y}中产生了等价的+0.12的变化。
现在我们先来解决这两个问题。
带有Sigmoid激励函数的单层感知器(模型迭代1)
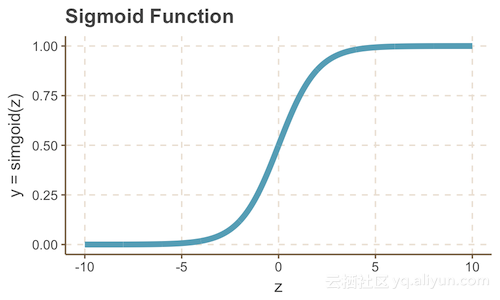
我们可以通过将感知器封装在一个sigmoid函数中(随后选择不同的权重)来解决上面的问题。回忆一下,sigmoid函数是一个S形曲线,在0到1之间的垂直轴上有一个S形曲线,因此经常被用来模拟一个二进制事件的概率。
sigmoid(z) = frac{1}{1 + e^{-z}}
因此,我们可以用下面的图片和等式来更新我们的模型:
z = w cdot x = w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4
widehat y = sigmoid(z) = frac{1}{1 + e^{-z}}
看起来熟悉吗?这是逻辑回归,它是一个sigmoid“激励函数”,这给我们提供了更大的泛化空间。此外,由于我们现在将widehat y 解释为一个概率,因此我们必须相应地更新我们的决策规则:
f(x)={begin{cases} 1 &{text{if }} widehat{y} > 0.5\ 0 & {text{otherwise}} end{cases}}
继续我们上述问题,假设我们提出了以下合适的模型:
begin{bmatrix} w_1 & w_2 & w_3 & w_4 end{bmatrix} = begin{bmatrix} -0.140 & -0.145 & 0.121 & 0.092 end{bmatrix}
b = -0.008
widehat y = frac{1}{1 + e^{-(-0.140x_1 -0.145x_2 + 0.121x_3 + 0.092x_4 -0.008)}}
现在观察该模型在相同示例图像上执行的结果。
显然,这修复了上面的问题1。
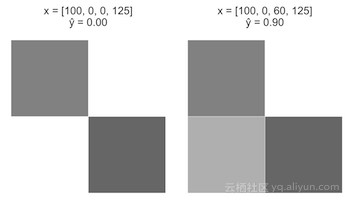
情况A
从一个图像开始,x=[100,0,0,125]。将x_3从0增加到60。
情况B
从上个图像开始,x=[100,0,60,125]。将x_3从60增加到120。
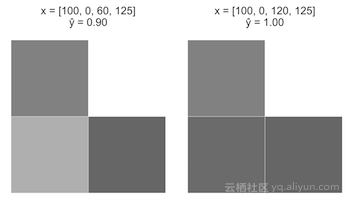
注意,当 z = w cdot x增加时,sigmoid函数的曲率将导致A快速增加,但是随着z的不断增加,速度会减慢。这与我们的直觉一致,即A情况是阶梯的可能性比B情况更大。
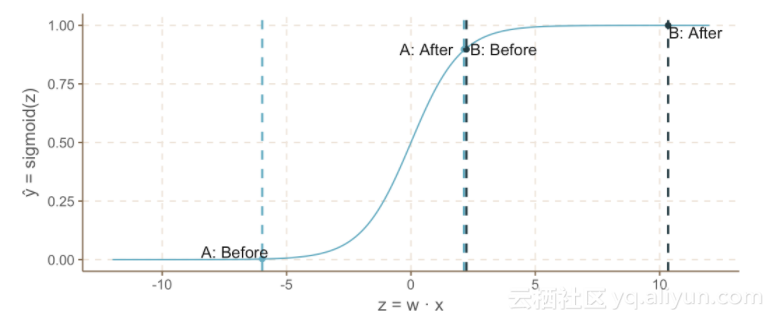
不幸的是,这个模型仍然有以下问题:
1. widehat y 与每个变量都有一个单调的关系,如果我们想要识别出有轻度阴影的阶梯呢?
2.假设图像的最下面一行是黑色的。如果左上角的像素是白色的,那么最右边的像素就会变暗,这就增加了阶梯的可能性。如果左上角的像素是黑色的,那么最右边的像素就会变暗,这就会降低阶梯的可能性。换句话说,x_3的变化可能会增加或减少widehat y ,这取决于其他变量的值。我们目前的模式没有办法做到这一点。
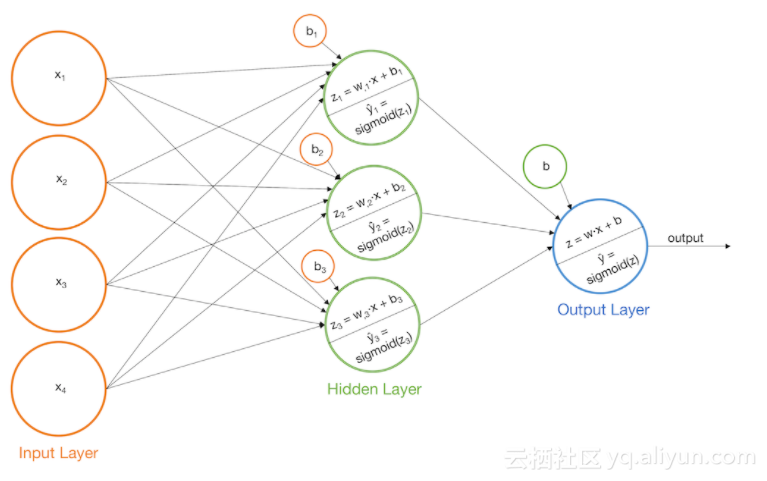
带有Sigmoid激励函数的多层感知器(Model迭代2)
我们可以通过在感知器模型中添加一个额外的层来解决上述两个问题。首先构建一些基本模型,然后我们将把每个基本模型的输出作为输入,输入到另一个感知器。这个模型实际上是一个普通的神经网络。让我们看看它在一些例子中是如何工作的。
例1:识别阶梯模式
1.当“左阶梯”被识别出来时,建立一个模型并触发widehat y_{left}。
2.当“右阶梯”被识别出来时,建立一个模型并触发widehat y_{right}。
3.添加基本模型的分数,以便最终的sigmoid函数只有当widehat y_{left}和widehat y_{right}值增大时才会触发。
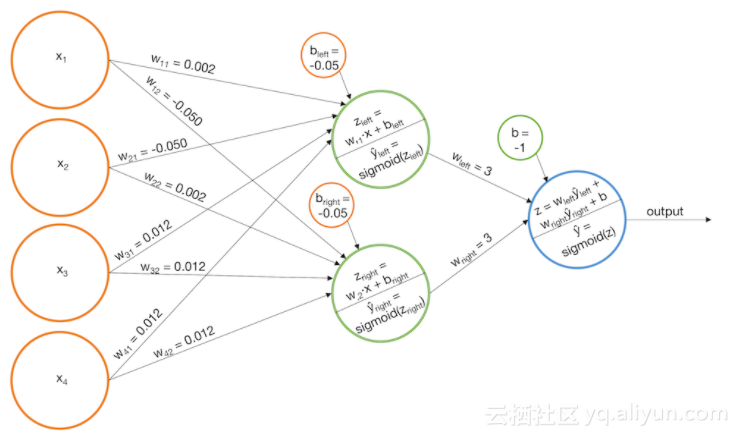
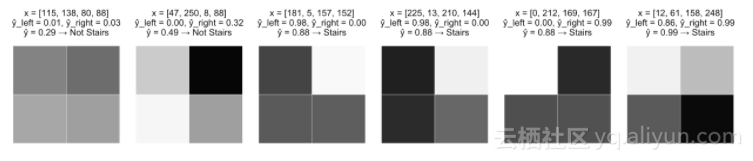
另外
1. 当最下面一行是黑色时,构建一个模型并触发widehat y_1。
2.当左上角的像素是黑色,右上角的像素是亮的时候,构建一个模型,并触发widehat y_2。
3.当左上角的像素是亮的,右上角的像素是黑色的时候,构建一个模型并触发widehat y_3。
4.添加基本模型,这样,如果widehat y_1和widehat y_2很大,或者widehat y_1和widehat y_3是很大的,那么最终的sigmoid函数会被触发。(请注意,widehat y_2和widehat y_3不能都是大的)
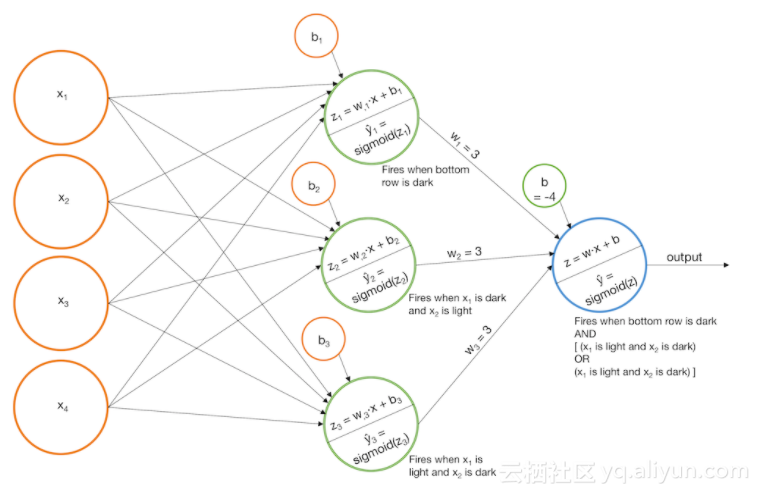
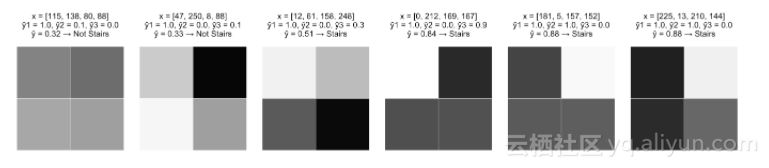
例2:识别轻度阴影的阶梯
1构建用于“阴影底下的一行”、“阴影x1和白色x2”、“阴影x2和白色x1”的模型,并触发widehat y_1, widehat y_2, 和widehat y_3。
2.构建用于“黑色底下的一行”、“黑色x1和白色x2”、“黑色x2和白色x1”的模型,并触发widehat y_4, widehat y_5, 和widehat y_6。
3.将这些模型组合在一起,然后将结果用一个sigmoid函数进行计算,因此,“黑色”标识符将从“阴影”标识符中去除。
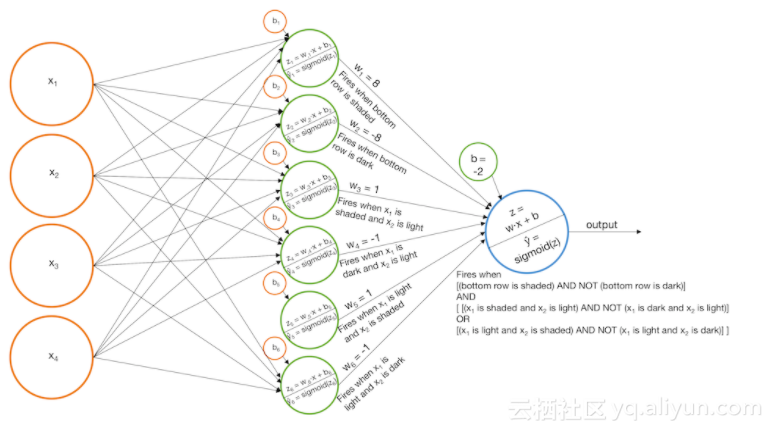

以上就是我们利用“阶梯”模式识别图像而建立的模型,另外我们还需要注意以下两点:
1.注意术语
单层感知器有一个单独的输出层。但是,我们刚刚构建的模型有一个输出层作为另一个输出层的输入层,因此它们将被称为双层感知器。当模型有三层——一个输入层,一个隐藏层,和一个输出层,我们也可以称这些模型为神经网络。
2.选择其它激励函数
在我们的例子中,我们使用了一个sigmoid激励函数。但是,我们也可以使用其他的激励函数,例如tanh函数和relu函数。但是,需要注意的是,激励函数必须是非线性的,否则神经网络将简化为一个等价的单层感知器。
译者注:
人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
以上为译文
文章原标题《Introduction To Neural Networks》译者:黄小凡,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
最后
以上就是明亮鼠标最近收集整理的关于神经网络入门实例的全部内容,更多相关神经网络入门实例内容请搜索靠谱客的其他文章。








发表评论 取消回复