摘要
本文介绍了我们参与的Chinese Grammatical Error Diagnosis (CGED) 2020 shared task。对于检测子任务,我们提出了两种基于BERT的方法:1)使用句法依赖树来增强模型性能,以及2)在多任务学习框架下结合序列标注和序列到序列(seq2seq)模型。对于纠正子任务,我们利用屏蔽语言模型,seq2seq模型和拼写检查模型根据检测结果生成纠正。在检测的识别级别和位置级别,我们获得top-3纠正的最高召回率和第二高的F1分数。
1.介绍
中文已经成为全世界有影响力的语言。越来越多的人选择中文作为第二外语(CSL / CFL)。他们的书写内容通常包含语法错误,包括拼写和搭配错误。例如,日本学习者可以写“我苹果喜欢”,而正确的表达应该是“我喜欢苹果”。中日语法结构的不一致将导致不同的表达顺序。中文的语法结构不同于其他语言,错误的书写方式最终会影响表达内容。
以前特征工程包括预训练特征和解析特征以提高性能。在本文中,我们将BERT的输出表示与语法依存树相结合,并提出了错误检测和纠正的多任务学习。我们采用基于BERT的三种策略根据检测结果进行纠正。实验表明,我们的系统在检测和纠正水平上都是有效的。我们的贡献总结如下:
- 我们提出了基于图卷积网络(基于GCN)的方法,以提高基线模型对语法依存的理解,并引入序列到序列(seq2seq)模型以提高原始序列标注任务的性能。
- 我们结合屏蔽语言模型,seq2seq和中文拼写检查三种方法,根据检测结果纠正错误句子。
- 在检测的识别级别和位置级别,我们获得top-3纠正的最高召回率和第二高的F1分数。
本文的组织如下。第2节介绍了CGED任务。第3节介绍了我们的语法错误检测和纠正系统。第4节报告了通过提出的方法进行的实验结果。第五部分总结了这项工作。
2.中文语法错误检测

CGED的共享任务自2014年以来一直举行。CFL学习者已经发布了几套训练数据,其中包含很多语法错误。为了检测,CGED定义了四种错误类型:(1)R(冗余单词错误);(2)M(丢失单词);(3)W(单词排序错误);(4)S(单词选择错误),如图1所示。性能是在检测级别,识别级别和位置级别下测量的。在进行纠正时,对于缺失和选择错误,要求系统最多提出3个候选纠正。
3.系统描述
3.1 BERT-CRF
以前的工作将检测任务视为通过LSTM-CRF模型解决序列标注问题。我们引入了BERT模型来代替LSTM模型。对于不同的预训练BERT模型,我们选择StructBERT作为我们的主体模型。原因之一是其预训练策略Word Structural Objective接受单词顺序错误的句子,这与该任务中的单词顺序错误相似。
3.2 BERT-GCN-CRF
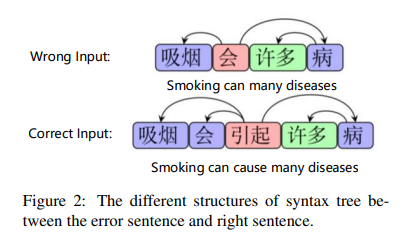
之前的工作在特征工程上花费了大量精力,包括预训练特征和解析特征。词性标注(POS)和依存信息是最重要的解析特征,这向我们表明检测任务与句子语法依存的结构紧密相关。具体来说,冗余错误和缺失错误语句的语法树与正确语句有很大不同,如图2所示。
为了更好地理解输入句子的依存关系结构,我们引入了图卷积网络(GCN)。图3显示了我们的BERT-GCN-CRF模型架构。我们将详细解释每个部分。
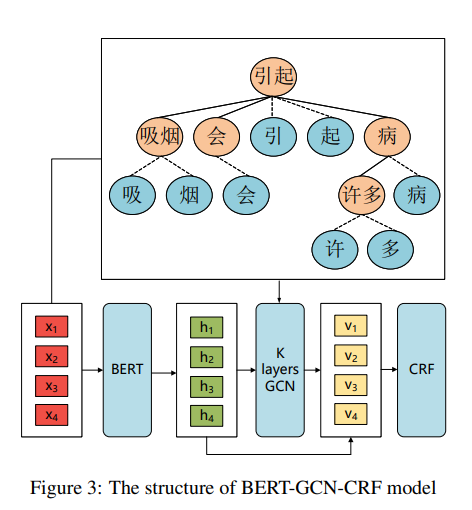
(1)单词依存
我们将输入的句子分为单词,并获得每个单词的依存关系。由于BERT在中文的字符级上训练的,因此我们为单词的所有字符添加了一个额外的单词依存边。
(2)图卷积网络
多层GCN网络接受通过BERT模型获得的高级字符信息以及依存树的邻接矩阵。每层都采用卷积运算。
f
(
A
,
H
l
)
=
A
H
l
W
l
g
(1)
f(A,H^l)=AH_lW^g_ltag{1}
f(A,Hl)=AHlWlg(1)
其中
W
l
g
∈
R
D
×
D
W^g_l∈R^{D×D}
Wlg∈RD×D是第
l
l
l层的可训练矩阵,
A
A
A是依存树的邻接矩阵,
H
l
=
(
h
1
,
h
2
,
.
.
.
,
h
n
)
H_l =(h_1,h_2,...,h_n)
Hl=(h1,h2,...,hn)是字符的隐藏状态。单词在网络中使用相同的输入表示来表示字符的依存关系。
(3)累加输出
在图卷积网络之后,我们将第
l
l
l层的表示
H
l
H_l
Hl和BERT隐藏状态拼接起来传递给线性分类器,作为CRF层的输入。
V
=
L
i
n
e
a
r
(
H
0
⊕
H
l
)
(2)
V=Linear(H_0oplus H_l)tag{2}
V=Linear(H0⊕Hl)(2)
(4)CRF层
引入了CRF层以预测每个字符的序列标签。
S
c
o
r
e
(
X
,
Y
)
=
∑
i
=
0
n
A
y
i
,
y
i
+
1
+
∑
i
=
1
n
V
i
,
y
i
(3)
Score(X,Y)=sum^n_{i=0}A_{y_i,y_{i+1}}+sum^n_{i=1}V_{i,y_i}tag{3}
Score(X,Y)=i=0∑nAyi,yi+1+i=1∑nVi,yi(3)
P
(
Y
∣
X
)
=
e
x
p
(
S
c
o
r
e
(
X
,
Y
)
)
∑
Y
^
e
x
p
(
S
c
o
r
e
(
X
,
Y
^
)
)
(4)
P(Y|X)=frac{exp(Score(X,Y))}{sum_{hat Y}exp(Score(X,hat Y))}tag{4}
P(Y∣X)=∑Y^exp(Score(X,Y^))exp(Score(X,Y))(4)
其中
X
,
Y
,
Y
^
X,Y,hat Y
X,Y,Y^代表输入序列,真实标签序列和任意标签序列,
V
V
V代表标签概率,
A
A
A是CRF层的状态转移矩阵。损失函数的计算公式为:
L
o
s
s
s
l
=
−
l
o
g
(
P
(
Y
∣
X
)
)
(5)
Loss_{sl}=-log(P(Y|X))tag{5}
Losssl=−log(P(Y∣X))(5)
最后,我们使用维特比解码来推理答案。
3.3 Multi-task
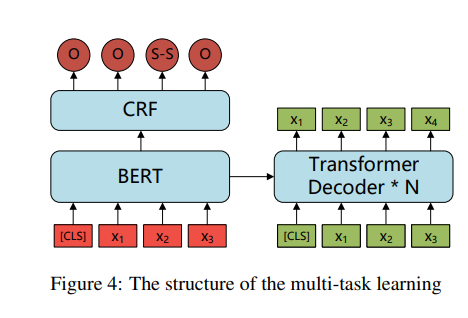
以前的大多数工作都通过序列标注训练他们的模型。在训练过程中,我们不仅利用标签,而且利用正确的句子。正确的句子对于在隐藏状态下提供更好的表示非常重要。此外,使用正确的句子,模型可以更好地理解输入句子的原始含义。因此,我们引入了seq2seq任务,将训练过程视为多任务学习。如图4所示,序列标注模型作为我们结构中的编码器,结合了解码器以预测真假句子。序列标记损失和seq2seq损失由超参数
w
w
w组合:
L
o
s
s
=
w
∗
L
o
s
s
s
l
+
(
1
−
w
)
∗
L
o
s
s
s
e
q
2
s
e
q
(6)
Loss=w*Loss_{sl}+(1-w)*Loss_{seq2seq}tag{6}
Loss=w∗Losssl+(1−w)∗Lossseq2seq(6)
在推理阶段,我们使用序列标注模块来预测答案。
3.4 Ensemble
为了利用来自多个错误检测模型的预测,我们采用了两阶段投票Ensemble机制。
在第一阶段,利用来自多个模型的预测来从语法错误的句子中区分出正确的句子。具体来说,当少于
θ
d
e
t
θ_{det}
θdet模型检测到句子中的错误时,我们将句子标记为正确。
在第二阶段,将编辑级别的投票应用于具有语法错误的句子的预测。我们仅包括出现在超过
θ
e
d
i
t
θ_{edit}
θedit模型的预测中的编辑。
在实验中,我们根据验证集的性能使用网格搜索选择
θ
d
e
t
θ_{det}
θdet和
θ
e
d
i
t
θ_{edit}
θedit。
3.5 纠正
对于选择(S)和丢失(M)错误,我们介绍了两种生成纠正的方法。
在第一种方法中,我们将MASK字符插入句子中,并使用BERT通过以自回归方式逐一替换MASK标记来生成纠正。在实验中,我们插入1到4个MASK令牌来覆盖大多数情况,并采用集束搜索算法来降低搜索复杂度。
在第二种方法中,我们通过将错误的句子映射到正确的句子而训练的seq2seq模型生成候选纠正。根据检测结果,我们继续生成下一个字符,直到正确的字符出现在集束搜索算法中,然后替换不正确的跨度。
3.6 中文拼写检查
中文拼写检查(CSC)模型用于处理拼写错误。我们结合了从CSC数据中学到的基于规则的检查器和基于BERT的拼写检查器的结果。基于规则的检查器擅长处理非单词错误。基于BERT的检查器将CSC任务视为序列标注问题,并且擅长处理实词错误。然后将更正分段并与输入句子对齐,以获取单词级别的编辑结果。由于CSC模型在验证数据上显示出高精度,因此我们将拼写错误视为单词选择错误,并将CSC结果直接合并到最终提交的检测和更正结果中。
最后
以上就是高高睫毛最近收集整理的关于Chinese Grammatical Error Diagnosis with Graph Convolution Network and Multi-task Learning翻译摘要1.介绍2.中文语法错误检测3.系统描述的全部内容,更多相关Chinese内容请搜索靠谱客的其他文章。








发表评论 取消回复