以下文章出自微信公众号:学术头条
文章来源:北京智源人工智能研究院
原文链接:请点击
文章仅用于学习交流,如有侵权请联系删除
导读:深度学习的安全性问题已经逐渐被学术界、工业界所认识到并且重视,就文本领域而言,垃圾邮件检测、有害文本检测、恶意软件查杀等实用系统已经大规模部署了深度学习模型,安全性对于这些系统尤为重要。但相比于图像领域,文本领域对抗攻击的研究还远远不够。特别是文本离散的特点使得对抗样本的生成更具挑战性,也有更多的研究空间。我们欣喜地看到,目前有越来越多的 NLP 研究者开始探索文本对抗攻击这一方向,以 2020 年 ACL 为例,粗略统计有超过 10 篇相关论文,其中最佳论文 Beyond Accuracy: Behavioral Testing of NLP Models with CheckList[23]中大部分测试方法其实和文本对抗攻击有异曲同工之妙。
近年来,随着深度学习的迅速发展,尤其是各种神经网络模型被大规模部署在人脸识别、机器翻译、欺诈检测等实用系统之中,其安全性风险也越来越为人所关注和重视。其中,对抗攻击(Adversarial Attack)[1,2]是目前研究最多的安全性风险。
对抗攻击指的是对目标机器学习模型的原输入施加轻微扰动以生成对抗样本(Adversarial Example)来欺骗目标模型(亦称为受害模型,Victim Model)的过程。对抗攻击可以暴露机器学习模型的脆弱性,进而提高模型的鲁棒性和可解释性,在图像领域已经有广泛的研究[3]。在图 1 所示的例子中,将噪声加到一张原来可被 CNN 图像分类模型正确识别的熊猫图片后,该分类模型错误地识别为长臂猿,尽管人肉眼完全无法分辨加噪声前后两张图片的区别。

文本领域同样有类似的情况。在图 2 所示的例子中,上半部分是一条电影的差评,可以被基于 LSTM 的情感分析模型正确判断其情感倾向为负面,然而如果将其中的某些词做同义替换,如“terrible”替换为“horrific”或“horrifying”,原来的情感分析模型却给出了情感为正面的错误答案。

由于文本离散的特点,相比于图像、声音等连续信号媒介,文本领域的对抗攻击更具挑战性。哪怕是小到一个字的改动也可能会破坏原文本的语法正确性和流畅性,使得产生的对抗样本质量较差。更有甚者对原输入的扰动会引起文本语义的根本性改变——例如,将“这部电影很好看”改为“这部电影很难看”,其情感倾向完全颠倒——而这样的对抗样本是无效的,因为攻击者所预期的情感分析模型的判断发生变化(从“正面”变为“负面”)并不是错误的。
一、文本对抗攻击的分类
图像领域对抗攻击及其防御已被大规模研究(据粗略统计 CVPR 2020 有超过 60 篇相关论文),文本领域对抗攻击的研究近两年才逐渐受到关注。现有的文本对抗攻击可以从以下三个维度进行分类:
(1) 指向性
使受害模型给出指定的错误判断的攻击称为指向性攻击(Targeted Attack),例如使文本分类模型在处理对抗样本时均给出某一特定类的判断;相应地非指向性攻击(Untargeted Attack)则只要求对抗样本使模型判断出错即可。
(2) 受害模型可见性
对抗攻击中,攻击者对受害模型所知多少大有不同。
最理想的情况是攻击者完全掌握受害模型,可以调用受害模型来获取其相对于某一给定输入的输出结果并且知道其内部的所有参数。在这种情况下,攻击者往往可以利用类似梯度下降的优化方法来调整扰动进而产生对抗样本。这样的设定称为白盒(White-Box)设定,相应的对抗攻击被称为基于梯度的攻击(Gradient-Based Attack)。
和白盒设定相对的是黑盒(Black-Box)设定,在这种设定下,攻击者无法得知受害模型的内部结构及参数,仅仅可以调用受害模型来获取其相对于给定输入的输出结果。根据输出结果的类型,黑盒攻击可以细分为基于分数(Score-Based)和基于决定(Decision-Based)的攻击——前者可以得知受害模型最终的输出分数(如分类模型的各类的概率),后者只能知道受害模型给出的判断结果(如分类模型给出的类别)。
此外,攻击者甚至可能无法调用受害模型,在没有任何关于受害模型信息的情况下进行攻击。这种攻击被称为盲攻击(Blind Attack)。
纵观以上四种不同的攻击,基于梯度的攻击对受害模型可见性要求太高,真实的攻击场景中往往并不可行;盲攻击由于已知信息太少,攻击效果往往很差;相比之下,基于分数和基于决定的攻击既符合真实的攻击设定又有足够的已知信息来有效进行攻击,因此目前大多数文本对抗攻击是这两种类型,尤其是基于分数的攻击。(3) 扰动粒度
对抗攻击还可以从扰动产生的粒度分为句级、词级以及字级攻击。
句级攻击将整句原始输入视作扰动的对象,意图产生一个和原始输入语义相同(至少针对当前任务的真实标签不改变)但却使得受害模型判断改变的对抗样本。常用的句级攻击方法包括改述(Paraphrasing)[4,5]、编码后重新解码[6]、添加无关句子[7]等。
词级攻击扰动的对象是原始输入中的词,最主要方法为词替换。替换词的选择有多种多样,包括基于词向量相似度[8,9]、同义词[10]、义原[11]、语言模型分数[12]等词替换方法。此外也有研究尝试添加或删除词[13],但是这样做往往会影响所生成的对抗样本的语法性、通顺性。
字级攻击主要对原始输入中的字符进行扰动,常用的方法包括字符的添加、删除、替换、交换顺序等,具体到字替换而言,有随机替换[14]、基于One-Hot编码的字替换[15]以及基于字形相似的替换[16]等。
此外,有的攻击方法也会同时进行词级和字级扰动[17]。
对比以上三种不同粒度的扰动,句级的扰动往往使得对抗样本和原始输入之间有巨大的差别,很难控制所产生的对抗样本的质量,更无法保证其有效性(即具有和原始输入相同的真实标签),而且从实验结果看攻击效果也比较一般;字级扰动所产生的对抗样本质量往往很差,大概率会破坏其语法性,造成对抗样本不可读,尽管攻击成功率较高,但是目前有一些基于语法纠错的防御方法可以很好地应对字级的攻击[18]。
相比之下,词级攻击在对抗样本质量和有效性控制以及攻击成功率方面有更好的表现。就对抗样本质量和有效性控制而言,一般对一句话中某些词进行同义替换很难改变这句话的语义,再加上利用语言模型进行控制,所产生的对抗样本的通顺性、流畅性也更容易保证。就攻击成功率而言,白盒设定下基于梯度的攻击方法往往可以最快地找到合适的被替换词和替换词,一般而言有较高的攻击成功率;即使在黑盒设定下,现有的词级攻击方法利用受害模型的反馈(即针对一次词级扰动后产生的准对抗样本的输出),迭代地进行词替换操作,最终也有较高的攻击成功率。例如,目前最先进的基于义原+离散粒子群优化的词级攻击在 IMDB 数据集上攻击 BiLSTM 时可以达到 100% 的成功率[11]。
接下来,我们对现有的词级文本对抗攻击进行简单的梳理。
二、词级别文本对抗攻击
[11]提出,词级文本对抗攻击本质上是一个组合优化(Combinatorial Optimization)问题。所谓组合优化就是在有限个可行解的集合中找出最优解的优化问题。对于词级文本对抗攻击,在词表有限的情况下,词级扰动也是有限的,而攻击的目标则是找出一个能够成功攻击受害模型的对抗样本——即最优解。当然,成功攻击受害模型的对抗样本可能不止一个,一般而言找到一个即可结束
[11]进一步提出词级文本对抗攻击这个组合优化问题可以拆解为两步:(1)搜索空间缩减;(2)对抗样本搜索。所谓搜索空间缩减,本质上其实就是确定原始输入中每个词的候选替换词集合,每个位置的候选替换词加上原始词构成的集合的组合张成了一个离散的空间——每个位置对应空间的一个维度,每个位置的候选替换词+原始词的集合为该维的可行集。例如,图 3 中原始输入“I love this movie”有 4 个词,则对应的对抗样本搜索空间为 4 维,第一维对应第一个词“I”,因其没有候选替换词,所以该维仅有 1 个可行点;第二维对应第二个词“love”,有“like”和“enjoy”2 个候选替换词,所以该维一共 3 个可行点……以此类推可以得到“I love this movie”的对抗样本搜索空间。这一步之所以称为“对抗样本缩减”,是考虑到有些对抗攻击方法根本不确定每个词的候选替换词集,而是将整个词表的所有词视作潜在的可选替换词。
第(2)步则是在第(1)步得到的缩减后的离散组合空间中搜索可以成功攻击受害模型的对抗样本。
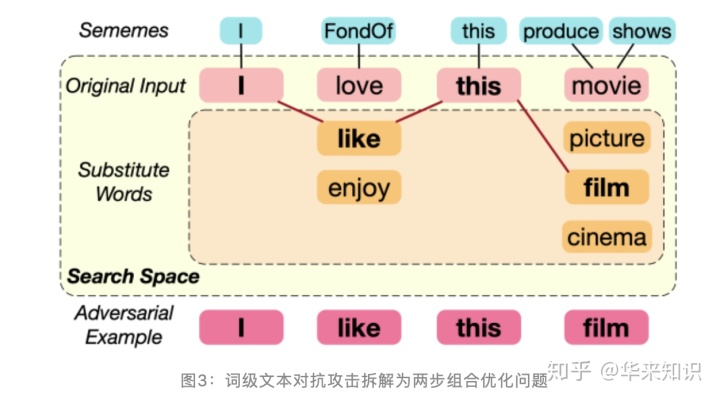
现有的所有词级对抗攻击方法都可以在上述框架下进行拆解。具体而言,第(1)步搜索空间缩减,目前主要方法为前面提到的基于词向量[8,9]或者同义词[10]的词替换方法,当然也有攻击方法跳过这一步不进行搜索空间缩减[19]。第(2)步对抗样本搜索,目前有梯度下降[15,19]、遗传算法[8]、基于词显著度的贪心算法[9,10]、Metropolis-Hastings 采样方法[12]等。
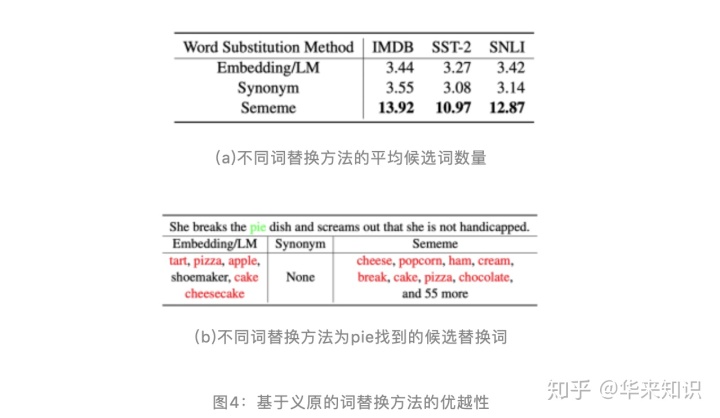
[11]在上述框架下,对两步分别进行了改进,并且最终达到了当前最好(state-of-the-art)的攻击效果。在第一步,他们使用了基于义原(sememe)的词替换方法。在语言学中,义原是最小的语义单位,一个词的语义可以认为由其所有义原来表达[20]。实验表明,基于义原的词替换方法能够找到更多合适的候选替换词,和基于同义词或基于词向量的词替换方法相比有显著的优越性,如图 4 所示。
在第二步,他们提出了基于离散粒子群优化(Discrete Particle Swarm Optimization)的对抗样本搜索算法。粒子群优化[21]是一种典型的组合优化算法,之前实证研究表明它比包括遗传算法在内的其他组合优化算法更加高效[22]。
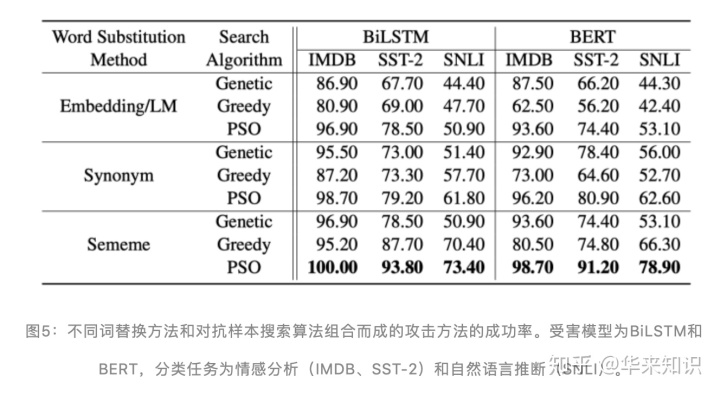
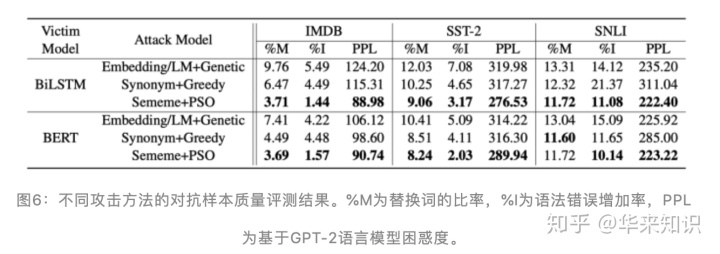
他们通过大量的实验证明了基于义原的词替换方法和基于离散粒子群优化的对抗样本搜索算法分别比相应的其他方法有更好的攻击效果,并且就对抗样本质量、攻击有效性而言也有更好或相当的表现,如图 5、图 6 所示。
三、文本对抗攻击相关资源
1. 文本对抗攻击阅读列表
清华大学自然语言处理与社会人文计算实验室(THUNLP)建立的TAADpapers(https://github.com/thunlp/TAADpapers)是不可多得的全面、系统的文本对抗领域的阅读列表。该列表包含工具包、综述、文本对抗攻击、文本对抗防御、模型鲁棒性验证、基准和评估、其他六个部分,基本上涵盖了所有的文本对抗攻防领域的已发表论文。其中攻击部分的论文进一步分成了句级、词级、字级、混合四个子部分,并且还为每篇论文打上了受害模型可见性的标签:gradient/score/decision/blind。除了提供论文 pdf 链接之外,如果某篇论文有公开代码或数据,也会附上相应的链接。目前该列表共有 65 篇论文。

2. 文本对抗攻击工具包
在图像领域有 CleverHans、Foolbox、Adversarial Robustness Toolbox (ART)等多个对抗攻击工具包。这些工具包将图像领域的对抗攻击模型整合在一起,大大减少了模型复现的时间和难度,提高了模型评测的标准化程度,有力推动了图像领域对抗攻击的发展。
经笔者调研,目前仅有 TextAttack 和 OpenAttack 这两个文本对抗工具包。两者均包含了一些现有的文本对抗攻击方法,下载方便,简单易用。其中 TextAttack 构建时间更早,由弗吉尼亚大学祁妍军教授领导的 Qdata 实验室开发(项目主页:https://github.com/QData/TextAttack)。而 OpenAttack 构建时间较晚,由清华大学自然语言处理与社会人文计算实验室开发(项目主页:https://github.com/thunlp/OpenAttack)。具体而言,TextAttack 主要支持基于梯度和基于分数的攻击,以及词/字级扰动,而 OpenAttack 则覆盖了所有类型的攻击,包括基于决定的攻击和盲攻击以及句级的扰动。此外,OpenAttack 也有相对而言更好的可扩展性,用户在攻击自己的模型或者设计新的攻击模型时有更大的自由度和更好的可实现性。
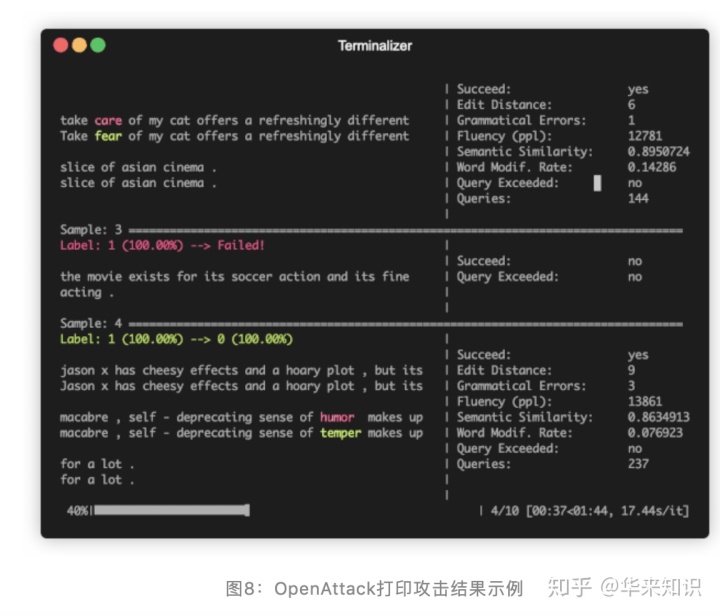
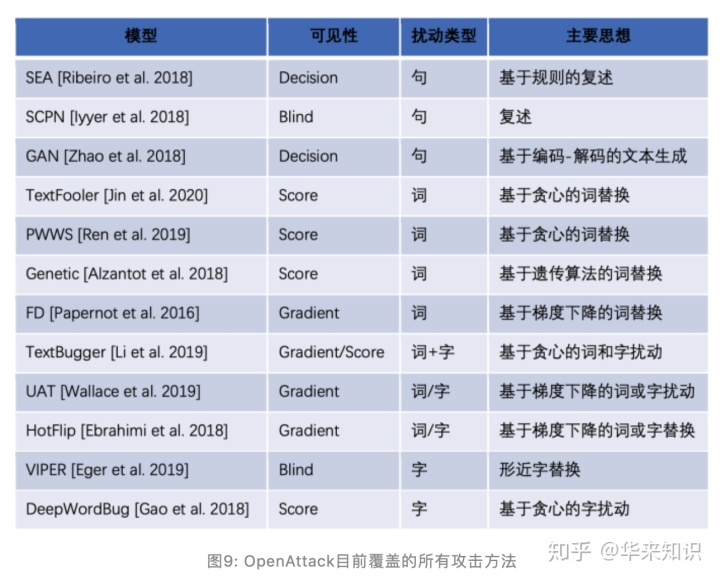
图 8 展示了使用 OpenAttack 进行对抗攻击时打印攻击结果的样例,可以看到OpenAttack能够实时输出攻击每一个原始输入的结果,包括成功与否、受害模型访问次数、对抗样本各项质量评估指标等,针对所有原始输入攻击结束后,还会打印一个攻击结果总结表,列出整体的各项攻击评价指标。图 9 列出了 OpenAttack 目前支持的所有攻击方法。在 OpenAttack 的 GitHub 项目主页也给出了一些基本的用例,更详细的可以参看其文档和源码。
这类文本对抗攻击工具包有丰富的应用场景,包括提供现成的对抗攻击基线模型、针对文本对抗的全面的评测、辅助设计新的攻击模型、评测自己模型的鲁棒性、进行对抗训练等等。相信它们会像图像领域的对抗攻击工具包一样,极大地推进文本对抗攻击领域的发展。
作者:岂凡超,清华大学计算机系博士,导师为孙茂松教授,主要研究方向为自然语言处理,其研究工作曾在 EMNLP 等发表。
参考文献
[1] Intriguing properties of neural networks. Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fergus. ICLR 2014.
[2] Ian J Goodfellow, Jonathon Shlens, Christian Szegedy. 2015. Explaining and harnessing adversarial examples. In Proceedings of ICLR.
[3] Adversarial attacks and defences: A survey. Anirban Chakraborty, Manaar Alam, Vishal Dey, Anupam Chattopadhyay, Debdeep Mukhopadhyay. arXiv 2018.
[4] Semantically Equivalent Adversarial Rules for Debugging NLP Models. Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin. ACL 2018.
[5] Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Mohit Iyyer, John Wieting, Kevin Gimpel, Luke Zettlemoyer. NAACL-HLT 2018.
[6] Generating Natural Adversarial Examples. Zhengli Zhao, Dheeru Dua, Sameer Singh. ICLR 2018.
[7] Adversarial Examples for Evaluating Reading Comprehension Systems. Robin Jia, and Percy Liang. EMNLP 2017.
[8] Generating Natural Language Adversarial Examples. Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang. EMNLP 2018.
[9] Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. Di Jin, Zhijing Jin, Joey Tianyi Zhou, Peter Szolovits. AAAI-20.
[10] Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. Shuhuai Ren, Yihe Deng, Kun He, Wanxiang Che. ACL 2019.
[11] Word-level Textual Adversarial Attacking as Combinatorial Optimization. Yuan Zang, Fanchao Qi, Chenghao Yang, Zhiyuan Liu, Meng Zhang, Qun Liu, Maosong Sun. ACL 2020.
[12] Generating Fluent Adversarial Examples for Natural Languages. Huangzhao Zhang, Hao Zhou, Ning Miao, Lei Li. ACL 2019.
[13] Deep Text Classification Can be Fooled. Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li, Wenchang Shi. IJCAI 2018.
[14] Synthetic and Natural Noise Both Break Neural Machine Translation. Yonatan Belinkov, Yonatan Bisk. ICLR 2018.
[15] HotFlip: White-Box Adversarial Examples for Text Classification. Javid Ebrahimi, Anyi Rao, Daniel Lowd, Dejing Dou. ACL 2018.
[16] Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems. Steffen Eger, Gözde Gül ¸Sahin, Andreas Rücklé, Ji-Ung Lee, Claudia Schulz, Mohsen Mesgar, Krishnkant Swarnkar, Edwin Simpson, Iryna Gurevych. NAACL-HLT 2019.
[17] TEXTBUGGER: Generating Adversarial Text Against Real-world Applications. Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, Ting Wang. NDSS 2019.
[18] Combating Adversarial Misspellings with Robust Word Recognition. Danish Pruthi, Bhuwan Dhingra, Zachary C. Lipton. ACL 2019.
[19] Crafting Adversarial Input Sequences For Recurrent Neural Networks. Nicolas Papernot, Patrick McDaniel, Ananthram Swami, Richard Harang. MILCOM 2016.
[20] HowNet and the computation of meaning. Zhendong Dong, Qiang Dong. 2006.
[21] Particle swarm optimization. Russell Eberhart, James Kennedy. IEEE International Conference on Neural Networks 1995.
[22] A comparison of particle swarm optimization and the genetic algorithm. Rania Hassan, Babak Cohanim, Olivier De Weck, Gerhard Venter. 46th AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference 2005.
[23] Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh. ACL 2020.

「华来知识」成立于2017年,孵化于清华大学智能技术与系统国家重点实验室,是一家技术领先的人工智能企业。公司专注于提供新一代人工智能人机交互解决方案,利用自身技术为企业打造由人工智能驱动的知识体系,借此改善人类生活。「华来知识」将持续为企业客户提供优质服务,助力企业在专业领域的人工智能应用,提供完善可靠高效的产品解决方案。
最后
以上就是心灵美高跟鞋最近收集整理的关于lstm 文本纠错_一文尽览!文本对抗攻击基础、前沿及相关资源的全部内容,更多相关lstm内容请搜索靠谱客的其他文章。








发表评论 取消回复