中文拼写检测(Chinese Spelling Checking)相关方法、评测任务、榜单
中文拼写检测(Chinese Spelling Checking,CSC)是近两年来比较火的小众任务,在包括ACL、EMNLP等顶会上发展迅速。本文简单介绍CSC任务,相关方法、评测任务和榜单。
一、中文拼写检测
中文拼写检测(Chinese Spelling Checking,CSC)又称中文拼写纠错(Chinese Spelling Correction,CSC),其旨在根据上下文来识别并纠正错误的拼写问题,起源于英文的拼写检测和语法错误识别问题。由于近年来中文NLP的发展加速,包括中文文本挖掘、中文预训练语言模型等,诸多中文语料或垂直领域语料中都会存在的一些拼写错误问题,因此提升语料质量十分重要。
目前中文拼写检测常用在如下三个场景中:
- OCR识别:是指对图像类型的文字通过CV算法转换为UTF-8的字符。但是由于OCR属于单字独立识别,可能由于图像模糊、遮盖等问题导致识别出错,因此OCR识别出的文本可能会存在拼写错误问题。一般地,OCR属于视觉特征方面的文字识别任务,因此拼写错误通常来源于相似字形混淆。
例如“金属材料”可能会被错误识别为“金属材科”,因为“科”与“料”在字形上非常相似。
- ASR识别:是指根据语音来转换为文字,属于语音识别。通常也会因为杂音、方言等问题,部分音节存在相似混淆而导致识别错误。
例如“星星产业”与“新兴产业”,“星星”与“新星”如果在说话者咬字不清晰的情况下是很难区分的。
- 意外错误:例如工作人员在键入信息时,可能由于敲错键盘等马虎行为,导致输入了错误的字符。
例如在输入“伤感”(shanggan)时,可能会误输入为“伤寒”(shanghan),因为“g”和“h”在键盘布局内仅靠在一起;
但是最终我们期望识别的文本在上下文是存在语义的,由于一些错误的拼写,我们依然可以判断他原始的正确字符。例如即便OCR错误识别为“金属材科”,我们依然可以根据上下文与先验知识来推测应为“金属材料”。当然也有可能是由于不同领域的问题,使得这个纠错任务并非完全依靠上下文。例如常见的搭配是“新兴产业”,但是不得排除“星星产业”是某一个商标或特定领域专有词汇。
因此,学术界引入中文拼写检测(CSC)来专门也就如何识别并纠错。在数据的构建上,可以直接根据混淆集来生成错误字符,而混淆集的构建则需要专门处理,如下图所示,可以针对对图像进行模糊化处理来生成错误的字符:
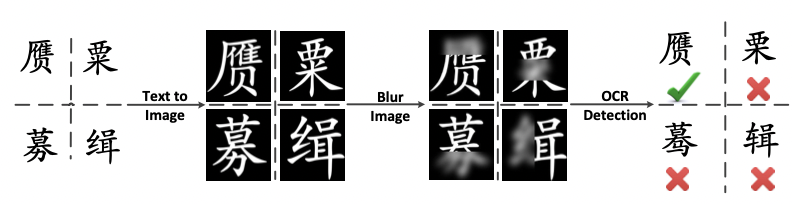
下面给出CSC基础概念:
- 混淆集(Confusion Set):是指一系列存在字音字形相似的字符集合,例如“自”与“白”、“曰”存在字形混淆。在预测时,通常根据混淆集来召回可能的字符,再根据上下文预测正确的字符;
- 字形特征(Glyphic Feature):通常表示一个汉字的偏旁部首(结构特征)和笔画序列(序列特征),例如:“争”的结构特征可以描述为“⿱⿰⿻⿻⿱”,序列特征为“丿㇇????一一亅”
偏旁部首和笔画通常也可以描述为树形结构,如图所示:
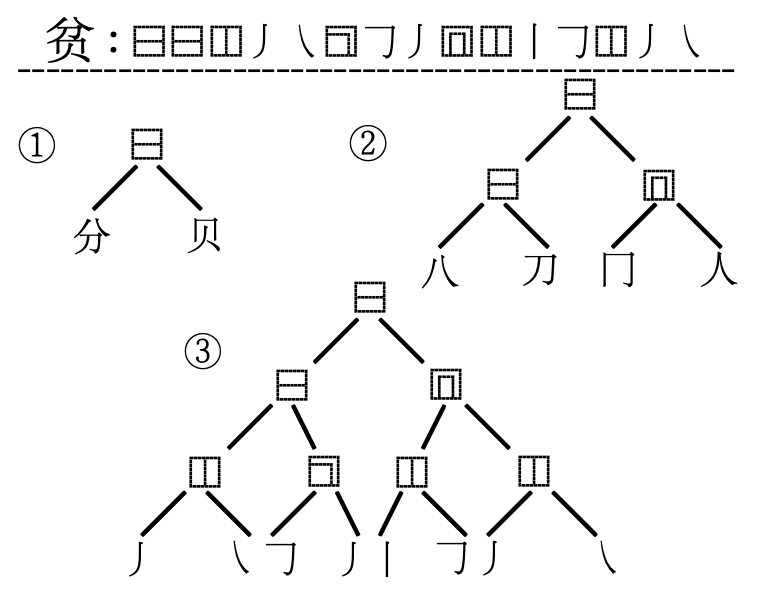
- 字音特征(Phonetic Feature):通常表示一个字符的拼音(pinyin),例如“天”的pinyin序列为“tian1”,“盛”的pinyin序列可能为“sheng4”、“cheng2”(其中数字部分表示声调)。在特征提取时,通常可以将pinyin单独作为一个特征,或将pinyin作为一个序列进行处理。
二、相关方法
本部分简单列出最近相关论文(会不定时更新,如有最新稿件,可在评论区提供),如下所示:
【1】DCSpell:A Detector-Corrector Framework for Chinese Spelling Error Correction(SIGIR2021)
【2】Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction(ACL2021)
【3】Correcting Chinese Spelling Errors with Phonetic Pre-training(ACL2021)
【4】PLOME:Pre-trained with Misspelled Knowledge for Chinese Spelling Correction(ACL2021)
【5】PHMOSpell:Phonological and Morphological Knowledge Guided Chinese Spelling Check(ACL2021)
【6】Exploration and Exploitation: Two Ways to Improve Chinese Spelling Correction Models(ACL2021)
【7】Dynamic Connected Networks for Chinese Spelling Check(2021ACL)
【8】Global Attention Decoder for Chinese Spelling Error Correction(ACL2021)
【9】Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking(ACL2021)
【10】SpellBERT: A Lightweight Pretrained Model for Chinese Spelling Check(EMNLP2021)
【11】A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check(EMNLP2018)
【12】Adversarial Semantic Decoupling for Recognizing Open-Vocabulary Slots(EMNLP2020)
【13】Chunk-based Chinese Spelling Check with Global Optimization(EMNLP2020)
【14】Confusionset-guided Pointer Networks for Chinese Spelling Check(ACL2019)
【15】Context-Sensitive Malicious Spelling Error Correction(WWW2019)
【16】FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm (2019ACL)
【17】SpellGCN:Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check (2020ACL)
【18】Spelling Error Correction with Soft-Masked BERT(ACL2020)
在OpenReview上提交至ARR2022的相关稿件有:
【1】Exploring and Adapting Chinese GPT to Pinyin Input Method 【PDF】
【2】The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking 【PDF】【Code】【Data】
【3】Sparsity Regularization for Chinese Spelling Check【PDF】
【4】Pre-Training with Syntactic Structure Prediction for Chinese Semantic Error Recognition【PDF】
【5】ECSpellUD: Zero-shot Domain Adaptive Chinese Spelling Check with User Dictionary【PDF】
【6】SpelLM: Augmenting Chinese Spell Check Using Input Salience【PDF】【Code】【Data】
【7】Pinyin-bert: A new solution to Chinese pinyin to character conversion task【PDF】
简单总结一下目前CSC的方法:
- 基于BERT:以为CSC时是基于token(字符)级别的预测任务,输入输出序列长度一致,因此非常类似预训练语言模型的Masked Language Modeling(MLM),因此现如今绝大多数的方法是基于MLM实现的。而在BERT问世前,CSC则以RNN+Decoder、CRF为主;
- 多模态融合:上文提到CSC涉及到字音字形,因此有一些方法则是考虑如何将Word Embedding、Glyphic Embedding和Phonetic Embedding进行结合,因此涌现出一些多模态方法;
三、评测任务
CSC常用的三个评测数据分别如下:
- SIGHAN Bake-off 2013: http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html
- SIGHAN Bake-off 2014: http://ir.itc.ntnu.edu.tw/lre/clp14csc.html
- SIGHAN Bake-off 2015: http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html
现如今大多数的CSC方法均涉及到预训练环节,常用的预训练语料为
- Wang271K: https://github.com/wdimmy/Automatic-Corpus-Generation
评测数据和训练语料的数据分布情况如图所示:
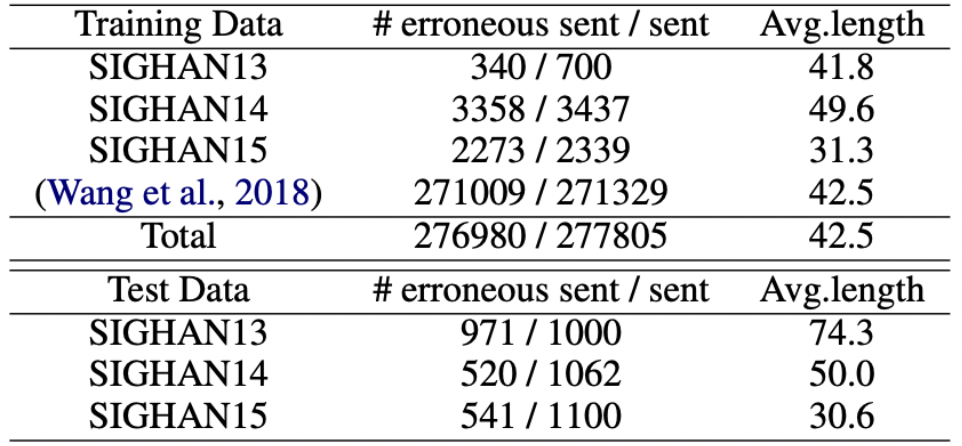
具体的实验细节可以总结如下:
(1)Pre-training语料
语料:nlp_chinese_corpus,随机挑选1M训练,max_len=128,batch_size=1024,lr=5e-5,step=10K。
获取《A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check》构建的271K语料
(2)fine-tuning语料
SIGHAN13、SIGHAN14、SIGHAN15
直接使用SpellGCN提供的数据,其中:
● merged:表示SIGHAN13、SIGHAN14和SIGHAN15混合训练集(10K):
● SIGHAN13、SIGHAN14、SIGHAN15:分别表示测试集
OCR
使用《FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm》构建的数据集:FASPell,总共4575句子
(3)评测脚本:详见本文末
四、榜单
博主简单列出了常用的评测任务上的榜单(实时更新),如下表:
SIGHAN13:https://www.yuque.com/wangjianing-jrsey/aagb95/vw4c3o?inner=XxC0h
SIGHAN14:https://www.yuque.com/wangjianing-jrsey/aagb95/vw4c3o?inner=nBQFV
SIGHAN15:https://www.yuque.com/wangjianing-jrsey/aagb95/vw4c3o?inner=yce4c
五、评测脚本
CSC常采用P、R、F1值进行评测,评测涉及到detection和correction两个层面,具体详见代码:
import os
import sys
def convert_from_myformat_to_sighan(input_path, output_path, pred_path, orig_path=None, spellgcn=False):
with open(pred_path, "w") as labels_writer:
with open(input_path, "r") as org_file, open(orig_path, "r") as id_f:
with open(output_path, "r") as test_file:
test_file = test_file.readlines()
org_file = org_file.readlines()
print(len(test_file), len(org_file))
assert len(test_file) == len(org_file)
for k, (pred, inp, sid) in enumerate(zip(test_file, org_file, id_f)):
if spellgcn:
_, atl = inp.strip().split("t")
atl = atl.split(" ")[1:]
pred = pred.split(" ")[1:len(atl)+1]
else:
atl, _, _= inp.strip().split("t")[:3]
atl = atl.split(" ")
pred = pred.split(" ")[:len(atl)]
output_list = [sid.split()[0]]
for i, (pt, at) in enumerate(zip(pred[:], atl[:])):
if at == "[SEP]" or at == '[PAD]':
break
# Post preprocess with unsupervised methods,
#because unsup BERT always predict punchuation at 1st pos
if i == 0:
if pt == "。" or pt == ",":
continue
if pt.startswith("##"):
pt = pt.lstrip("##")
if at.startswith("##"):
at = at.lstrip("##")
if pt != at:
output_list.append(str(i+1))
output_list.append(pt)
if len(output_list) == 1:
output_list.append("0")
labels_writer.write(", ".join(output_list) + "n")
def eval_spell(truth_path, pred_path, with_error=True):
#Compute F1-score
detect_TP, detect_FP, detect_FN = 0, 0, 0
correct_TP, correct_FP, correct_FN = 0, 0, 0
detect_sent_TP, sent_P, sent_N, correct_sent_TP = 0, 0, 0, 0
dc_TP, dc_FP, dc_FN = 0, 0, 0
for idx, (pred, actual) in enumerate(zip(open(pred_path, "r", encoding='utf-8'),
open(truth_path, "r", encoding='utf-8') if with_error else
open(truth_path, "r", encoding='utf-8'))):
pred_tokens = pred.strip().split(" ")
actual_tokens = actual.strip().split(" ")
#assert pred_tokens[0] == actual_tokens[0]
pred_tokens = pred_tokens[1:]
actual_tokens = actual_tokens[1:]
detect_actual_tokens = [int(actual_token.strip(","))
for i,actual_token in enumerate(actual_tokens) if i%2 ==0]
correct_actual_tokens = [actual_token.strip(",")
for i,actual_token in enumerate(actual_tokens) if i%2 ==1]
detect_pred_tokens = [int(pred_token.strip(","))
for i,pred_token in enumerate(pred_tokens) if i%2 ==0]
_correct_pred_tokens = [pred_token.strip(",")
for i,pred_token in enumerate(pred_tokens) if i%2 ==1]
# Postpreprocess for ACL2019 csc paper which only deal with last detect positions in test data.
# If we wanna follow the ACL2019 csc paper, we should take the detect_pred_tokens to:
max_detect_pred_tokens = detect_pred_tokens
correct_pred_zip = zip(detect_pred_tokens, _correct_pred_tokens)
correct_actual_zip = zip(detect_actual_tokens, correct_actual_tokens)
if detect_pred_tokens[0] != 0:
sent_P += 1
if sorted(correct_pred_zip) == sorted(correct_actual_zip):
correct_sent_TP += 1
if detect_actual_tokens[0] != 0:
if sorted(detect_actual_tokens) == sorted(detect_pred_tokens):
detect_sent_TP += 1
sent_N += 1
if detect_actual_tokens[0]!=0:
detect_TP += len(set(max_detect_pred_tokens) & set(detect_actual_tokens))
detect_FN += len(set(detect_actual_tokens) - set(max_detect_pred_tokens))
detect_FP += len(set(max_detect_pred_tokens) - set(detect_actual_tokens))
correct_pred_tokens = []
#Only check the correct postion's tokens
for dpt, cpt in zip(detect_pred_tokens, _correct_pred_tokens):
if dpt in detect_actual_tokens:
correct_pred_tokens.append((dpt,cpt))
correct_TP += len(set(correct_pred_tokens) & set(zip(detect_actual_tokens,correct_actual_tokens)))
correct_FP += len(set(correct_pred_tokens) - set(zip(detect_actual_tokens,correct_actual_tokens)))
correct_FN += len(set(zip(detect_actual_tokens,correct_actual_tokens)) - set(correct_pred_tokens))
# Caluate the correction level which depend on predictive detection of BERT
dc_pred_tokens = zip(detect_pred_tokens, _correct_pred_tokens)
dc_actual_tokens = zip(detect_actual_tokens, correct_actual_tokens)
dc_TP += len(set(dc_pred_tokens) & set(dc_actual_tokens))
dc_FP += len(set(dc_pred_tokens) - set(dc_actual_tokens))
dc_FN += len(set(dc_actual_tokens) - set(dc_pred_tokens))
detect_precision = detect_TP * 1.0 / (detect_TP + detect_FP)
detect_recall = detect_TP * 1.0 / (detect_TP + detect_FN)
detect_F1 = 2. * detect_precision * detect_recall/ ((detect_precision + detect_recall) + 1e-8)
correct_precision = correct_TP * 1.0 / (correct_TP + correct_FP)
correct_recall = correct_TP * 1.0 / (correct_TP + correct_FN)
correct_F1 = 2. * correct_precision * correct_recall/ ((correct_precision + correct_recall) + 1e-8)
dc_precision = dc_TP * 1.0 / (dc_TP + dc_FP + 1e-8)
dc_recall = dc_TP * 1.0 / (dc_TP + dc_FN + 1e-8)
dc_F1 = 2. * dc_precision * dc_recall/ (dc_precision + dc_recall + 1e-8)
if with_error:
#Token-level metrics
print("detect_precision=%f, detect_recall=%f, detect_Fscore=%f" %(detect_precision, detect_recall, detect_F1))
print("correct_precision=%f, correct_recall=%f, correct_Fscore=%f" %(correct_precision, correct_recall, correct_F1))
print("dc_joint_precision=%f, dc_joint_recall=%f, dc_joint_Fscore=%f" %(dc_precision, dc_recall, dc_F1))
detect_sent_precision = detect_sent_TP * 1.0 / (sent_P)
detect_sent_recall = detect_sent_TP * 1.0 / (sent_N)
detect_sent_F1 = 2. * detect_sent_precision * detect_sent_recall/ ((detect_sent_precision + detect_sent_recall) + 1e-8)
correct_sent_precision = correct_sent_TP * 1.0 / (sent_P)
correct_sent_recall = correct_sent_TP * 1.0 / (sent_N)
correct_sent_F1 = 2. * correct_sent_precision * correct_sent_recall/ ((correct_sent_precision + correct_sent_recall) + 1e-8)
if not with_error:
#Sentence-level metrics
print("detect_sent_precision=%f, detect_sent_recall=%f, detect_Fscore=%f" %(detect_sent_precision, detect_sent_recall, detect_sent_F1))
print("correct_sent_precision=%f, correct_sent_recall=%f, correct_Fscore=%f" %(correct_sent_precision, correct_sent_recall, correct_sent_F1))
if __name__ == '__main__':
output_path = sys.argv[1]
data_path = sys.argv[2]
input_path = os.path.join(data_path, "test_format.txt")
pred_path = os.path.join(os.path.dirname(output_path), 'pred_result.txt')
orig_input_path = os.path.join(data_path, "TestInput.txt")
orig_truth_path = os.path.join(data_path, "TestTruth.txt")
convert_from_myformat_to_sighan(input_path, output_path, pred_path, orig_truth_path, spellgcn=False)
eval_spell(orig_truth_path, pred_path, with_error=False)
最后
以上就是危机鸡最近收集整理的关于中文拼写检测(Chinese Spelling Checking)相关方法、评测任务、榜单中文拼写检测(Chinese Spelling Checking)相关方法、评测任务、榜单的全部内容,更多相关中文拼写检测(Chinese内容请搜索靠谱客的其他文章。








发表评论 取消回复