hive是大数据结构化的查询工具,之前一直使用cli客户端连接hive集群进行SQL存储过程代码的测试。
总体上来看,其实Java通过JDBC访问hive跟使用JDBC访问MySQL和Oracle的代码结构基本雷同。区别在于通过JDBC访问hive访问时,查询性能比较慢,千万级别的表测试查询速度,随机查询10条数据,需要10秒,第一次加载需要30秒以上,如果是条件查询则超过5分钟,复杂查询会有查询超时报错。
JDBC方式适合数量在十万以下的表查询,而且不适合复杂的条件查询、关联查询。
JDK版本:1.8
hive版本:0.13
hadoop版本:2.52
集群元数据库MySQL库的版本貌似是5.1,这个其实不影响。
以下为示例代码:
package com.java.linkhive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import org.apache.hadoop.conf.Configuration;
public class hiveTestCase {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
//hive是不支持insert into...values(....)这种操作的
String querySQLTest = "select order_no from order_bill limit 10";
//建立连接对象
Connection con = DriverManager.getConnection("jdbc:hive2://192.XXX.XXX.XXX:10000/DB_AA", "ETL_AA", "ETLABC");
Statement stmt = con.createStatement();
stmt.executeQuery(querySQLTest);
// 执行查询语句
ResultSet res = stmt.executeQuery(querySQLTest);
//输出查询结果
int i=1;
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
以下为输出结果(log4j是java的一个标准日志输出包):
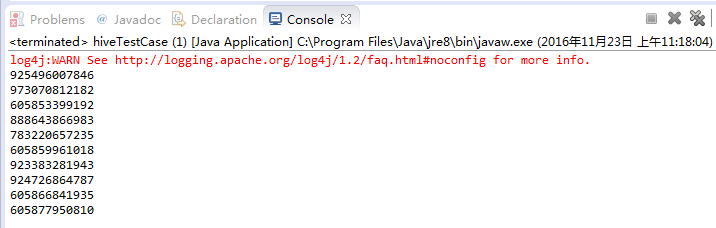
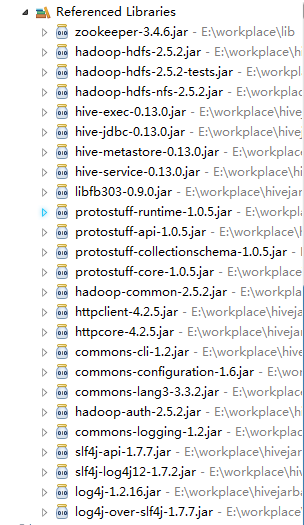
其实代码上并没有什么难度,主要问题出在jar加载上,由于jar包的缺失导致了代码无法执行,下面是经过N次尝试后,得出的编写Java通过JDBC方式连接hive集群时所需要的Jar包:
最后
以上就是顺利柚子最近收集整理的关于通过JDBC访问hive集群的全部内容,更多相关通过JDBC访问hive集群内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复