声明:本文来自于微信公众号 AI新榜,作者:阿虎 月山橘,授权热心网友转载发布。
谁能想到,o1刚出来工作,就被吐槽“懒惰”。
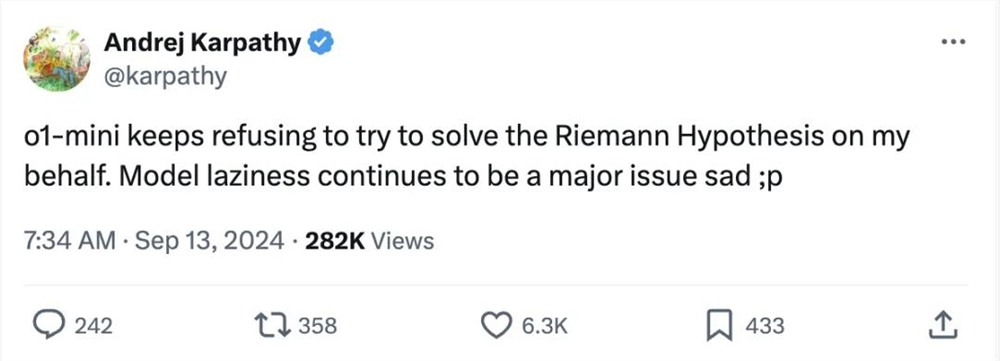
9月13日,OpenAI创始成员、AI大牛Andrej Karpathy发文吐槽OpenAI刚发布的最新模型:“o1-mini一直拒绝为我解决黎曼猜想,模型懒惰还是主要问题,很悲伤。”
9月13日凌晨,OpenAI突然发布了一款o1-preview模型,这也是之前被大肆宣扬的“Strawberry(草莓)”模型。据介绍,该模型能够推理复杂任务,解决科学、编程、数学等领域更难的问题。
与此同时,另一款更小、更高效、成本更低的版本o1mini也同步上线。
除了o1-mini,OpenAI今天还发布了另一款新模型:o1-preview。也就是这段时间吊足了胃口的“Strawberry(草莓)”模型。据介绍,该模型能够推理复杂任务,解决科学、编程、数学等领域更难的问题。
相较而言,o1mini则是更小、更高效、成本更低的版本。
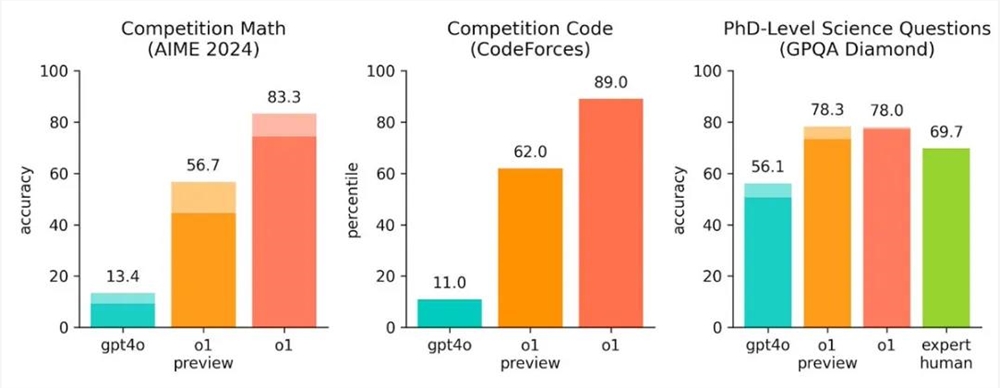
在性能上,o1系列模型主要通过强化学习的方式训练,幻觉频率上低于GPT-4o,数学能力提升了6倍,代码能力提升了8倍。
在一系列高难度基准测试中,o1都展现出了超强实力,甚至能在物理、生物等领域问答环节中,超过人类博士水平。
模型一经上线,OpenAI CEO Sam Altman在X上发文称,Jimmy们,耐心等待时刻结束了。

目前,o1-preview已面向ChatGPT Plus、Team用户开放,企业用户将在下周获得访问权限。o1mini计划向所有免费用户开放。
今天被同行们夸爆了的o1,是否真的能带来GPT-4o刚面世时的惊艳感受?我们也来上手试试,另外也看看围绕o1,海内外玩家们都在玩些什么和聊些什么。
新的AI模型天花板,复杂推理是舒适区
有意思的是,新模型被OpenAI视为AI能力的重大进步,因此被命名为o1,表示“将计数器重置为1”,而不是GPT系列的延续。基于此,也有一些玩家开始担心:GPT-5恐怕是没戏了。
据“AI新榜”观察,无论是从OpenAI官方发布的Blog、Demo还是网友实测来看,复杂推理简直是o1的舒适区,在编程能力、数学计算上几乎碾压其他模型。
现在,ChatGPT Plus和Team用户可以在对话时手动选择o1-preview和o1-mini模型。
值得一提的是,o1-preview每周的消息限制为30条,o1-mini的周上限为50条。
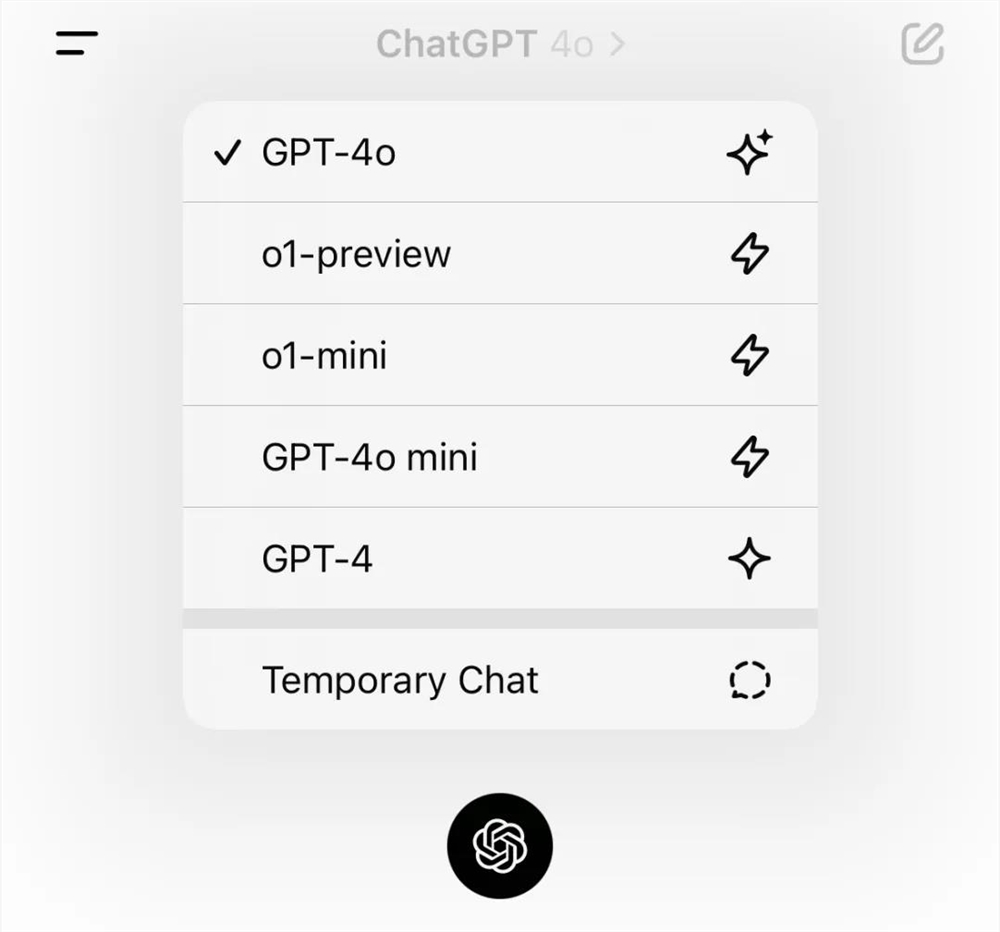
在复杂逻辑推理方面,OpenAI让GPT-4o和o1同时参加了国际数学奥林匹克竞赛资格选拔的AIME考试。结果显示,GPT-4o仅能正确解答13%的问题,而o1的准确率则高达83%,是4o的近8倍。
在官方Demo中,o1在面对下面这个难题时,只思考了约30秒的时间,就给出了正确的答案。
当公主的年龄是王子的两倍,而公主的年龄是他们现在年龄的一半时,公主的年龄将与王子一样大。王子和公主的年龄是多少?请提供该问题的所有答案。
更关键的是,o1还会通过“我很好奇”、“我正在思考”和“好的,让我看看”等语句,给人一种它正在一步一步思考的过程,很像人类做题时的推理步骤。
我们也丢了个复杂的逻辑问题给o1:
在一个小村庄里,只有两种职业的居民:种田的农民和捕鱼的渔民。村子里有一个很奇怪的规定:农民总是说谎,而渔民总是讲真话。有一天,三个村民A、B和C在谈话,A说:‘B是农民。’ B说:‘A和C职业相同。’ C说:‘我们都是农民。’ 根据村子的规定,” 问题:“请问A、B、C各自是做什么的?
同样是用了约30s的时间,o1就给出了滴水不漏的分析和正确答案。

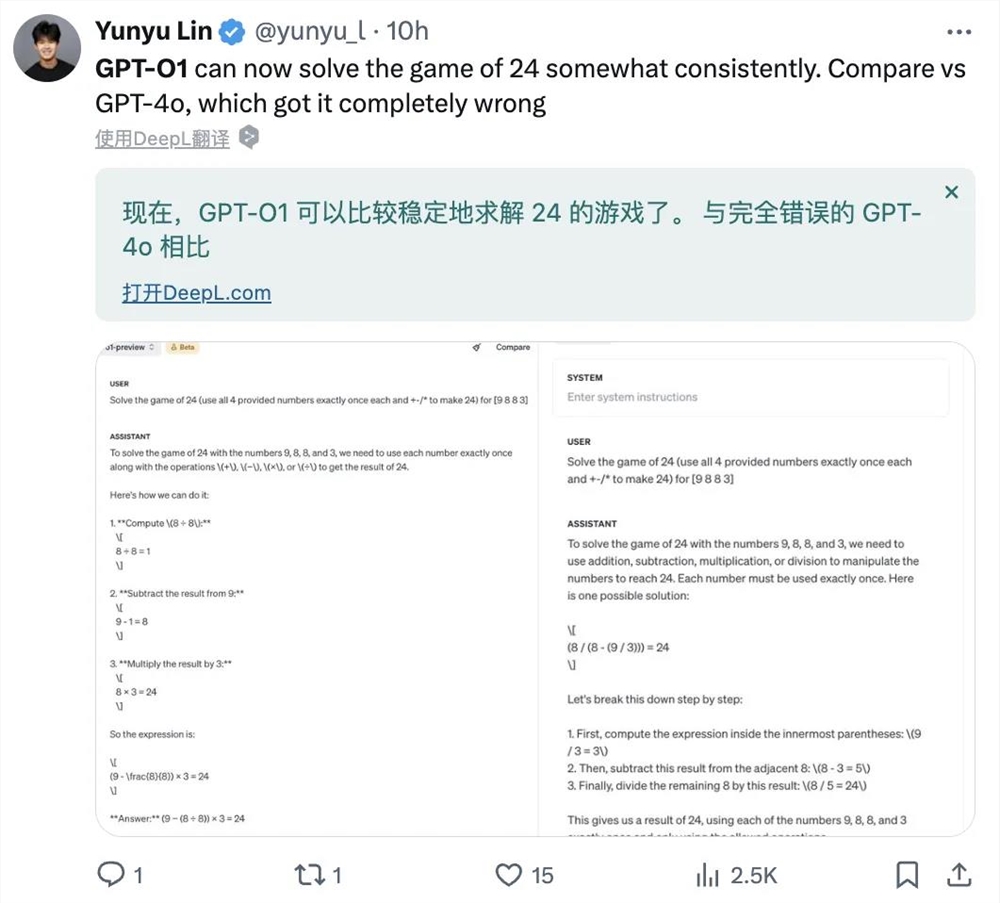
有网友跟o1玩24点游戏,发现它可以十分稳定准确地求解。相比之下,GPT-4o则表现得一塌糊涂。
24点游戏是把4张扑克牌牌面的数字通过加减乘除(包括括号)进行四则运算,使计算结果等于24的一个棋牌数学休闲益智小游戏。
你甚至可以让它帮忙出考研高数题,从而实现举一反三,触类旁通:

图源即刻“希汉同学”
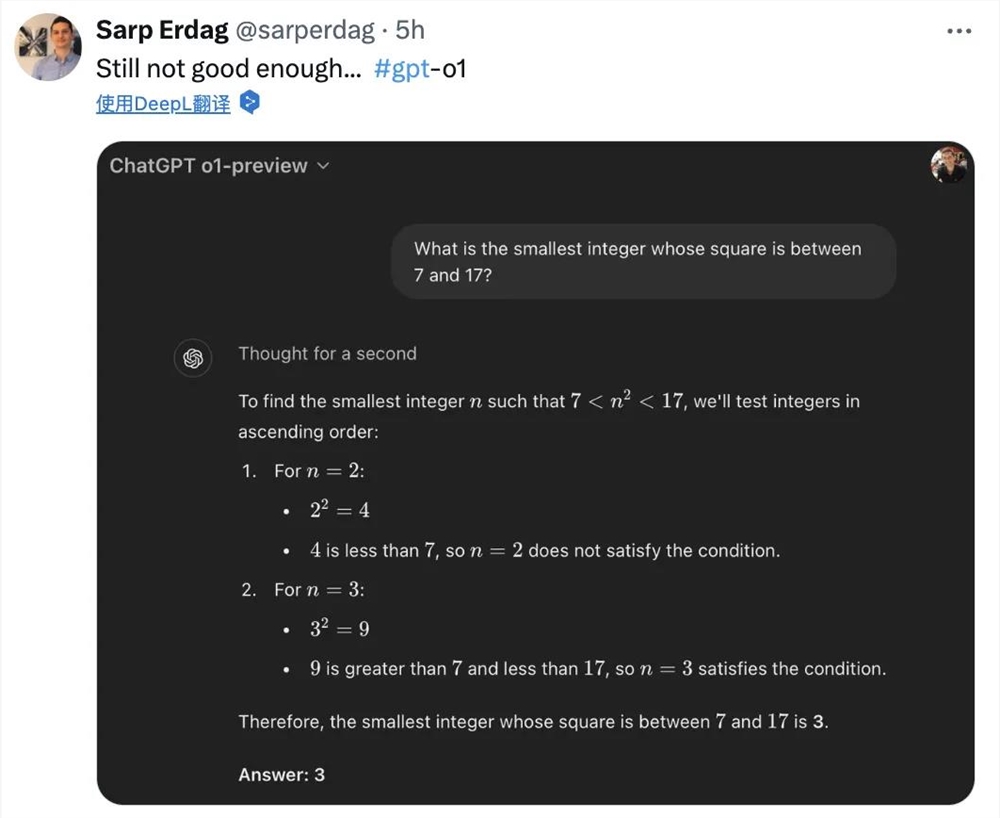
不过,虽然o1数学计算和逻辑推理能力很强,却偶尔会在一些相对简单的问题上栽跟头。
比如这道“平方数在7和17间的最小整数是多少?”就没能给出正确答案。
再来看看它的编程能力。
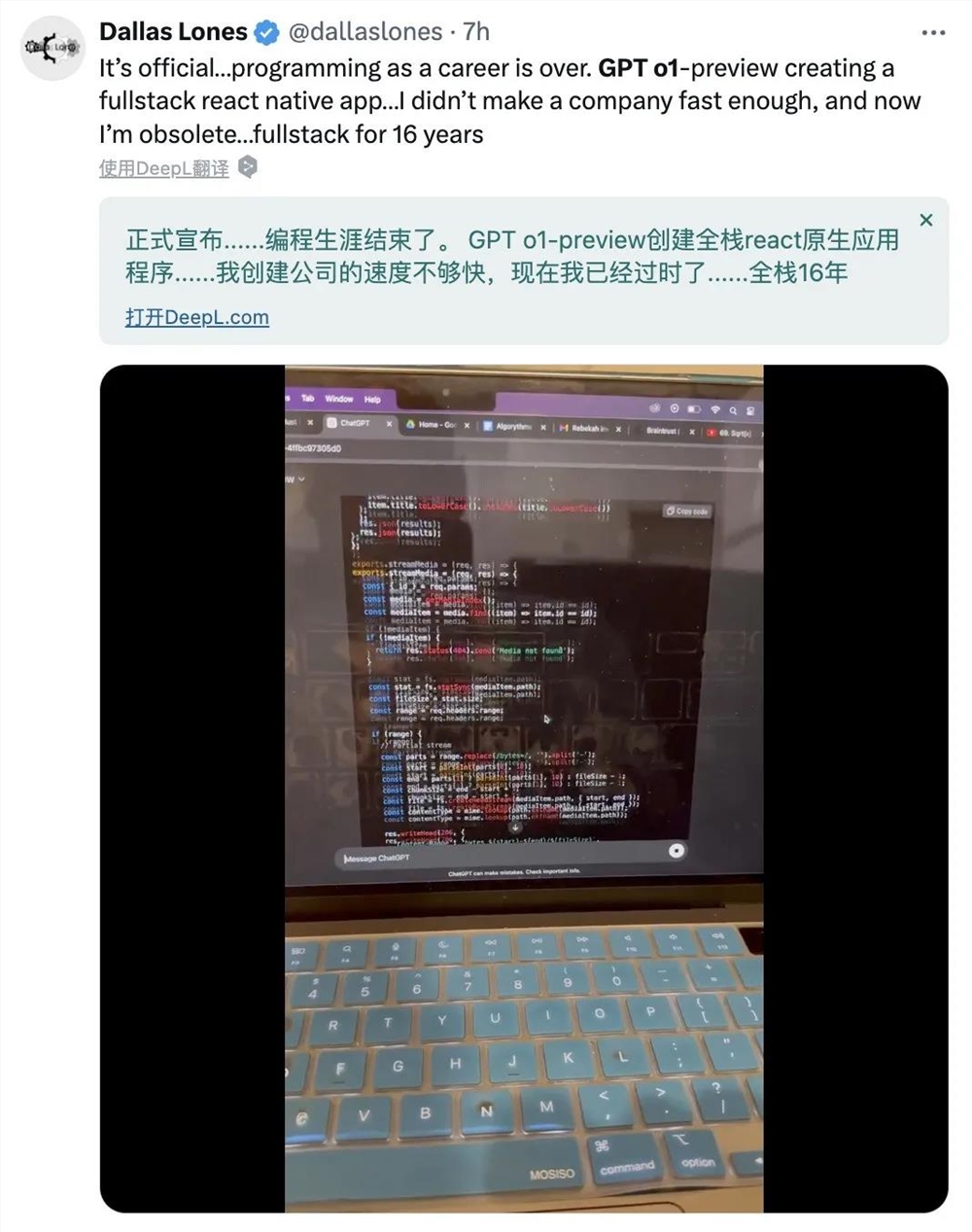
一位有着16年全栈经验的程序员,在试过用o1写代码后,直接宣告自己的编程生涯结束了。
只见他的电脑屏幕上,o1正在快速生成一个全栈原生应用程序的代码。
在OpenAI发布的视频演示里,演示者先是让o1写一个贪吃蛇网页游戏,这种小case可能不算什么,紧接着演示者提升难度,让它在网格中添加障碍物,并且使障碍物连成“AI”的形状,照样没能难倒它。

还有网友将o1和前不久爆火的编程神器Cursor结合,在10分钟内创建了一个iOS天气应用程序。
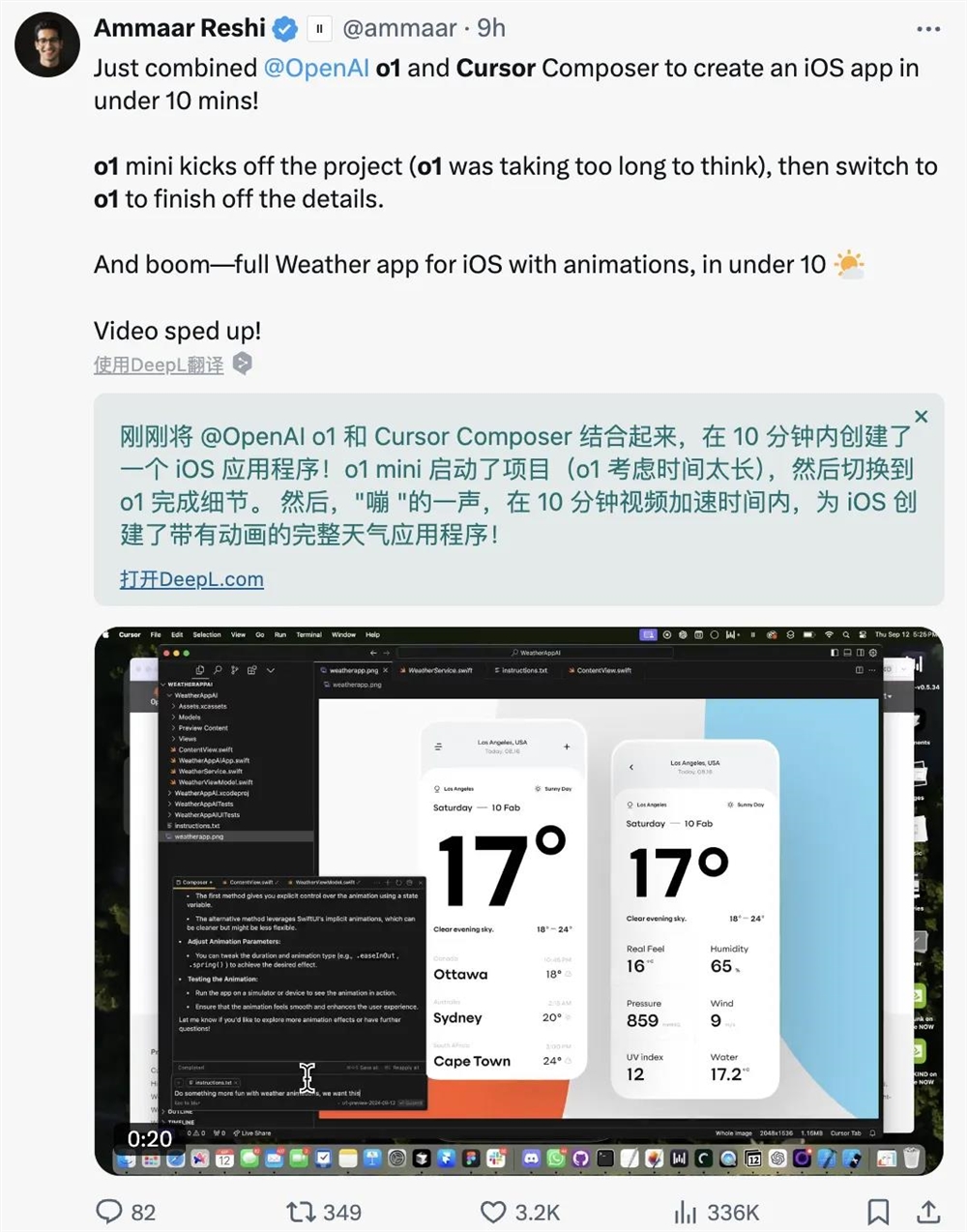
而在此之前,Claude Sonnet3.5通常被很多人当作Cursor的强力搭档。
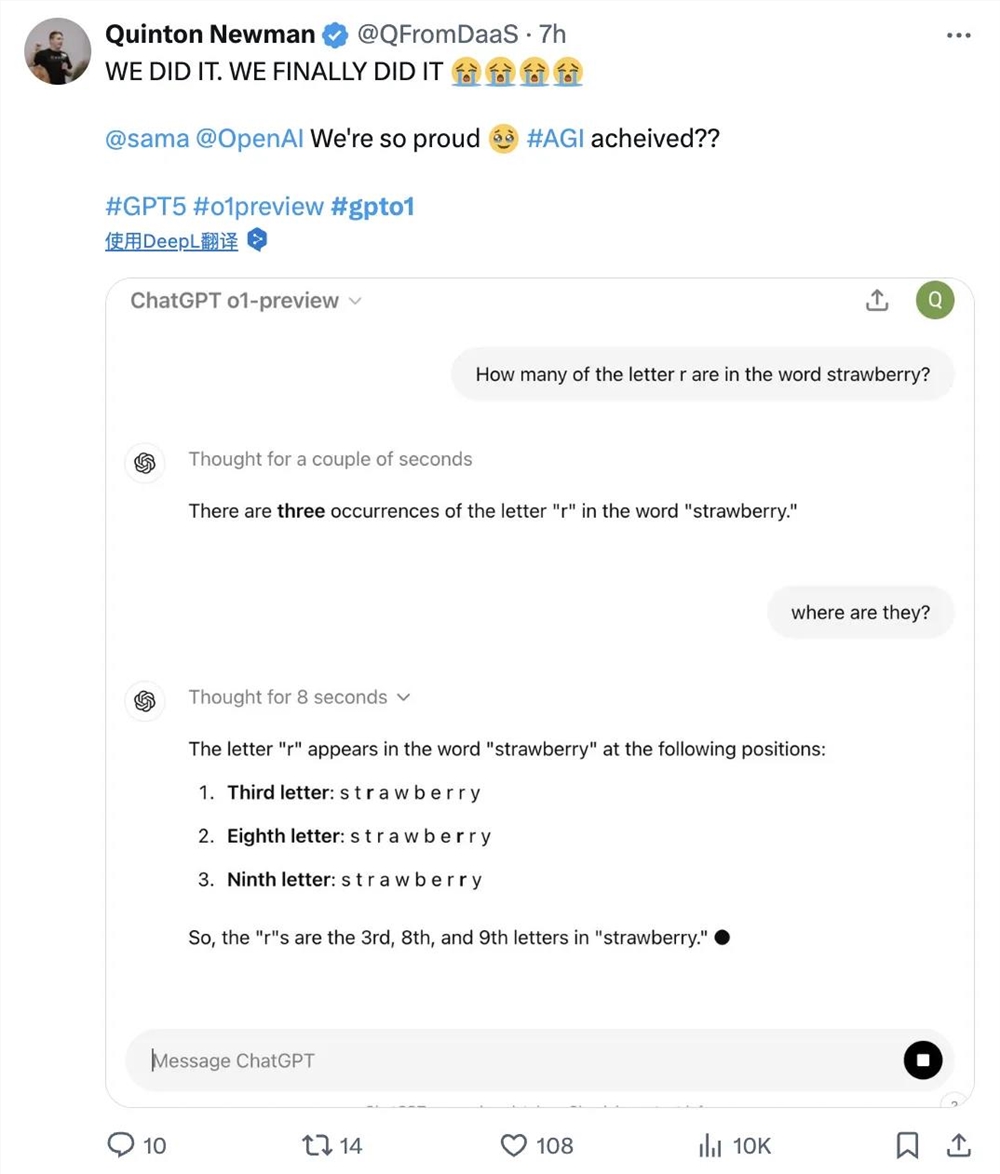
还是那道经典的“单词Strawberry里有几个r”,这个简单的问题曾难倒包括GPT-4o在内的不少大模型,但在o1面前已然成了小儿科。
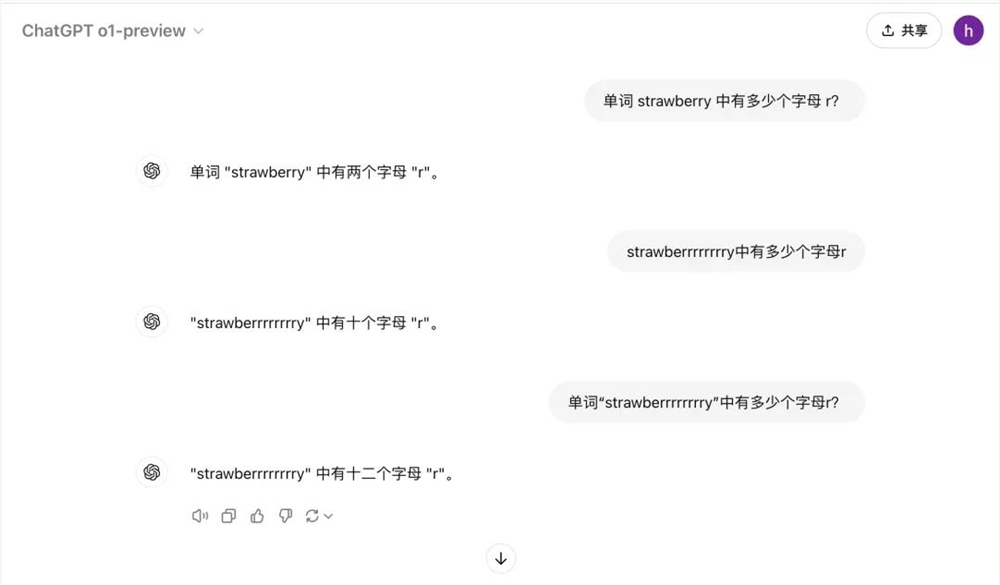
不过,o1的发挥看起来不是那么稳定,也有数错的情况。
o1很强,但纯文本模型还吸引人吗?
在各家卷多模态模型的时候,OpenAI既没有兑付自己的语音功能,更是将Sora早早抛在脑后了。眼下,还发了一款纯文本模型。
相信上述的实测和玩法,已经为大家解答了“OpenAI o1模型究竟强在哪”这个问题。
o1模型不需要额外提示,它就能自行推理和反思自己的解答过程,将复杂问题一步步拆解开来,清晰地展示了自己思考的过程。
比如,o1在写代码前会梳理一遍问题,列出相关知识点和步骤,然后开始逐行写代码,并完成代码测试。
有网友调侃,OpenAI o1来了,Claude3.5、Cursor等以编程能力见长的热门AI工具可以放一边了。
Jimmy Apples发文表示,OpenAI故事第二章Straberry Fields终于开启。
英伟达首席研究员Jim Fan认为,o1的意义在于,AI团队不再只是通过增加模型规模来提升模型表现,而是通过优化推理过程。
全网的科技大佬们面对新模型,都是兴奋难抑的状态,但对于我们普通人的日常使用来说,o1的作用其实不是特别明显。
科技博主“特工宇宙”提到,客观来讲,o1的科研价值远大于当下的使用价值。我们也许会更受益于OpenAI o1开发的新软件、新药物,而不是o1本身。
可以说,o1的意义更像是展现AI变强的可能性,但对于大多数用户来说,o1的更新仅仅是在底层模型上进行优化迭代,实际好用好玩的AI工具会更吸引人。
所以,也架不住大多数网友在评论区在线开催Sam Altman:“我们什么时候能得到新的语音功能??”
另外,目前的o1系列模型还只是预览版本,像GPT-4o拥有的长文本、网络插件、生成图片等功能,均未集成到o1中。
在定价上,o1也并不是经济适用的选择。对于开发者而言,o1-preview 的定价为15美元/百万输入token,60美元/百万输出token,远高于GPT-4o(5美元/百万输入token,15美元/百万输出token)的定价。
总的来说,GPT-4o依旧是OpenAI能力最强的模型。也有博主在X上提到:“普通人根本不理解大象的推理和逻辑能力。GPT-5还要比o1模型更强大69倍。”
这也让人好奇,即将到来的OpenAI开发者日会带来怎样的更新,迟迟未来的“GPT-5”是否还会制造惊喜?
(举报)








发表评论取消回复