不知道大家在学数理统计的时候,对这三个概念怎么理解的,我学的时候还是很有疑惑的,为什么随机变量可以用样本表示,那统计量用来干什么的呢?于是我查阅了很多资料,下面谈谈自己的认识,欢迎大家分享自己的理解。
1 引言
自然界和社会上发生的现象是多种多样的。概括起来可以分为两大类:一类现象,在一定条件下必然发生,例如,同性电荷必相互排斥,等等。这类现象称为确定现象。另一类现象,比如在相同条件下抛同一枚硬币,其结果可能是正面朝上,也可能是反面朝上,并且在每次抛之前无法确定抛掷的结果是什么,等等。这类现象,在一定的条件下,可能出现这样的结果,也可能出现那样的结果,而在试验或观察之前不能预知确切的结果。但在大量重复实验或观察下,它的结果却呈现某种规律性。像这种在个别试验中其结果呈现出不确定性,在大量重复试验中其结果又具有统计规律性的现象,我们称之为随机现象。
数理统计学是研究随机现象规律性的一门学科,它以概率论为理论基础,研究如何以有效的方式收集﹑整理和分析受到随机因素影响的数据,并对所考察的问题作出推理和预测,直至为采取某种决策提供依据和建议。数理统计研究的内容非常广泛,概括起来可分为两大类:一是试验设计,即研究如何对随机现象进行观察和试验,以便更合理更有效地获得试验数据;二是统计推断,即研究如何对所获得的有限数据进行整理和加工,并对所考察的对象的某些性质作出尽可能精确可靠的判断(这不正是目前机器学习在做的事)。
统计学研究的一个主要问题是通过试验推断总体。而概率论为整个统计学奠定了基础,它为总体、随机试验等几乎所有随机现象的建模提供了方法。下面先引入概率论的中常用的样本空间、事件、随机变量和概率空间的几个概念,然后引入统计里常用的总体、样本、统计量。
2 概率论基础
2.1 样本空间
称某次随机试验 E E E 全体可能的结果所构成的集合 Ω Omega Ω 为该试验的 样本空间(sample space)。样本空间的元素,即 E E E 的每个结果,称为样本点 e e e。
2.2 随机事件
我们称试验 E E E 的样本空间 Ω Omega Ω 的子集为 E E E 的随机事件,简称事件。每次试验中,当且仅当这一子集中的一个样本点出现时,称这一事件发生。由一个样本点组成的单点集,称为基本事件。一个事件(event)是一次试验若干可能的结果所构成的集合,即 S 的一个子集(可以是S本身)。
2.3 随机变量
设随机试验的样本空间为 S = { e } S={e} S={e}。 X = X ( e ) X=X(e) X=X(e) 是定义在样本空间 S S S 上的实值单值函数。称 X = X ( e ) X=X(e) X=X(e) 为随机变量。随机变量的本质就是从样本空间映射到实数的函数。随机变量常以大写字母记,其具体取值则用相应的小写字母表示。例如,随机变量 X X X 可以取值 x x x。
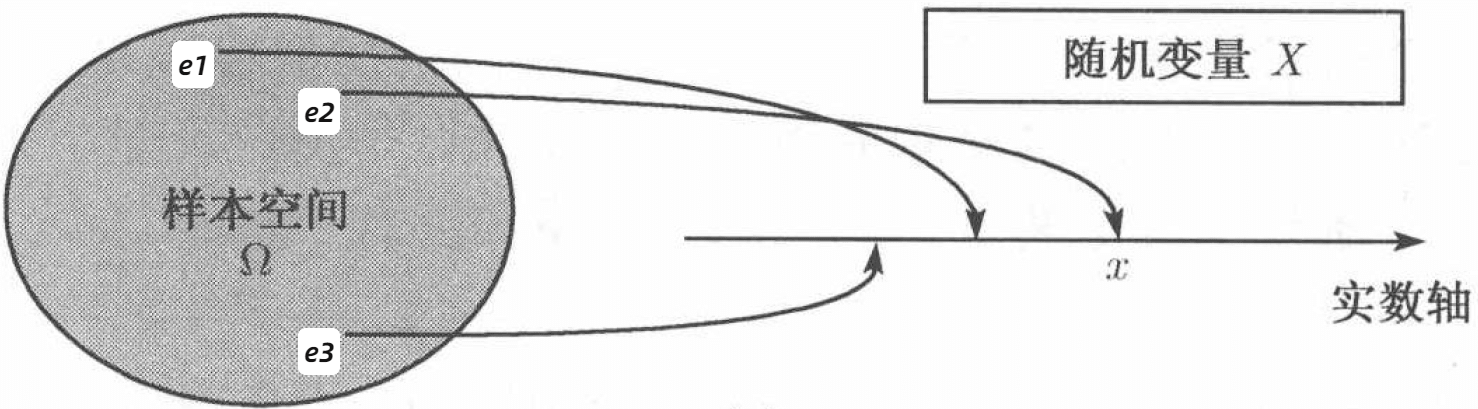
研究随机变量的目的是通过研究随机变量的概率特性,或者叫统计特性,来反映和预测结果。
随机变量的数字特征: 数学期望(均值:反映数据集中在哪个量附近,一般不与随机变量的取值相同),方差(反映波动大小:反映数据的集中程度),两个随机变量的协方差(反映两个随机变量的相依关系),分布函数(分布律:反映随机变量落入某区域的概率),密度函数(连续型:反映随机变量在某点附近概率的变化快慢,密度函数的积分就是分布函数)。
多维随机变量或多维随机向量。随机向量是样本空间到实数组集合的映射。例如(X,Y)是二维随机变量,对应的是实数对,可以取值为(1,2)。
多元随机变量是一个随机变量,只不过是多元的。例如 X Y XY XY 是二元随机变量,可以取值为 1 × 2 1times 2 1×2。函数 f ( X Y ) f(XY) f(XY) 是 X Y XY XY 的函数。
总结: 维是代表随机变量维度增多了,元代表随机变量个数增多了。
2.4 概率空间
概率论中,用 e e e 为基本事件或样本, Ω Omega Ω 为样本空间, A ( ∈ F ) A(inmathcal{F}) A(∈F) 为事件, F mathcal{F} F 是事件的全体,而 P ( A ) P(A) P(A) 表示事件发生的概率。三元组 ( Ω , F , P ) (Omega, mathcal{F}, P) (Ω,F,P) 构成概率空间。
3 数理统计
3.1 总体
在数理统计学中,我们把所研究对象的全体元素组成的集合称为总体(或称母体),而把组成总体的每个元素称为个体。例如,在考察某批灯泡的质量时,该批灯泡的全体就组成一个总体,而其中每个灯泡就是个体。
但是,在实际应用中,人们所关心的并不是总体中个体的一切方面,而所研究的往往是总体中个体的某一项或某几项数量指标。例如,考察灯泡质量时,我们并不关心灯泡的形状,式样等特征,而只研究灯泡的寿命、亮度等数量指标特征。如果只考察灯泡寿命这一项指标时,由于一批灯泡中每个灯泡都有一个确定的寿命值,因此,自然地把这批灯泡寿命值的全体视为总体,而其中每个灯泡的寿命值就是个体。由于具有不同寿命值的灯泡的比例是按一定规律分布的,即任取一个灯泡其寿命为某一值具有一定概率,因而,这批灯泡的寿命是一个随机变量,也就是说,可以用一个随机变量 X X X 来表示这批灯泡的寿命这个总体。因此,在数理统计中,任何一个总体都可用一个随机变量来描述。总体的分布及数字特征,即指表示总体的随机变量的分布及数字特征。对总体的研究也就归结为对表示总体的随机变量的研究。
3.2 样本
为了了解总体
X
X
X 的分布规律或某些特征,必须对总体进行抽样观察,即从总体
X
X
X 中,随机抽取
n
n
n 个个体
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, cdots, X_n
X1,X2,⋯,Xn,记为
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T,并称此为来自总体
X
X
X 的容量为
n
n
n 的样本。由于每个
X
i
X_i
Xi 都是从总体
X
X
X 中随机抽取的,它的取值就在总体
X
X
X 的可能取值范围内随机取得,自然每个
X
i
X_i
Xi 也是随机变量,从而样本
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T 是一个
n
n
n 维随机向量。
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T 是一个
n
n
n 维随机向量。在抽样观测后,它们是
n
n
n 个数据
(
x
1
,
x
2
,
⋯
,
x
n
)
T
(x_1, x_2, cdots, x_n)^T
(x1,x2,⋯,xn)T,称之为样本
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T 的一个观测值,简称样本值。
我们的目的是依据从总体
X
X
X 中抽取的一个样本值
(
x
1
,
x
2
,
⋯
,
x
n
)
T
(x_1, x_2, cdots, x_n)^T
(x1,x2,⋯,xn)T,对总体
X
X
X 的分布或某些特征进行分析推断,因而要求抽取的样本能很好地反映总体的特征且便于处理,于是,提出下面两点要求:
(1)代表性——要求样本
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T同分布且每个
X
i
X_i
Xi 与总体
X
X
X 具有相同的分布。
(2)独立性——要求样本
(
X
1
,
X
2
,
⋯
,
X
n
)
T
(X_1, X_2, cdots, X_n)^T
(X1,X2,⋯,Xn)T 是相互独立的随机变量。
满足上述两条性质的样本称为简单随机样本。
3.3 统计量
样本是进行统计推断的依据。在应用时,往往不是直接使用样本本身,而是针对不同的问题构造样本的适当函数,利用这些样本的函数进行统计推断。
设
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, cdots, X_n
X1,X2,⋯,Xn 是来自总体
X
X
X 的一个样本,
g
(
X
1
,
X
2
,
⋯
,
X
n
)
g(X_1, X_2, cdots, X_n)
g(X1,X2,⋯,Xn)是
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, cdots, X_n
X1,X2,⋯,Xn 的函数,若
g
g
g 中不含任何未知参数,则称
g
(
X
1
,
X
2
,
⋯
,
X
n
)
g(X_1, X_2, cdots, X_n)
g(X1,X2,⋯,Xn) 是一统计量。
因为
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, cdots, X_n
X1,X2,⋯,Xn 都是随机变量,而统计量
g
(
X
1
,
X
2
,
⋯
,
X
n
)
g(X_1, X_2, cdots, X_n)
g(X1,X2,⋯,Xn) 是随机变量的函数,因此统计量是一个随机变量。
参数是用来描述总体特征的概括性数字度量,是研究者想要了解的总体的某种特征值。由于总体数据通常是不知道的,所以参数是一个未知的常数。统计量是用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一个量。由于抽样是随机的,所以统计量是样本的函数;由于样本是已知的,所以统计量总是知道的。抽样的目的就是要根据样本统计量去估计总体参数。
3.4 样本和随机变量
统计里的样本有二重性,即样本既可以看作是一组观测值又可以看作是随机变量。因为在抽样之前,样本观测值是未知的,所以可以看成是随机变量(设该样本为 X X X,抽取之前 X X X 的值未知, X X X 的值是什么,其概率分布是符合对应随机变量概率分布的);而当样本抽取完之后又是一组确定的值,故又可以看成是一组确定的值。一般情况下把样本看作是一组随机变量。
个人理解: 在统计学里,即抽样分布里,在数据是一维的时候,可以把每个样本都看做一个随机变量;但到了概率论中,对于给定一个多维数据,比如多个样本多个特征,此时应该把每个特征看做一个随机变量,这时才有协方差矩阵的概念。随机变量是贯穿于概率论和数理统计的一个概念,在前后学习的时候如果可以正确认识,会对统计有更深的理解。
参考
- 随机变量和随机过程的个人理解:https://zhuanlan.zhihu.com/p/47113623
- 样本和随机变量的区别联系:https://blog.csdn.net/qq_29488527/article/details/79779661
- 总体和样本的区别与联系:https://zhuanlan.zhihu.com/p/103697284
最后
以上就是大气大树最近收集整理的关于统计篇(五)-- 随机变量、样本、统计量的全部内容,更多相关统计篇(五)--内容请搜索靠谱客的其他文章。








发表评论 取消回复