文章链接:https://arxiv.org/pdf/1509.06451.pdf
1、关于人脸检测的一些小小总结(Face Detection by Literature)
(1)Multi-view Face Detection Using Deep Convolutional Neural Network
- Train face classifier with face (> 0.5 overlap) and background (<0.5 overlap) images.
- Compute heatmap over test image scaled to different sizes with sliding window
- Apply NMS .
- Computation intensive, especially for CPU.
- http://arxiv.org/abs/1502.02766

(2)From Facial Parts Responses to Face Detection: A Deep Learning Approach
Keywords: object proposals, facial parts, more annotation.
- Use facial part annotations
- Bottom up to detect face from facial parts.
- "Faceness-Net’s pipeline consists of three stages,i.e. generating partness maps, ranking candidate windows by faceness scores, and refining face proposals for face detection."
- Train part based classifiers based on attributes related to different parts of the face i.e. for hair part train ImageNet pre-trained network for color classification.
- Very robust to occlusion and background clutter.
- To much annotation effort.
- Still object proposals (DL community should skip proposal approach. It complicate the problem by creating a new domain of problem :)) ).
- http://arxiv.org/abs/1509.06451

(3)Supervised Transformer Network for Efficient Face Detection
- http://home.ustc.edu.cn/~chendong/STN_Detector/stn_detector.pdf
(4)UnitBox: An Advanced Object Detection Network
- http://arxiv.org/abs/1608.02236
(5)Deep Convolutional Network Cascade for Facial Point Detection
- http://www.cv-foundation.org/openaccess/content_cvpr_2013/papers/Sun_Deep_Convolutional_Network_2013_CVPR_paper.pdf
- http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm
- https://github.com/luoyetx/deep-landmark
(6)WIDER FACE: A Face Detection Benchmark
A novel cascade detection method being a state of art at WIDER FACE
- Train separate CNNs for small range of scales.
- Each detector has two stages; Region Proposal Network + Detection Network
- http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
- http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/support/paper.pdf

(7)DenseBox (DenseBox: Unifying Landmark Localization with End to End Object Detection)
Keywords: upsampling, hardmining, no object proposal, BAIDU
- Similar to YOLO .
- Image pyramid of input
- Feed to network
- Upsample feature maps after a layer.
- Predict classification score and bbox location per pixel on upsampled feature map.
- NMS to bbox locations.
- SoA at MALF face dataset
- http://arxiv.org/pdf/1509.04874v3.pdf
- http://www.cbsr.ia.ac.cn/faceevaluation/results.html
(8)Face Detection without Bells and Whistles
Keywords: no NN, DPM, Channel Features
- ECCV 2014
- Very high quality detections
- Very slow on CPU and acceptable on GPU
- https://bitbucket.org/rodrigob/doppia/
- http://rodrigob.github.io/documents/2014_eccv_face_detection_with_supplementary_material.pdf
2、重点解读 (From Facial Parts Responses to Face Detection: A Deep Learning Approach--2015ICCV)
该文章来自于香港中文大学汤晓鸥实验室做的人脸检测,很有借鉴意义,论文提出了一个新的概念deep convolutional network (DCN) ,在FDDB数据集上达到了目前世界领先水准,这篇论文可以与之前《Joint Cascade Face Detection and Alignment》结合来看,其实是同一种思想在不同方向上的应用。
论文提出的DCN主要有三点新优势:
1、对遮挡有较强的鲁棒性。
2、可以检测到多角度倾斜人脸。
3、可以从一整张图片中检测出大小不一的人脸。
主要得益于一点,利用人脸上关键点的位置信息判断是否人脸(是不是和之前的JDA有些像啊),总结一下就是先用5个CNN检测全图,5个CNN分别是用于检测头发、眼睛、鼻子、嘴巴、脖子,之后合并五个的结果,利用这些位置信息判决人脸。
(1)Faceness-Net
Faceless-Net工作流包括三个阶段,生成人脸局部信息特征图,根据打分排序候选框,完善候选框。整个流程如图a所示。

在第一阶段,人脸被作为输入放进5个CNN网络,5个输出包含各个器官的位置信息,被整合为一个hf送入下一阶段。
在第二阶段,匹配这些器官位置,对其打分排序。
在第三阶段,一次检测,无需滑窗。
下面分别详述每个阶段:
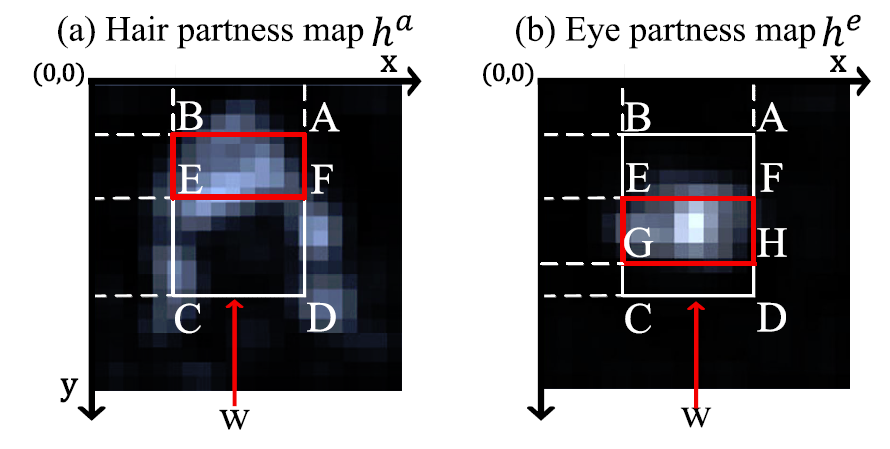
(2)Partness Maps Extraction
网络结构如下图所示:

研究指出叠加多个卷积层可以获得目标位置。
下图展示了各个网络区分粒度的效果:

从图上结果显示,当粒度从物体-非物体,人脸-非人脸,亚洲人脸-欧洲人脸等,升至直发-卷发、微笑-厚嘴唇等这样的器官粒度时,对遮挡人脸的鲁棒性最强,5个网络的分类可以如下表一样,为了获得更好的区分效果,每个网络模型都是从ImageNet训练好的模型微调而来。

(3)Ranking Windows by Faceness Measure :
利用partness map对候选框进行打分,是通过每个part map进行的空间位置先验,比如头发在脸的上方,眼睛在脸的中央,来进行人脸or 非人脸的打分(faceness score)。如图3,将打完分的part map进行相加,通过NMS(Non-Maximun Suppression,非极大值抑制)就可以将每个部位定位好的矩形框合并成一个大的矩形框,即为人脸的proposal。 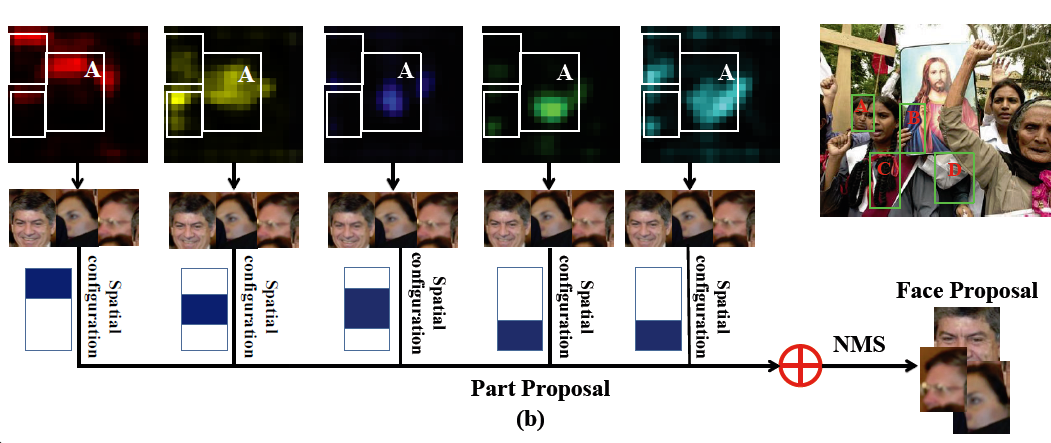
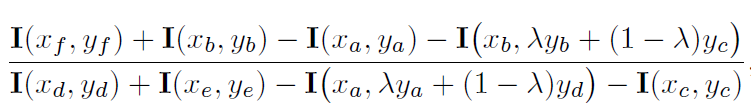
,使得不同部件的空间配置合理,能够区分人脸和非人脸的置信度最大。 在这里,我们通过学习的方法来得到λ
。具体做法就是给定一个训练集(w,r,h),w指的是人脸的boundingbox,r是人脸和非人脸的label,h是我们知道头发所在的区域,我们的目的就是学习到一个参数λ
使得有头发的地方获得一个高分。而且我们知道λ
是一个服从0-1均匀分布的随机变量,所以这个问题也就是求最大后验的问题。用最大后验来求解 lamda:

(4)Refine face detection
最后作者通过使用来自AFLW的人脸图片和来自于PASCAL VOC 的非人脸数据来finetune AlexNet网络来对产生的proposal进行提纯,提高检测准确率.
(5)Experiments
Training dataset: (1)对于部件检测器的训练,用的是CelebFaces,包含87628张图片,我们为所有的这些图片标上Table 1中所列的25种attributes,然后将这些属性划分到5个part的各个类中,这样就完成了attribute-aware network训练数据的准备工作。我们随机抽取其中75000张作为训练,余下的作为验证。 (2)对于人脸检测器的训练,我们从AFLW dataset中选取13205张图片并保证不同姿态的图片分布均匀,另外PASCAL VOC 2007 dataset中随机选取5771张图片。
Part response testing dataset:2827张LFW images,包含了头发和胡子的标注,另外其他人脸部件如眼睛等也进行人工标注,并通过68个danse facial landmarks来guide。
Face proposal and detection testing datasets:FDDB,AFW和PASCAL
作者:南君
出处:http://www.cnblogs.com/molakejin/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载于:https://www.cnblogs.com/molakejin/p/8268531.html
最后
以上就是犹豫期待最近收集整理的关于paper 159:文章解读:From Facial Parts Responses to Face Detection: A Deep Learning Approach--2015ICCV...的全部内容,更多相关paper内容请搜索靠谱客的其他文章。








发表评论 取消回复