【论文】Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
之前有很多用CNN做人脸识别和人脸关键点对齐的文章,具体可以参考这篇文章的参考文献,这些文章都是比较经典的。这篇文章的创新之处就在于把人脸检测和人脸关键点对齐的任务放在了一起,并且设计了一种网络由粗到精的级联结构,使得两个任务都获得了增益。
【一、网络结构】
首先先说网络结构,一共有3级网络P-NET,R-NET,O-NET。
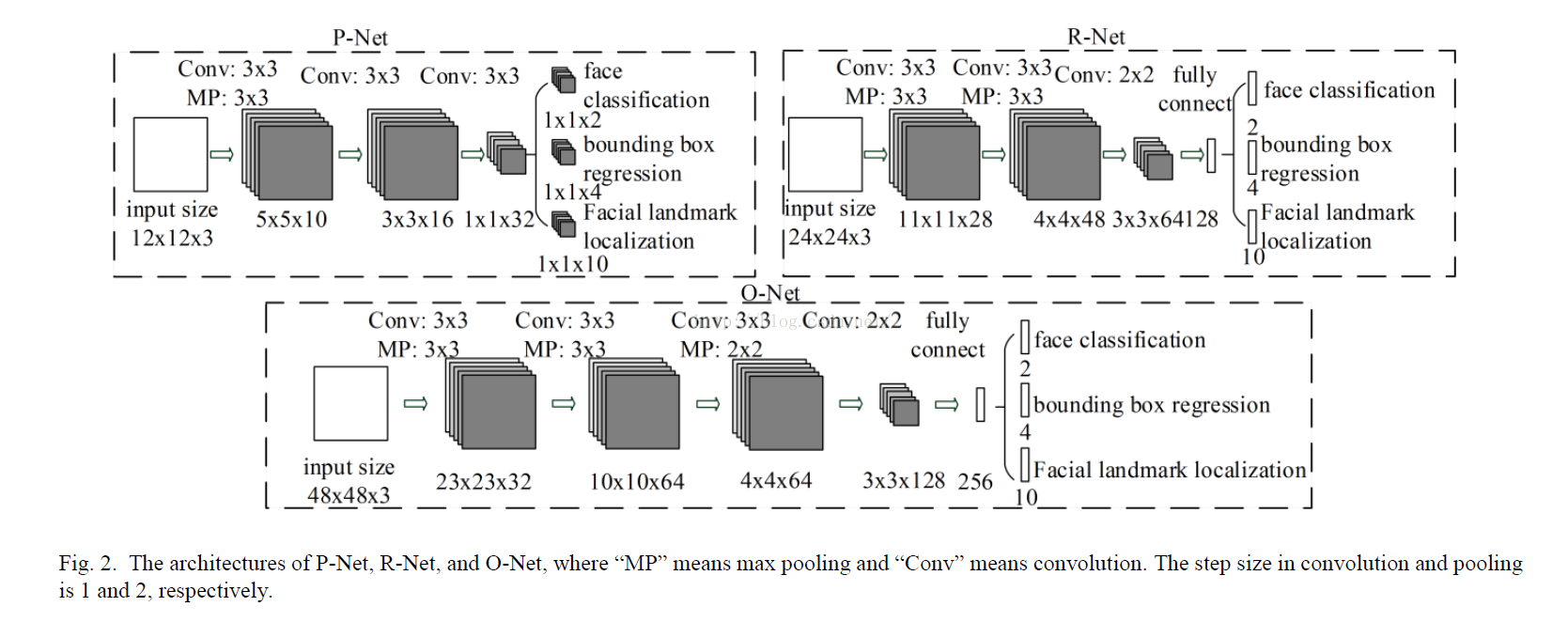
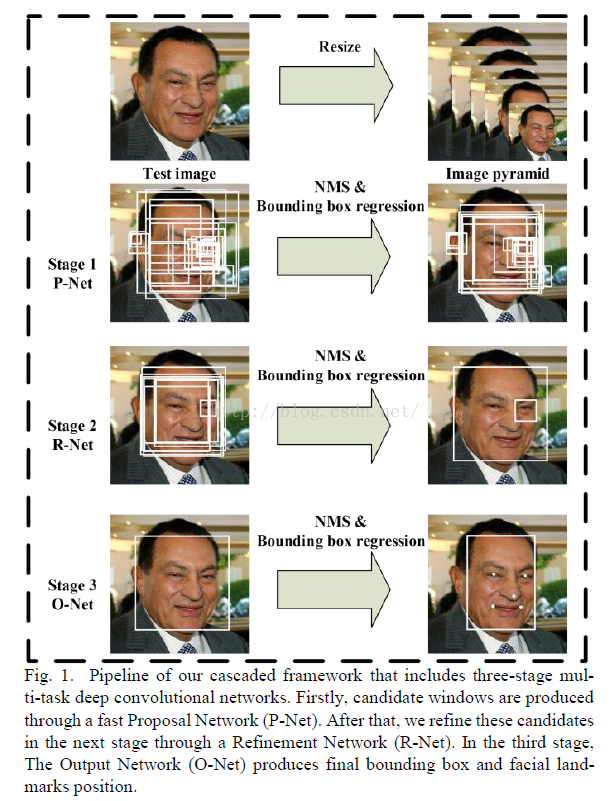
P-NET的任务是用浅层的CNN提取候选窗口,R-NET用一个更为负责的CNN去精细化窗口,并且排除大量的非人脸窗口,O-NET用一个更强的CNN去精细化结果,并输出人脸关键点坐标。
同时网络中的所有卷积核都是3*3,并且降低feature_map的个数。
【二、训练网络的trick】
作者在训练的时候,网络的损失函数也是很有意思的,对于这三部分CNN来说损失函数都有以下提到的几个定义。另外运用了一个叫做Online Hard Sampling Mining 的训练技巧。接下来就详细说说这个部分:
1. Face classification 人脸分类
这部分的损失函数就和logistic regression一样,都使用了交叉熵的形式,不明白的同学可以看看logistic那一块。
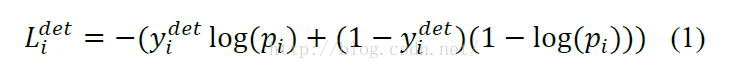
公式中yi是目标框的实际标签,只有0/1两种取值(0代表不是人脸,1代表是人脸),pi是网络输出这个目标属于人脸的概率。
2.Bounding Box Regression 目标框的回归(人脸定位)
这部分使用欧氏距离作为损失函数
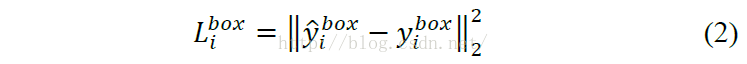
公式中带尖号的yi代表网络输出的框的坐标,后面的yi代表与尖号yi最近的grund truth矩形框,他们都是1*4的向量,代表矩形的左上角、右下角两个点的坐标,然后对这两个向量求欧氏距离。
3.Facial Landmark Localization 人脸关键点定位
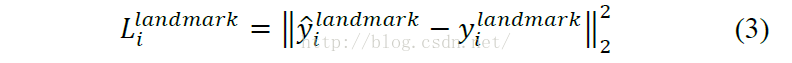
这部分与人脸定位的损失函数是一样的。
4. Multi-source training
这部分我们来说明如何把1-3部分的损失函数结合起来运用。
在不同情况下用到的loss function是不同的,比如说:如果当前的图片是背景,也就是没有人脸,那么只计算第一个loss function,也就是L(det),其他两个loss都设置为0。那么整体的损失函数就能写成下面这个形式:
其中N是样本数,alpha代表上述3个loss的权重,3个不同的级联网络有不同的设置。对于P-NET和R-NET有:alpha(det)=1,alpha(box)=0.5,alpha(landmark)=0.5。对于O-NET有:alpha(det)=1,alpha(box)=0.5,alpha(landmark)=1。由此可以看出前两层网络基本已经将人脸分类和人脸定位训练得差不多了,O-NET是加强了特征点定位。还有就是belta(取值为0/1),它有两个下标,j的取值就是det,box,landmark,i的取值是样本的标号,这个就是之前提到的那个意思,比如在取到背景的proposal时,delta在第1个loss上取值为1,第2、3的loss上取值为0。然后对于每一个mini batches,我们把每个样本的loss加起来,然后去minimize这个loss。
5. Online Hard Sample Mining
这个trick是用来针对难训练的样本的,一句话概括就是:最小化难分辨样本的loss。
对每一个mini batch,对所有当前batch里的样本按照前馈的loss进行排序,选择前70%作为hard samples,在计算bp算法时,只计算hard samples的梯度。即在计算梯度时去除了那些简单的样本。
【三、实验】
1.training data
所有的数据分为4种:
i) Negatives:截取的patch与任意Ground-Truth face的IoU值小于 0.3
ii) Positive:IoU与一个GT face大于0.65
iii) Part faces:IoU与一个GT face在0.4-0.65之间
iiii) Landmark face:标记了5点坐标的人脸
有了上述四种数据集之后,我们就可以进行训练了:
P-NET:从WIDER FACE中随机截取positives、negatives和part face。并且从CelebA数据集中截取landmark faces,对上述数据集不了解的可以自己查一查。
R-NET:用P-NET来从WIDER FACE中收集positives、negatives和part faces。part faces数据还是从celebA中检测。
O-NET:与R-NET类似,只是用前两层级联输出的结果进行检测。
2. online hard sample mining的效果
作者训练了两个O-NET,一个用了online hard sample mining,一个没用。结果如下:
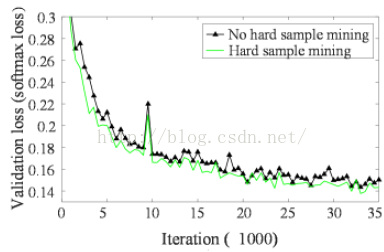
3. 把face detection和face alignment任务同时完成的效果评估
下图中JA代表本文的方法,No JA代表不合并这两个任务的方法,NO JA IN BBR代表用CNN训练人脸detection时不把两个任务合并(原话:“JA” denotes joint face alignment learning while “No JA” denotes do not joint it. “No JA in BBR” denotes do not joint it while training the CNN for bounding box regression.)
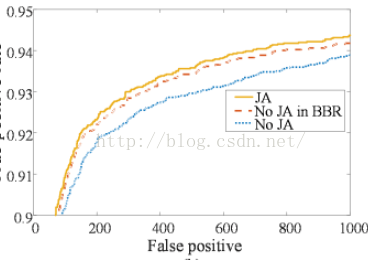
实验表明,将两个任务一起完成时,在两个任务上都有增益,即完成的效果都比单个完成更好了。
4. 与其他人脸detection算法对比
不多说了,反正就是比别人好,详情见论文。
5. 与其他face alignment算法对比
详情见论文。
看完之后我觉得最大的收获就是明白了其实多任务训练出来的网络可能在单个任务上会有意想不到的增益,而且网络训练的trick也是这篇文章的一大亮点。
转载请标明出处,谢谢。
最后
以上就是乐观中心最近收集整理的关于【Deep Learning】Face Detection and Alignment的全部内容,更多相关【Deep内容请搜索靠谱客的其他文章。







![[reading notes]One Millisecond Face Alignment with an Ensemble of Regression Trees1. I recommend this paper for the following reasons2. algorithm process](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)
发表评论 取消回复