1.前言
最近研究WorldModel世界模型,期望能在科研上有所突破,本文将记录我的调试代码流程,从零开始(这是第二次,第一次花了一天多,到最后包的路径有些乱,再重新开始做一个总结,希望对新手有些帮助)。
https://cloud.tencent.com/developer/news/224238
训练参考
https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2652020138&idx=5&sn=013a0d05099c6381a742db040a85bc26&chksm=f121e95bc656604df056197e83985db6a59c7136d4450edb242af790e17e976976acdc6ef677&scene=0#rd
训练参考2号
https://github.com/AdeelMufti/WorldModels
另一份参考
https://segmentfault.com/a/1190000000485292
最后mpi报错原因
然而感觉他们都是翻译的,有一些指令有遗漏
关于配置路径,python各种包的引用环境
https://blog.csdn.net/qq_39004117/article/details/85306475
box2d
2.我的环境
ubuntu18.04
3.流程
(1)从github下载代码
https://github.com/AppliedDataSciencePartners/WorldModels.git
命令:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
(2)创建一个Python3虚拟环境(这里使用的是virutalenv和virtualenvwrapper):
sudo apt-get install python-pip
//pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。
sudo pip install virtualenv
sudo pip install virtualenvwrapper
//安装两个虚拟软件
exportWORKON_HOME=~/.virtualenvs
//配置路径
source /usr/local/bin/virtualenvwrapper.sh
//ubuntu18.04里,通过pip安装virtualenvwrapper得到的virtualenvwrapper.sh被安装在/.local/bin/目录下,需要修改上面添加在/.bashrc的内容中的路径即可:
mkvirtualenv --python=/usr/bin/python3 worldmodels
//制作了一个虚拟环境名为worldmodels,在这个虚拟环境模式下所有包仅存在于这个包下
https://blog.csdn.net/GZHermit/article/details/78915999
conda虚拟环境命令
https://blog.csdn.net/a200822146085/article/details/89048172
virtualenvwrapper的虚拟环境使用命令
(3)安装程序包
1.sudo apt-get install cmake swig python3-dev zlib1g-dev python-opengl mpich xvfb xserver-xephyr vnc4server
2.cd WorldModels
//进入这个文件夹好根据requirements.txt里所需的包进行安装
3.pip install -r requirements.txt
//包比较多,耐心等一会 没想到这一次竟然没有报错,之前在安装gym时一直过不去,可能和python版本与路径有关,也证明配好路径非常重要。
没想到这一次竟然没有报错,之前在安装gym时一直过不去,可能和python版本与路径有关,也证明配好路径非常重要。
(4)生成随机训练数据
对于这个赛车问题,VAE和RNN都可以使用随机生成的训练数据——也就是在每个时间节点随机采取动作所生成的观测数据。实际上,我们可以使用伪随机动作,使车在初始状态就能加速离开起跑线。
每一张图片保存的格式
由于VAE和RNN独立于决策控制器,我们需要确保遇到各种各样的观测结果,并且选择不同行动来应对,并将结果保存为训练数据。
要生成随机策略,请从命令行运行以下命令:
python 01_generate_data.py car_racing --total_episodes 2000 --time_steps 300
如果你的服务器没有显示结果,你可以运行以下命令:
xvfb-run -a -s"-screen 0 1400x900x24"python01_generate_data.py
car_racing --total_episodes2000 --time_steps300
以上命令将会产生2000个策略,保存在200个批次中,每个批次10个)。
在./data文件夹中,你会看到以下文件(*为批次号):
obs_data_*.npy (此文件将64 * 64 * 3图像存储为numpy数组)
action_data_*.npy (此文件存储三维动作) 从这一步就会发现网上的运行教程不严谨之处了,没有办法识别参数start_batch 0,去掉后正常运行,不知道是我这边有哪些环境没有配置好?
从这一步就会发现网上的运行教程不严谨之处了,没有办法识别参数start_batch 0,去掉后正常运行,不知道是我这边有哪些环境没有配置好?
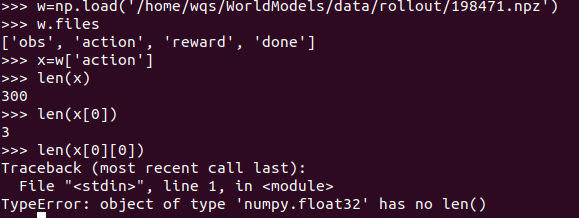
import numpy 后可以用pyton脚本查看其中文件具体内容,其中的一个文件包含300个图片信息(一个图片64*64 *3 ),同时有300个动作与reward,done,为以后的训练提供数据。
(5)训练VAE
这里我们只需要用obs_data_*.npy就可以训练VAE。确保你已经完成了第四步,否则这个文件不在./data文件夹下。
在命令行中运行下列语句:
python 02_train_vae.py --new_model
在每一批从0到9的数据中都会训练出一个新的变分自编码器VAE。模型的权重保存在./vae/weights.h5中。“–new_model”参数表明从头开始训练模型。
如果文件夹中已经存在weights.h5,也没有声明“–new_model”参数,脚本将直接导入这个文件中的权重,继续训练现有的模型。这样的话,你就可以实现模型的迭代训练,而不需要对每批数据都重新运行。
VAE架构的相关参数都在 ./vae/arch.py文件里声明。
 如何打开h5文件?
如何打开h5文件?
(6)生成循环神经网络RNN数据
现在我们就可以利用这个训练好的VAE模型生成RNN模型的训练集。
RNN模型要求把经由VAE编码后的图像数据(z)和动作(a)作为输入,把一个时间步长前的由VAE模型编码后的图像数据作为输出。
运行这行命令可以生成这些数据:
python03_generate_rnn_data.py --start_batch–max_batch9
这一步需要把第0至9批的obs_data_.npy 和 action_data_.npy文件转成在RNN中训练所需要的格式。
这两组文件保存在./data(*是批量编号)
rnn_input_*.npy(存储了[z a]串联向量)
rnn_output_*.npy(存储了前一个时间步长的z向量)
(7)训练RNN模型
训练RNN只需要用到rnn_input_.npy和rnn_output_.npy文件。确认你已经完成了第六步,否则这个文件不在./data文件夹下。
在命令行运行:
python 04_train_rnn.py --new_model
在每一批从0到9的数据中都会训练出一个新的VAE。模型的权重保存在./rnn/weights.h5。“–new_model”表明从头开始训练模型。
和VAE训练很相似的是,如果文件夹中已经存在weights.h5,也没有声明“–new_model”标志,脚本将直接导入文件中的权重,继续训练现有的模型。这样的话,你就可以实现RNN模型的迭代训练,而不需要对每批数据都重新运行。
RNN循环神经网络模型的具体参数都在./rnn/arch.py文件里声明。
(8)训练控制器
运行下列代码将在你的机器上启动这个过程,并为变量选择合适的值。
python 05_train_controller.py car_racing --num_worker16–num_worker_trial4–num_episode16–max_length1000–eval_steps25
或者在服务器上运行,但不显示结果:
xvfb-run -s"-screen 0 1400x900x24"python05_train_controller.py
car_racing --num_worker16–num_worker_trial2–num_episode4–
max_length1000–eval_steps25
–num_worker 16:worker的个数不要超过可用内核的数量
–num_work_trial 2 :每个worker测试的群体成员的数量(num_worker * num_work_trial表示每一代群体的总规模)
–num_episode 4:为群体的每个成员进行打分的次数(分数将是该次打分的平均得分)
–max_length 1000:一次打分中最大时间步长
–eval_steps 25:每隔25步对权重进行评估
默认情况下,控制器每次运行都会从零开始,将进程的当前状态保存到controller目录的pickle文件中。这样你就可以通过指定相关文件,从上一次保存的地方继续训练。
每生成一代后,算法的当前状态和最佳权重的集合将会输出到./controller文件夹。
 其中第二篇教程太坑了,原来是他其中的‘-’打错了。。。
其中第二篇教程太坑了,原来是他其中的‘-’打错了。。。
 然后跟第一次同样的问题,断言报错,只能将其中哪一行断言注释掉。
然后跟第一次同样的问题,断言报错,只能将其中哪一行断言注释掉。
如果mpi报错:https://segmentfault.com/a/1190000000485292
(9)可视化结果
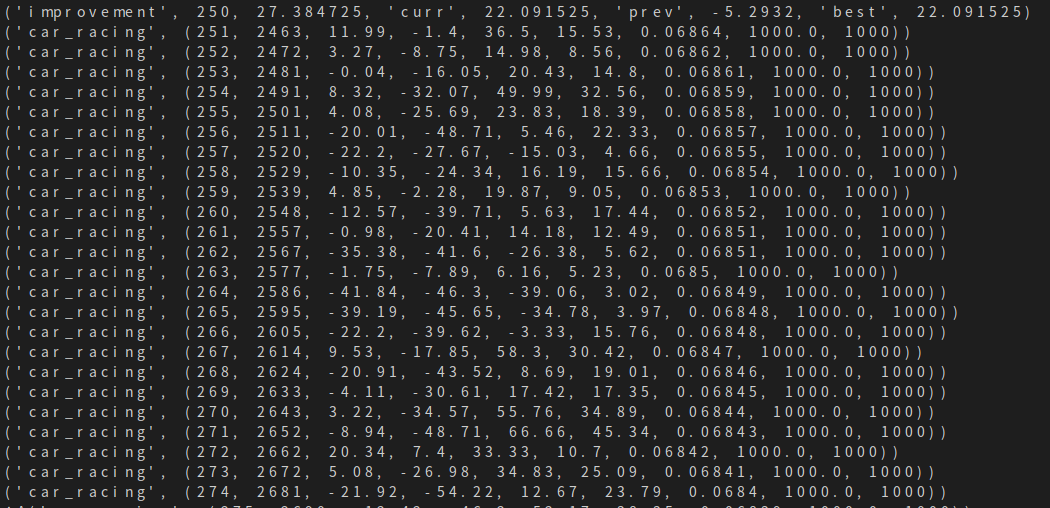
经过200代的训练,我已经训练出一个平均得分约为833.13的角色。我在谷歌云上使用配置为Ubuntu 16.04, 18 vCPU, 67.5GB RAM的机器,采用的是本文给出的步骤和参数。
在论文中,作者试图在2000代训练后达到约906的平均得分,这是迄今为止该环境下的最高分。他利用了稍高的规格设置(例如10,000集训练数据,群体大小设为64,64台核心机器,每次试验16次)。
如果你想可视化控制器的当前状态,那你只需要运行下列代码:
python model.py car_racing –filename
./controller/car_racing.cma.4.32.best.json --render_mode --record_video
–filename:想要添加到控制器的权重json的路径
–render_mode :在屏幕上显示环境
–record_video:输出mp4文件到./video文件夹,展现出每个片段
–final_mode:运行100次控制器测试,输出平均得分
最后
以上就是沉默大米最近收集整理的关于WorldModel世界模型代码训练实录1.前言2.我的环境3.流程的全部内容,更多相关WorldModel世界模型代码训练实录1.前言2.我内容请搜索靠谱客的其他文章。








发表评论 取消回复