Introduction
文章地址:From Facial Parts Responses to Face Detection- A Deep Learning Approach (ICCV 2015)
来自于香港中文大学汤晓鸥实验室做人脸检测的一篇文章,检测的结果简直丧心病狂啊,先贴一张图感受以下:

图1
正如图1中所示,这个人脸检测器对人脸的遮挡非常鲁棒,主要原因是借助了多个facial parts对人脸进行打分,然后得到最终的人脸检测结果.
系统主要包含了3个部分(统称为Faceness Net):
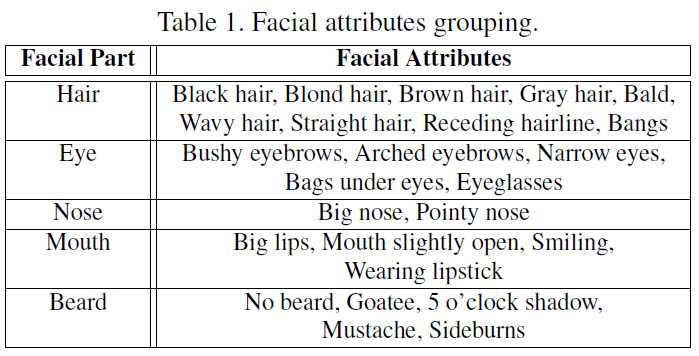
(1)根据attribute-aware深度网络生成人脸部件map图(partness map),如上图(b)中花花绿绿的颜色图,文章共使用了5个部件:hair,eye,nose,mouth,beard.
(2)通过part的结合计算人脸的score.部件与部件之间是有相对位置关系的,比如头发在眼睛上方,嘴巴在鼻子下方,因此利用部件的spatial arrangement可以计算face likeliness(楼主:如果人是倒立的怎么办??). 通过这个打分对原始的人脸proposal进行重排序.
(3)提纯人脸hypotheses
下面我们详细介绍这个网络.
Faceness Net
1. 生成partness map
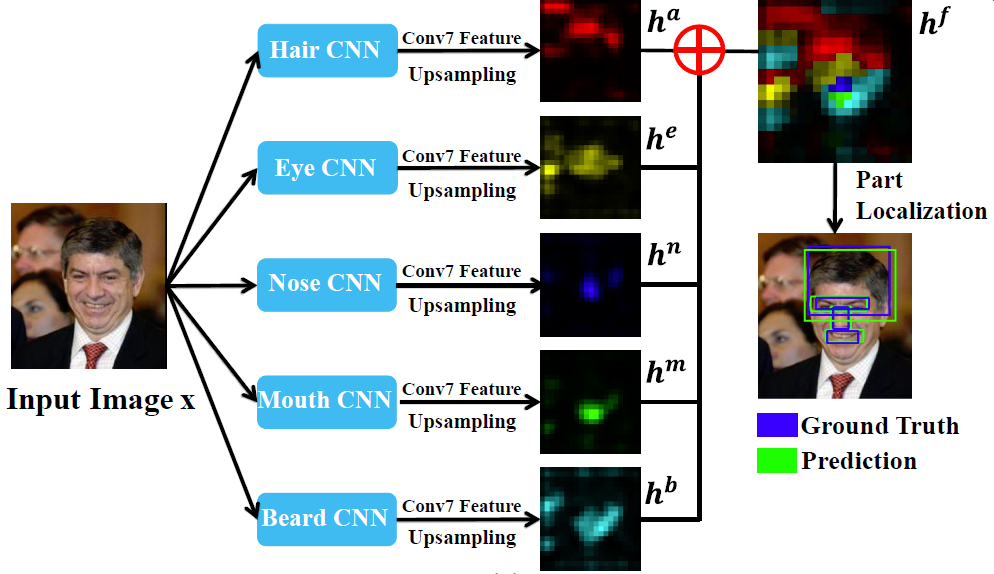
图2
图2主要显示了生成partness map的总体流程。这里作者一共训练了5个CNN model, 分别是头发,眼睛,鼻子,嘴巴和胡子这5个模型。CNN的具体结构如下图所示,这个网络是全卷积的神经网络.

图3
以hair CNN的训练为例,把头发区域的每个像素标记为正样本,非头发区域的像素标记成负样本,让这个网络来做像素的预测,直接预测出label map。各个facial part所包含的训练数据有以下属性(Table 1),比如头发就有9种,黑发/金发/甚至光头都包含进去了,因此学习是一个多分类的问题,比如说头发要把他分为以下9类中的一种, 优化的目标函数 cross-entropy loss =
∑Ni=1yilogP(yi=1|xi)+(1−yi)log(1−P(yi=1|xi))
再将上式model成sigmoid function,表示各个属性出现的概率.
这种属性的学习有一个好处是能够将人脸的差异以更加语义的属性的方式表示出来,如他可以帮助区分亚洲人和欧洲人.
训练好part-based CNN后,将一幅图像分别输入到5个part的CNN中,每个CNN都会输出表示一个脸部部件位置的partness map。这是通过对最后一个卷积层的label maps进行加权平均得到的.图2中的红色,黄色,蓝色,绿色,天蓝色的这些partness map图就表示了不同部件的位置, denoted as ha,he,hn,hm,hb。然后我们将这些partness maps 相加,就得到右边这个face label map,代表了人脸的位置。接着在这个map图上用生成proposals的方法,找到候选区域,通过对这些候选区域进行打分,完成对目标的定位。这就是生成Partness maps的整个流程。
2. Ranking Windows by Faceness Measure
利用partness map对候选框进行打分,是通过每个part map进行的空间位置先验,比如头发在脸的上方,眼睛在脸的中央,来进行人脸or 非人脸的打分(faceness score)。如图3,将打完分的part map进行相加,通过NMS(Non-Maximun Suppression,非极大值抑制)就可以将每个部位定位好的矩形框合并成一个大的矩形框,即为人脸的proposal。
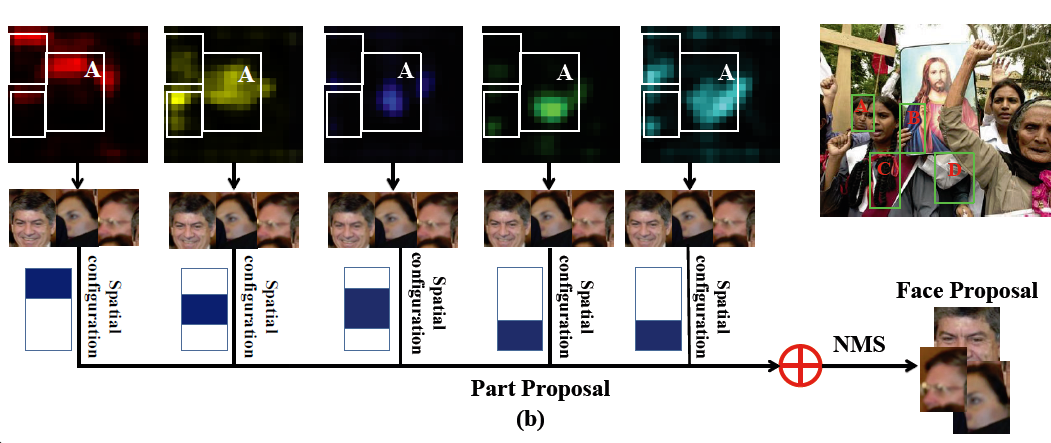
图3
首先使用现有的object proposal方法(比如selective search 和 edge box)在 map图上找到候选框。找到候选框之后,基于partness map生成得分由高到低排列的 face proposal集合,评判方法如下图所示, 以一种积分图的方式生成faceness score.
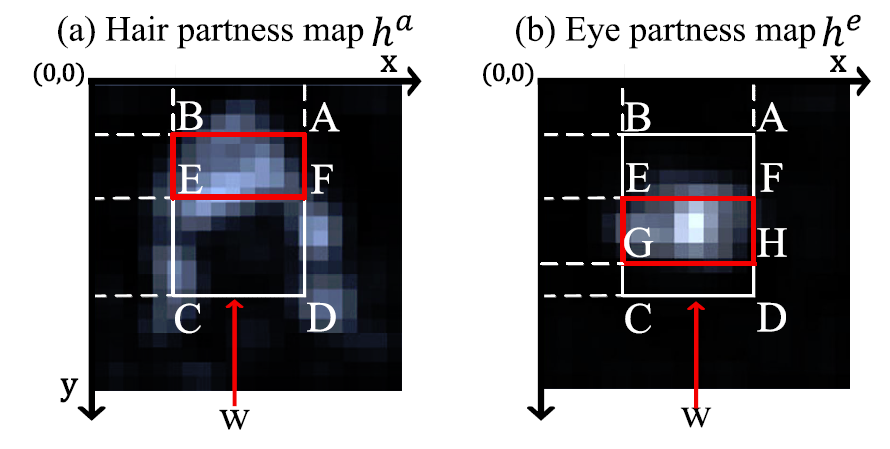
以头发为例,考虑头发的空间位置,已知头发在人脸的上方,其partness map上找到的proposal窗口为ABEF,则头发提供的faceness score为ABEF/FECD的积分值,如下式,分子的最后一项是I(xe,ye),分母的第三项是I(xf,yf).
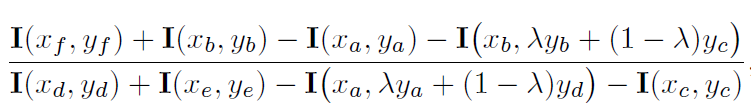
同理,眼睛长在脸的中间部分,即窗口为EFGH.那么其faceness score就是EFGH/(ABEF+HGCD)的积分值。
部件的Faceness score得分越高则表明与人脸的相交比例越大。假如ABEF里面不是头发,那么ABEF里面的数值将会很小,这样就会使得得分很低,只有当ABEF正确的框住可头发,得分才能变得高。接下来的问题就是如何确定E,F这两个点,即公式中
λ
,使得不同部件的空间配置合理,能够区分人脸和非人脸的置信度最大。
在这里,我们通过学习的方法来得到
λ
。具体做法就是给定一个训练集(w,r,h),w指的是人脸的boundingbox,r是人脸和非人脸的label,h是我们知道头发所在的区域,我们的目的就是学习到一个参数
λ
使得有头发的地方获得一个高分。而且我们知道
λ
是一个服从0-1均匀分布的随机变量,所以这个问题也就是求最大后验的问题。用最大后验来求解 lamda:

3. Refine face detection
最后作者通过使用来自AFLW的人脸图片和来自于PASCAL VOC 的非人脸数据来finetune AlexNet网络来对产生的proposal进行提纯,提高检测准确率.
Experiments
Training dataset:
(1)对于部件检测器的训练,用的是CelebFaces,包含87628张图片,我们为所有的这些图片标上Table 1中所列的25种attributes,然后将这些属性划分到5个part的各个类中,这样就完成了attribute-aware network训练数据的准备工作。我们随机抽取其中75000张作为训练,余下的作为验证。
(2)对于人脸检测器的训练,我们从AFLW dataset中选取13205张图片并保证不同姿态的图片分布均匀,另外PASCAL VOC 2007 dataset中随机选取5771张图片。
Part response testing dataset:2827张LFW images,包含了头发和胡子的标注,另外其他人脸部件如眼睛等也进行人工标注,并通过68个danse facial landmarks来guide。
Face proposal and detection testing datasets:FDDB,AFW和PASCAL
具体实验结果请参考原文。
最后
以上就是开朗大白最近收集整理的关于【论文笔记】From Facial Parts Responses to Face Detection(ICCV 2015)的全部内容,更多相关【论文笔记】From内容请搜索靠谱客的其他文章。








发表评论 取消回复