主要介绍image caption最近的几篇文章,及其相关的应用。
- 1.Google NIC,Show and Tell: A Neural Image Caption Generator [CVPR2015]。code
- 2.Hard(soft)-Attention,Show, Attend and Tell: Neural Image Caption Generation with Visual Attention [ICML2015]。大神实现code
- 3.Review Net,Review Networks for Caption Generation [NIPS2016]。code
- 4.Adaptive Attention,Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning [CVPR2017]。code
- 5.SCST,Self-critical Sequence Training for Image Captioning [CVPR2017]。大神实现code
- 6.LSTM-A,Boosting Image Captioning with Attributes [ICCV2017]。
- 7.captionGAN,Speaking the Same Language:Matching Machine to Human Captions by Adversarial Training [ICCV2017]。code
- 8.Remote Sensing Caption,Exploring Models and Data for Remote Sensing Image Caption Generation [TGARS2017]。homepage
- 9.Medical Image Caption,On the Automatic Generation of Medical Imaging Reports [ACL2018]。
- 10.BUTD_Attention,Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering [CVPR2018]。code
文章要做的事情(image captioning):
输入:image 输出:sentence
以Google NIC中可视化的实验结果为例,image captioning的例子如下所示。

Google NIC
Google NIC的framework如下所示。
![show_and_tell_framework]](https://img-blog.csdn.net/20180612164203650?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Z1eGluNjA3/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
这篇文章是基于encoder-decoder结构方法,encoder端用CNN提取图像的特征,然后再将这个特征输入到decoder端,通过LSTM decoder出word level的feature,最后利用softmax对这个feature将分类,即可以产生文本,文章中提到的几个点。
- 在训练的过程中采用BeamSearch,beam_size选择要合理,并不是越大越好。
- 将前一个状态的word level的feature输入到LSTM的时候,需要用word-embedding。
- 文章明确指出,训练的数据越多对image captioning的实验结果就越好,文章还说要是有用单模态的数据做无监督的image captioning的话,将会非常有意义。
- 这个方法能产生diversity的caption,文章中列举出了一个生成的文本,准确,但是ground-truth并不存在。
Hard(soft)-Attention
Hard(soft)-Attention的framework如下所示。
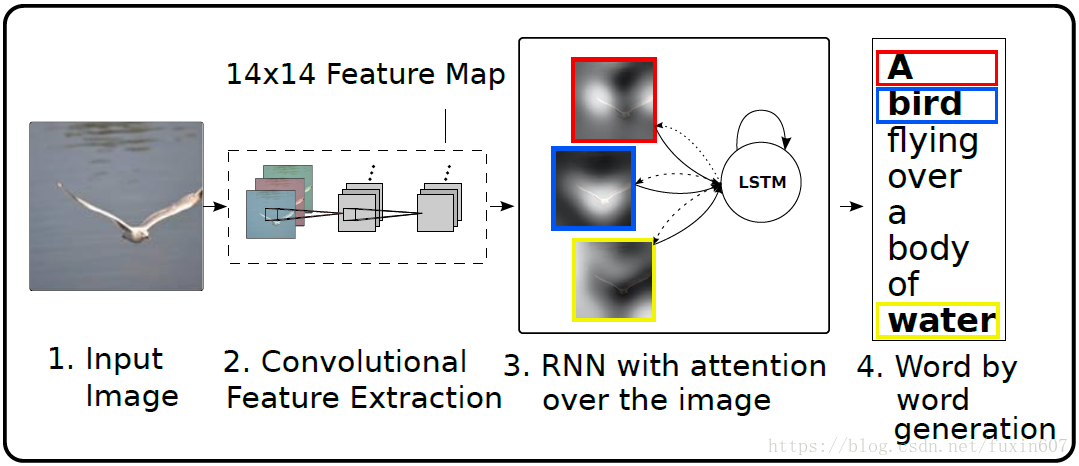
这篇文章的束腰思想是在14x14x512(196x512)这样的卷积块上面加入attention的机制,即学习196(可以理解图像中的区域的个数)个权重,文章中分别采用了soft-attention和hard-attention的方式。soft-attention是学习196个加权和为1的权重,hard-attention是选择196个中可能行最大的区域,这个区域的权重为1,其他地方的权重为0。
最后
以上就是爱笑帅哥最近收集整理的关于image caption研究进展的全部内容,更多相关image内容请搜索靠谱客的其他文章。



![[Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)


![UC Berkeley CS 61A (2022 Fall) Lecture 3 Control [Notes]Print and NoneMiscellaneous Python FeaturesConditional Statements](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)

发表评论 取消回复