这篇论文提出了Attention机制对于Encoder-Decoder进行改进。在Encoder-Decoder结构中,Encoder将输入序列编码为
hn
h
n
。这样做的一个潜在问题是,如果原始序列中包含的许多信息,而
hn
h
n
的长度又是一定的,那么
hn
h
n
就存不下我们所需的所有信息。
利用Attention机制,Decoder可以在输入序列中选取需要的特征,提高了Encoder-Decoder模型的性能。
首先,让我们先来回顾下LSTM的机制。LSTM的结构图如下图所示:
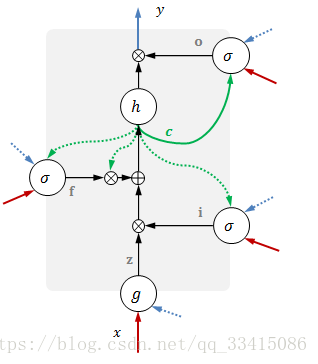
* 红色表示输入
* 蓝色表示输出
* 绿色表示记忆单元
* 虚线表示前一时刻的变量
每个组件的具体表达式如下:
| 意义 | 表达式 |
|---|---|
| 数据输入 | z=g([xt,yt−1]) z = g ( [ x t , y t − 1 ] ) |
| 输入门 | i=σ[xt,yt−1,ct−1] i = σ [ x t , y t − 1 , c t − 1 ] |
| 遗忘门 | g=σ[xt,yt−1,ct−1] g = σ [ x t , y t − 1 , c t − 1 ] |
| 输出门 | o=σ[xt,yt−1,ct−1] o = σ [ x t , y t − 1 , c t − 1 ] |
包含两种非线性激活函数:
σ(u)=11+e−u
σ
(
u
)
=
1
1
+
e
−
u
g(u)=h(u)=tanh(u)=ez−e−zez+e−z
g
(
u
)
=
h
(
u
)
=
t
a
n
h
(
u
)
=
e
z
−
e
−
z
e
z
+
e
−
z
方括号[ ]表示线性变化,具有一般形式:
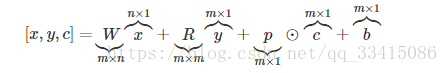
每个函数具有不同参数W,R,p, b,通过训练获得。
LSTM的一种变体 attention LSTM
LSTM新增了一个和输入同尺度的注意力权重
αt
α
t
,由输入和输出/隐状态计算得到:
αt=softmax(k(xt,yt−1))
α
t
=
s
o
f
t
m
a
x
(
k
(
x
t
,
y
t
−
1
)
)
, 其中k是计算相关性的网络
用这个权重给原始输入加权
xtˆ=ϕ(at,xt)
x
t
^
=
ϕ
(
a
t
,
x
t
)
使用加权的输入代替原来的
xt
x
t
,那么LSTM的结构如下图所示:
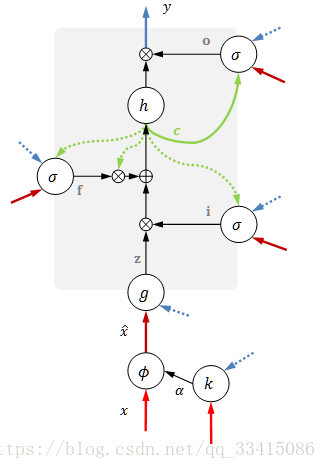
让我们再回到论文的内容
结构
从输入到输出依旧经过decoder及encoder两个部分。
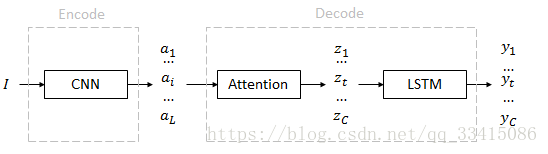
* 特征(annotation): {
a1...ai...aL
a
1
.
.
.
a
i
.
.
.
a
L
}, 每个
ai
a
i
都是一个D维特征,共有L个,描述图像的不同区域。
* 上下文(context): {
z1...zt...zC
z
1
.
.
.
z
t
.
.
.
z
C
},每个
zi
z
i
也是一个D维特征,共有C个,表示每个单词对应的上下文。
* 输出(caption): {
y1...yt...yC
y
1
.
.
.
y
t
.
.
.
y
C
}。
yt
y
t
组成一句“说明”(caption)。句子长度C不定。每个单词
yt
y
t
是一个K维概率,K是词典的大小。
从输入图像 I 到 a
特征a直接使用现成的VGG网络中conv5_3层的14 * 14 * 512特征。所以,区域数量 L = 14 * 14 = 196,维度 D = 512
从 a 到 z
每个特征向量
ai
a
i
对应的权重
αi
α
i
是根据聚焦模型
fatt
f
a
t
t
计算得到的。
eti=fatt(ai,ht−1)
e
t
i
=
f
a
t
t
(
a
i
,
h
t
−
1
)
αti=exp(eti)∑Lk=1exp(etk)
α
t
i
=
e
x
p
(
e
t
i
)
∑
k
=
1
L
e
x
p
(
e
t
k
)
计算得到权重之后,我们就可以计算
ztˆ=ϕ({ai},{αi})
z
t
^
=
ϕ
(
{
a
i
}
,
{
α
i
}
)
ϕ
ϕ
函数将在下面部分讨论,总共有两种形式 hard 以及 soft.
权重
αi
α
i
记录了对每个特征向量
ai
a
i
的关注
从 z 到 y
z作为LSTM的输入,y作为LSTM的输出
参考博客:
【图像理解】之Show, attend and tell算法详解
最后
以上就是调皮小懒猪最近收集整理的关于《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》阅读笔记的全部内容,更多相关《Show,内容请搜索靠谱客的其他文章。







![[Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)
发表评论 取消回复