这篇文章是2015年ICML上的一篇文章,把attention机制引入到图像领域的文章,作者Kelvin Xu 、Yoshua Bengio等人,来自多伦多大学和蒙特利尔大学。
Image caption是计算机视觉的最初始任务,不仅要获得图片里的物体,还要表达他们之间的关系。目前现存的方法大都是encoder — decoder架构,利用CNN、RNN、LSTM等神经网络完成caption工作,比如说只使用CNN对图像进行特征提取,然后利用提取的特征生成caption,还有结合CNN和RNN的,使用CNN提取图像特征,将Softmax层之前的那一层vector作为encoder端的输出并送入decoder中,使用LSTM对其解码并生成句子,这种方法也是本文所采取的方法,只是在此基础上嵌入了soft和hard attention机制。
除了神经网络之外,caption还有两种典型的方法:
1、使用模板的方法,填入一些图像中的物体;
2、使用检索的方法,寻找相似描述。
这两种方法都使用了一种泛化的手段,使得描述跟图片很接近,但又不是很准确。所以作者在此基础上提出了自己的模型架构,将soft 和hard attention引入到caption,并利用可视化手段理解attention机制的效果。
模型:
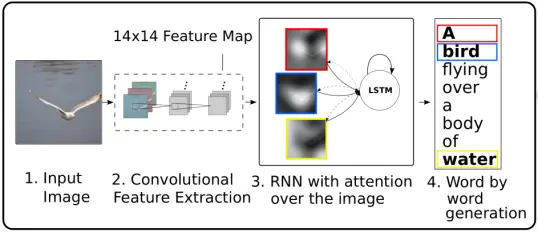
模型的总体架构如上图所示,也是由encoder和decoder组成。
Encoder,模型使用CNN来提取 L 个 D 维的特征vector作为注释向量,每一个都对应图像的一个区域,如下式。
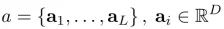
与此前的工作使用Softmax层之前的全连接层提取图像特征不同,本文所提取的这些vector来自于 low-level 的卷积层,这使得decoder可以通过选择所有特征向量的子集来选择性地聚焦于图像的某些部分,也就是将attention机制嵌入。
Decoder,解码阶段用LSTM网络生成caption,集合为下式,其中C是句子长度,K是词表大小,y是各个词的one-hot编码所构成的集合。
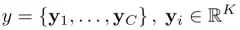
LSTM模型结构如下,对应输入门、输出门、忘记门数学公式如下:
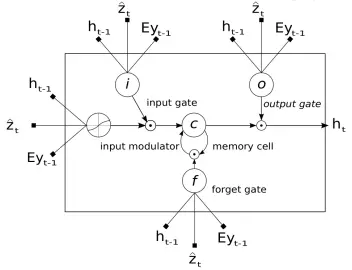
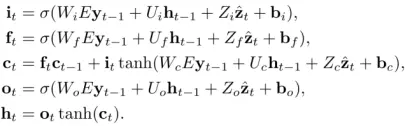
输入、遗忘和输出门由sigmod激活,所以得到的值在0—1之间,可以直接作为概率值,候选向量ct 和ht由tanh激活,值在-1—1之间。三个输入量分别是,Eyt−1是look-up得到词 yt−1的 m 维词向量;ht−1是上一时刻的隐状态;z^t∈RD是LSTM真正意义上的“输入”,代表的是捕捉了特定区域视觉信息的上下文向量。
针对最后一个式子的隐含变量值,作者给出了隐状态和细胞状态的初始值的计算方式,使用两个独立的多层感知机,感知机的输入是各个图像区域特征的平均:
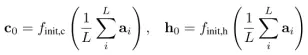
根据以上,我们就可以通过最大概率求得当前时刻输出的词,并作为下一时刻的输入,从而获得caption结果,如下式。
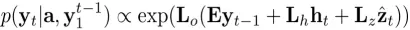
Attention,上文说到zt是LSTM真正的输入,是一个和时间相关的动态变量,不同时间关注在不同的图像区域内,那么这里就可以和attention结合起来,规定特定时间内关注某个区域。实现attention的方式,就是:zt由时间和位置区域决定,对于每个时间的每个区域都定义一个权重值ati。为了满足权重的归一化,我们通过softmax函数实现,如下式,Softmax的输入需要包含位置信息和前一时刻隐层值:
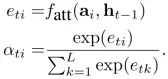
zt就可以表示出来,而φ函数怎么定义使得hard attention和soft attention的产生:
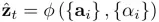
Hard attention,这里权重ati所起的作用的是否被选中,只有0.1两个选项,所以引入了变量st,i,当区域i被选中时为1,否则为0。
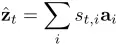
那么问题就是st,i什么时候是1,什么时候为0。在文章里,作者将st视作隐变量,为参数是位置信息的多元伯努利分布,公式如下:
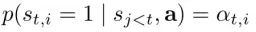
针对多元伯努利分布,利用最大似然估计,求得变分下限,类似于EM的思想,下式通过杰森不等式求得。
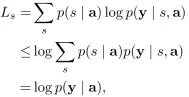
然后对参数矩阵求梯度进行优化,
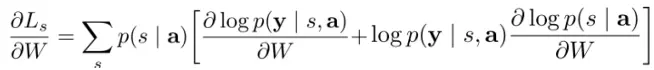
用 N 次蒙特卡洛采样来近似:
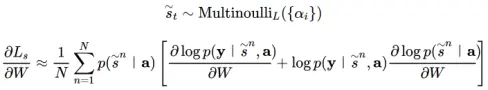
在蒙特卡洛方法估计梯度时,可以使用滑动平均来减小梯度的方差:
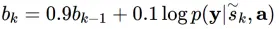
为进一步减小方差,引入多元贝努利分布的熵H(s),而且对于一张给定图片,50%的概率将s设置为它的期望值α。这两个技术提升了随机算法的鲁棒性,最终的结果是:
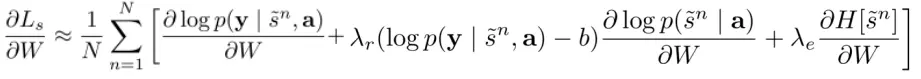
λr和λe是交叉验证设置的两个超参数,这个学习规则类似于强化学习。
Soft attention,在这里,不像hard对特定时间特定区域只有关注和不关注,soft里对每个区域都关注,只是关注的重要程度不一样,所以此处的权重ati就对应着此区域所占比重,那么zt就可以直接通过比重加权求和得到。
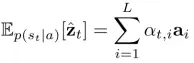
现在的模型为光滑的,可以使用BP算法通过梯度进行学习。文章定义了归一化加权几何平均值(NWGM)
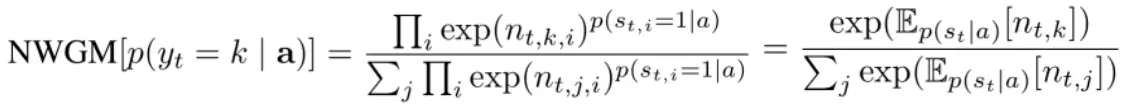
该式表示caption的结果可以通过文本向量很好近似,也就是caption结果有效。也表示soft attention是关于attention位置的边缘似然的近似。在训练soft attention时,文章引入了一个双向随机正则,目的是为了让attention平等的对待图片的每一区域。另外,还定义了阈值β
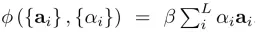
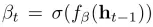
,目的是让解码器决定是把重点放在语言建模还是在每个时间步骤的上下文中。
Soft attention最终是通过最小化下式进行训练。
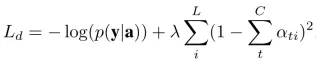
实验:
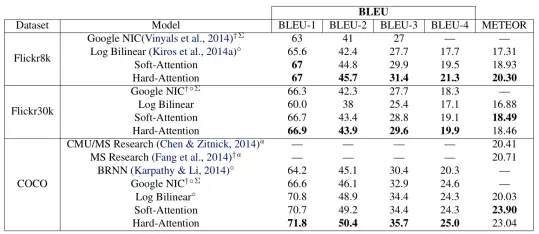
作者用了三个数据集进行实验,Flickr8k采用RMSProp优化方法, Flickr30k和COCO采用Adam进行优化,用vgg在ImageNet上进行预训练,采取64的mini-batch,用bleu和meteor作为指标进行评分,下表是实验结果,可以看出本文所提出的方法取得了很好的结果。
可视化,为了更好地了解attention的效果,我们对模型进行了可视化,如下图所示,可以看出attention机制可以学习到类似于人注意力一样的信息。


结论:
本文作者经机器翻译的attention机制启发,将其应用到image caption领域,并提出了hard 和 soft 两种attention机制,相比较来说,hard attention更难训练,所以他的效果也更好。这篇文章无疑是打开了attention图像领域的先河。
最后
以上就是粗暴唇彩最近收集整理的关于图像标注:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention的全部内容,更多相关图像标注:Show,内容请搜索靠谱客的其他文章。





![[Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)


发表评论 取消回复