参考资料:
[1502.03044v3] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (arxiv.org)
(PDF) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (researchgate.net)
sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning: Show, Attend, and Tell | a PyTorch Tutorial to Image Captioning (github.com)
danielajisafe/Image-Captioning-Model (github.com)
贡献:
1、提出一种框架下的两种基于注意力的图像字幕生成方法:
a、一种可以通过标准反向传播可训练的“软”确定性的注意力;
b、一种可以通过最大化近似可变的下界或者REINFORCE的可训练的“硬”随机注意力机制;
2、将注意力可视化表示;
3、在三个数据集Flickr8k、Flickr30k、MS COCO达到最好结果;
模型:
模型的总体结构:
由卷积神经网络提取图片特征,然后由带注意力机制的循环神经网络一个单词接着一个单词生成。
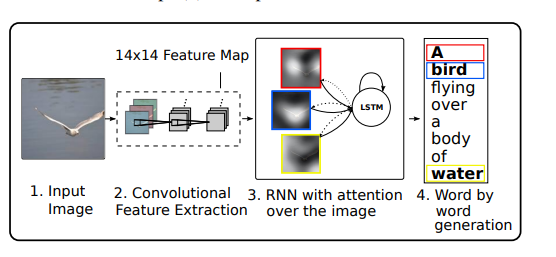
两种注意力结构:
硬注意力和软注意力的区别:
1、硬注意力得到的是类似于one-hot向量的权值。而软注意力得到的是softmax的输出权重值。随机硬注意力需要做Multinoulli的假设,也就是说只有一个等于1(事件发生),其余的都等于0(事件不发生)。
2、硬注意力的随机是因为使用Monte Carlo采样的方式求解,而软注意力的确定是因为使用期望的方式求解 z ^ t widehat {z}_t z t。
1、随机硬注意力:
p
(
s
t
,
i
=
1
∣
s
j
<
t
,
a
)
=
α
t
,
i
z
^
t
=
∑
i
s
t
,
i
a
i
.
p(s_{t,i}=1|s_{j<t}, pmb{a})=alpha_{t,i}\ widehat{z}_t=sum_is_{t,i}pmb{a}_i.
p(st,i=1∣sj<t,aa)=αt,iz
t=i∑st,iaai.
公式的
s
t
s_t
st指的是模型注意到的第t个词的位置。
s
t
,
i
s_{t,i}
st,i指的是one-hot变量,当图片中的第
i
i
i个位置被用来提取视觉特征则置1。
2、确定软注意力:
学习随机软注意力需要每次对注意力位置
s
t
s_t
st进行采样,软注意力直接取上下⽂向量
z
^
t
widehat{z}_t
z
t的期望,是平滑和可微的:
E
p
(
s
t
∣
a
)
[
z
^
t
]
=
∑
i
=
1
L
α
t
,
i
a
i
E_{p(s_t|a)}[pmb{widehat{z}}_t]=sum_{i=1}^{L}alpha_{t,i}pmb{a}_i
Ep(st∣a)[z
z
t]=i=1∑Lαt,iaai
并且使用softmax进行归一化。将第 k 个单词预测的 softmax 的归⼀化加权⼏何平均 值(NWGM)写为:
N
W
G
M
[
p
(
y
t
=
k
∣
a
]
=
e
x
p
(
E
p
(
s
t
∣
a
)
[
n
t
,
k
]
)
∑
j
e
x
p
(
E
p
(
s
t
∣
a
)
[
n
t
,
j
]
)
NWGM[p(y_t=k|pmb{a}]=frac{exp(E_{p(s_t|a)}[n_{t,k}])}{sum_jexp(E_{p(s_t|a)}[n_{t,j}])}
NWGM[p(yt=k∣aa]=∑jexp(Ep(st∣a)[nt,j])exp(Ep(st∣a)[nt,k])
将注意力嵌入到decoder中:
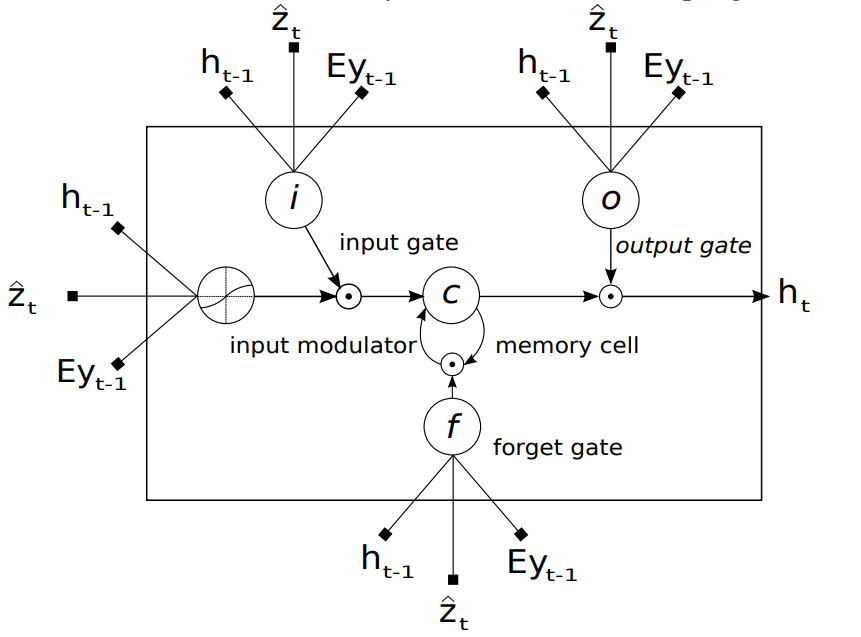
如图所示,将注意力结合LSTM得到decoder。图中的
z
t
^
widehat{z_t}
zt
由注意力机制
f
a
t
t
f_{att}
fatt作用在图片块上生成:
e
t
i
=
f
a
t
t
(
a
i
,
h
t
−
1
)
a
t
i
=
e
x
p
(
e
t
i
)
∑
k
=
1
L
e
x
p
(
e
t
k
)
z
^
t
=
ϕ
(
a
i
,
α
i
)
begin{aligned} e_{ti}&=f_{att}(pmb{a}_i, h_{t-1}) \ a_{ti}&=frac{exp(e_{ti})}{sum_{k=1}^{L}exp(e_{tk})}\ widehat{z}_t&=phi({pmb{a}_i},{alpha_i}) end{aligned}
etiatiz
t=fatt(aai,ht−1)=∑k=1Lexp(etk)exp(eti)=ϕ(aai,αi)
注:多项式分布:多项式分布是二项式分布的推广。二项式做n次伯努利实验,规定了每次试验的结果只有两个。如果现在还是做n次试验,只不过每次试验的结果可以有m个,且m个结果发生的概率互斥且和为1,则发生其中一个结果X次的概率就是多项分布。概率密度函数是:
P
(
X
1
=
k
1
,
X
2
=
k
2
,
⋯
,
X
n
=
k
n
)
=
n
!
(
k
1
!
)
(
k
2
!
)
⋯
(
k
n
!
)
∏
i
=
1
n
(
p
k
i
)
P(X_1=k_1,X_2=k_2,cdots,X_n=k_n)=frac{n!}{(k_1!)(k_2!)cdots(k_n!)}prod limits_{i=1}^n(p_{k_i})
P(X1=k1,X2=k2,⋯,Xn=kn)=(k1!)(k2!)⋯(kn!)n!i=1∏n(pki)
最后
以上就是丰富魔镜最近收集整理的关于《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》论文阅读(详细)的全部内容,更多相关《Show,内容请搜索靠谱客的其他文章。
![[Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)


![UC Berkeley CS 61A (2022 Fall) Lecture 3 Control [Notes]Print and NoneMiscellaneous Python FeaturesConditional Statements](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)




发表评论 取消回复