Sphinx4语音识别的框架
1 sphinx4基本模块
Sphinx4主要由三个基本模块构成:FrontEnd,Decoder,Linguist。
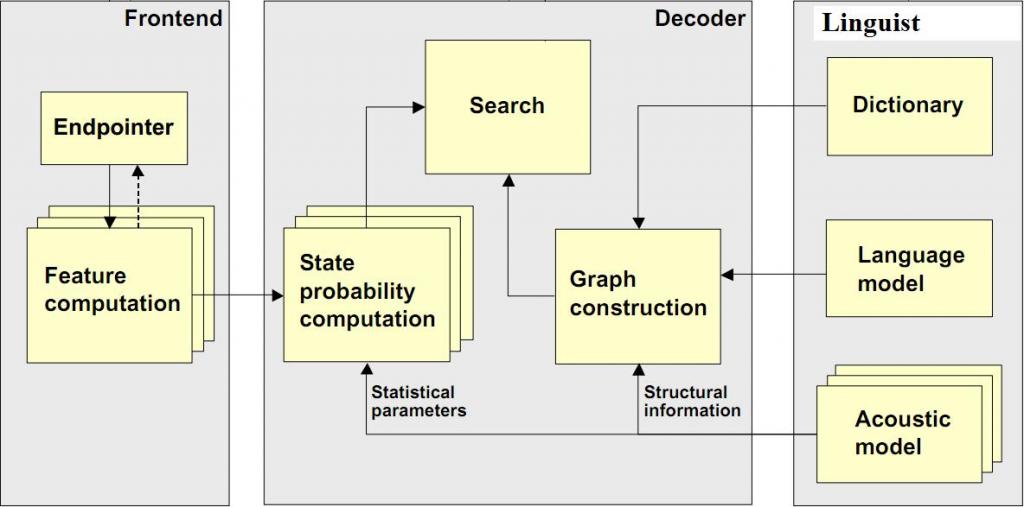
FrontEnd接受信号的输入并且转化为特征序列。Linguist把任何类型的标准语言模型,字典的发音信息以及一些声学模型的结构信息转换为一个SearchGraph。在Decoder 中的SearchManager负责用FrontEnd产生的特征以及Linguist生成的SearchGraph进行实际的decoding工作,产生结果。
2 Linguist的基本构成
Linguist是由三个可插拔的组件构成:LanguageModel,Dictionary,AcousticModel。
1)LanguageModel提供了单词上得语言结构。主要有2种典型的实现:graph-driven grammars和stochastic N-Grammodels。graph-driven grammars代表一个有向图,图的节点代表一个单词,链接代表发生单词转换的概率。stochastic N-Gram models提供了在给定前n-1个单词时,该单词发生的概率。
2)Dictionary提供单词的发音。这些发音把单词分成一个AcousticModel里面unit的序列。
3)AcousticModel提供了语音单元与一个HMM模型的映射关系。HMM是一个有向图,节点代表一个HMM状态,链接代表一个状态转移概率。每一个HMM状态都可以对一个特征得分(实际的实现在HMMState类里面)。Sphinx4现在提供一个单独的AcousticModel实现,能够载入并使用Sphinx3 trainer生成的模型。
4)SearchGraph是由LanguageModel所代表的语言结构以及AcousticModel的拓扑结构(基本发声单元的HMMs)。Linguist也会使用词典(Dictionary)把LanguageModel的单词映射成AcousticModel元素的序列。
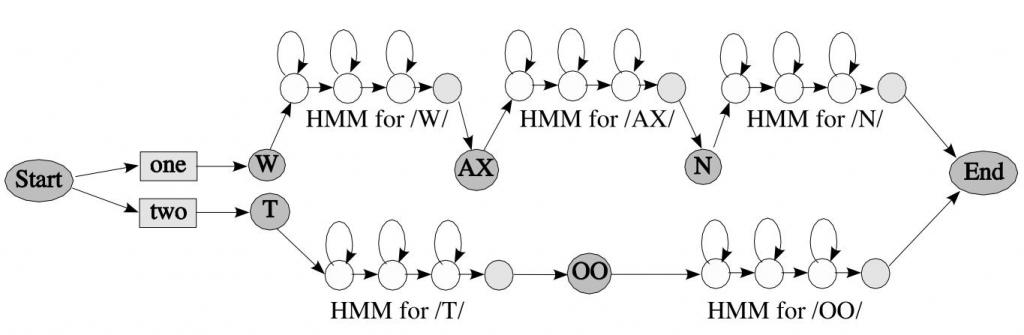
SearchGraph是一个有向图,每一个节点叫做SearchState,可以分为emitting或non-emitting状态。Emitting状态能够对语音特征进行打分;而non-emitting状态仅仅代表了高层的语言结构,例如单词,音素,这些不能够直接对语音特征进行打分。链接代表了状态间的转移概率。
参考:
Sphinx-4:A Flexible Open Source Framework for Speech Recognition.
最后
以上就是迷你鞋垫最近收集整理的关于Sphinx4语音识别的框架的全部内容,更多相关Sphinx4语音识别内容请搜索靠谱客的其他文章。








发表评论 取消回复