从最起初的一声巨响,到梵音天籁,到耳旁的窃窃私语,到妈妈喊我回家吃饭,总离不开声音。声音是这个世界存在并运动着的证据。
1.1 大音希声
假设我们已经知道了声音是什么。
我们可以找到很多描述声音的词语,如“抑扬顿挫”、“余音绕梁”。当我们在脑海中搜刮这类词语时,描述对象总绕不过这两个:人的声音和物的声音。人的声音,就是语音;物的声音,多数想到的是音乐。这样的选择源于人的先验预期:语音和音乐才最可能有意义,有意义的才去关注。估计不会有人乐于用丰富的辞藻来描述毫无意义的声音。所以,语音研究的意义在于语音本身所传递的意义是什么,以及语音为什么能够传递意义。
声音有很多,每时每刻每次振动都能产生声音,可是有意义的声音实在不多。我们可以使用机器随机生成一段声音,心想着也许这段声音可以产生一些文字内涵。这个想法与很多年前就开始忙不迭地敲打莎士比亚巨著的大猩猩没有差别。不管重复多少次,这些随机的声音听起来都是杂音,没意思。很显然,在这样一个庞大的声音空间中,有意义的语音和音乐只是其中极微小的一点,这也是“大音希声”的一种解释吧。偏偏人类就能毫不费力找到那个点,并且能说会道,这种搜索能力也是千百年来才积攒下来的。不过就算是这么一个小点,古往今来的文学和音乐经典也并未占据多少地盘,这也使得语音语言的研究、文学音乐的创作有着广阔的发挥空间。
从大音希声中,我们可以得到以下一些启示:语言是高度概括和规范化的产物,它的熵值(简单理解为系统的混乱程度)极低,所以语言本身反映了一种思维方式,比如不同语言对“过去时”、“现在时”、“将来时”的处理方式体现了对时间的不同感受,不同语言对主谓宾的排序体现了对空间层次的不同感知;还有,语音在声音空间中是高度集中的,这使得我们在解析一段语音时不用搜索整个声音空间,少了一些盲目性(不过语言本身的博大精深已让人叹为观止了)。
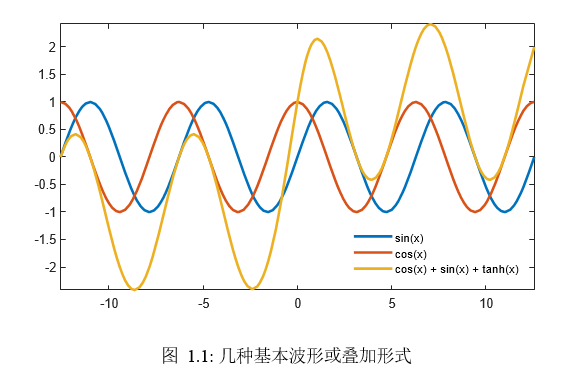
声音以波的形式传播,即声波(Sound Wave)。当我们以波的视角来理解声音时,却又大繁若简起来:仅凭频率(Frequency)、幅度(Magnitude)、相位(Phase)便构成了波及其叠加的所有,声音的不同音高(Pitch)、音量(Loudness)、音色(Timbre)也由这些基本“粒子”组合而来。图1.1展示了几种简单的波形,世上形形色色的声波都可以“降解”到基本波身上,这也是傅里叶变换(Fourier Transform)的基本思想。不同的声波有不同的频率和幅度(决定音量),人耳也有自己的接受范围。人耳对频率的接受范围大致为 20 Hz至20 kHz,于是以人为本地将更高频率的声波定义为超声波(Ultrasound Wave)、更低频率的声波定义为次声波(Infrasound Wave),虽然其他动物可以听到不同范围的声音;人耳对音量的接受范围已经进化得适应了地球上的常规声音,小到呼吸声、飞虫声, 大到飞机起飞、火箭发射的声音(已经不是地球默认配置),再往上,人的身心就越来越承受不住了,为了衡量音量的大小,再一次以人为本地将人耳所能听到的1kHz纯音的音量下限定义为0dB。
1.2 产生语音
语言是人类的标志性能力,是一项发明,只不过这个发明是人类群体在长远的历史当中不断打磨而成,趋近于稳定而不得稳定,因为新的人和新的思想总是不断涌现,语言随之而进化,根据社会的需要不断做出改变,比如小到每年产生的新词(对于汉语来说,常用的字基本已经固定不变,是所有词句的基本单元,新加的词也不过是对已有单字进行组合,再赋予新的意义,这与利用字母组装成新词有所区别),大到一种语言的消亡和另一种语言的诞生(计算机语言也是一种情形)。当语言通过声音的形式表达出来,即为“语音”,是指由人类发出的、承载特定语义的声音,其中语义不仅可以借助文字本身来传递,也可以借助声音的音高、音强、音长、音色及其组合来表示不同的情感、态度等信息。
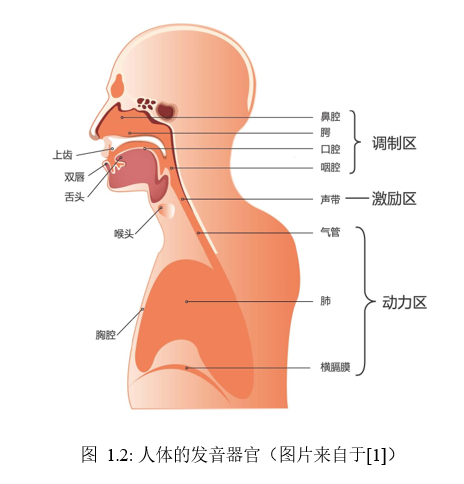
图1.2展示了人体的发音器官及其对声音的影响区域。简而言之,肺部产生气流动力,经过气管引起声带振动形成声源(通常称为激励,图中激励区也叫声源区),最后经过声道(咽腔、口腔、鼻腔等区域)调制后由口唇辐射出来,产生了我们所听到的语音。当我们说话、唱歌时,基本上所有的发声器官都被调用了;当我们哼着小曲时,口腔可以不动,而只通过调动鼻腔来调节音调;当我们捂着口鼻时,气流停止,没了动力,渐渐就发不出声音了。
已知了人体发音器官的结构图,便可以仿生复制出语音发生器,然而仅仅只是功能上复制出这些发音器官以及将它们联系在一起的神经系统已是很难,而模拟产生让各个器官能够联动协作的神经信号就更难了。
1.3 看见语音
语音是用来听的,看不见,摸不着,但是我们可以看看语音的保存形式。自然存在的语音是连续的波动,具有波的所有属性。声波可以保存成离散的数字,即模数转换(Analog to Digital Conversion,ADC),所以,我们之后所研究的语音并不是声音的最原始形态,甚至都不叫声音,一串数字而已,但这些数字却达到了它的目的:再现声音,且原始声音所要传递的信息不丢失。音乐可以做得更彻底,直接将声音记录在一纸没有动静的乐谱上。除了声音,光线也是自然存在的现象,同样地,我们也可以将它数字化,保存成图片或视频。机器学习中注重表征学习(Representation Learning),不管是声音还是光影,它们的数字化保存形式已经是一种表征方法了。对文本的处理显得直来直去一些,因为文字是人类发明出来的,发明文字的目的就是为了保存和传承,如音符一样,它也是一种离散的可记录、传播的符号,它的形态就是它的保存形式,所以文字本身就是文本处理的原始表征方法。
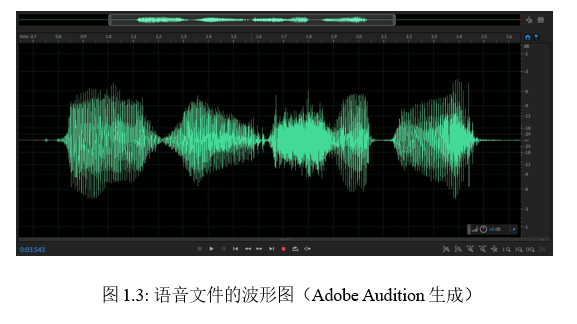
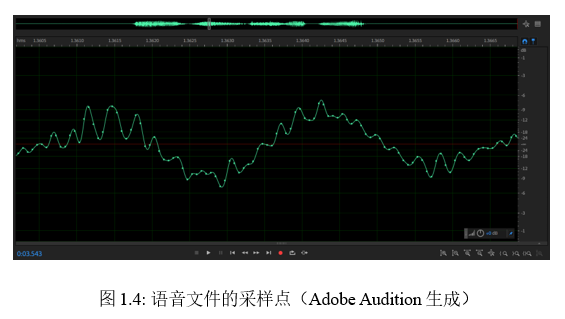
语音的基本保存形式可用波形图(Waveform)展现出来,如图1.3所示,可以简单地看作是一串上下摆动的数字序列,比如,每1秒的音频可以用16000个电压数值表示,即采样率为16kHz。进一步聚焦放大波形图,可以清晰地看到每个采样点,如图1.4所示。真正的语音不需要额外的注解,但对于数字化的语音来说,还需要额外的信息对文件格式进行说明,如信道、采样率、精度、时长等,并有文件大小=格式信息+信道数*采样率*精度*时长。可以用soxi查看文件信息,如图1.5所示。
语音,是包含时序信息的序列,是时域上的一维信号。离散傅里叶变换(Discrete Fourier Transform,DFT)使得语音的频域分析成为可能,图 1.3的语音可以变成图1.6的频谱图(Spectrogram)模样,图中可以清楚地看到“层峦叠嶂”,原始音频里的信息又以另一种表征方法释放出来了,颜色明暗表示频带能量大小,较亮的条纹即是共振峰(Formant)。整个过程就好比一双好耳朵听到了一首随时间流动的曲子,随即写出了它的谱子,看着谱,曲子又随即可以复现出来。傅里叶变换适宜具有平稳性(Stationarity)的波,而表意丰富的语音显然不具有长时平稳性,为了适用傅里叶变换,则需要假设语音的短时平稳性,所以语音的傅里叶变换是一小段一小段(一帧)进行的,而“短时”有多短也有不同影响,较短的窗口有较高的时域分辨率、较低的频域分辨率,较长的窗口有较高的频域分辨率、较低的时域分辨率,语音识别中常取25毫秒。时域与频域之间是一一对应的,可以代表彼此。从一种表征到另一种表征,包含的意义都在,只是有些藏得深,挖掘不到,有些露得浅,一目了然,后者才更利于机器学习,所以机器学习领域常常撇不开表征学习,而深度学习的优势就在于表征学习。

1.4 小结
研究一个事物之前,先去观察它、了解它,看它的来历,看它的形态、结构。语音识别的研究对象就是“语音”,本章简介了语音的物理产生原理及其大繁若简的呈现形式。
[1] 王东, 利节, and许莎. 人工智能. 清华大学出版社, 2019.
文章转载于微信公众号: 清语赋
作者: 汤志远
最后
以上就是纯真芒果最近收集整理的关于语音识别基础(一):语音是什么的全部内容,更多相关语音识别基础(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复