在人工智能飞速发展的今天,语音识别技术成为很多设备的标配,比如我们会对着手机说“siri,帮我打电话给老板”,又或是“小度小度,放首歌”等等。
尽管语音技术在逐渐发展成熟,可目前行业内仍缺乏相关的语音人才。主要原因是语音识别人才输出较为缓慢。那为什么缓慢呢?
首先,相较于其他人工智能方向而言,语音识别具有更为典型的跨学科特点,涉及到了语音语言学、信号处理、概率论、机器学习、算法设计等各方面专业知识。对于个人的学习,可谓是难上难。(你不缺人,谁缺?)
不仅如此,网上语音识别的公开资料少之又少。就算全网的语音识别资料全刷一遍,都不一定能够搭建一套语音识别系统,况且网上有些写语音识别知识的博主也是一知半解,更不用提建立完整的ASR语音识别体系。
再者,语音学习的本身就有难度,众多专业词汇和算法让初学者望而却步,例如看到下面的隐马尔可夫模型中各种模态的跳转让人不知所云。
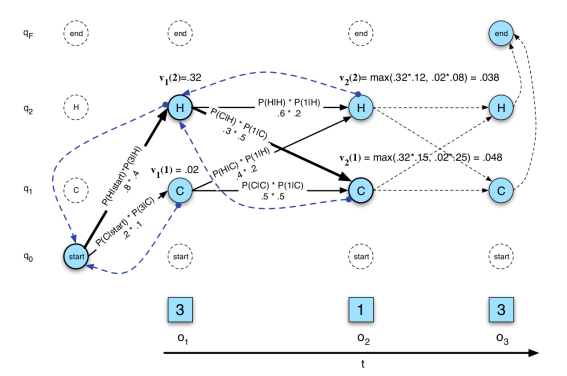
其他领域一年半载就可以入行,而在语音识别上,可能需要更长的时间,相应的人才输出也就更缓慢。
基于此,深蓝学院特邀西北工业大学教授、博导谢磊团队讲授《语音识别—从入门到精通》课程。重点讲解基于GMM-HMM算法的语音识别系统,DNN-HMM声学模型、语言模型等当前主流的语音识别算法和模型,并配有8个实践项目,确保学习效果,并有助教和老师手把手教学答疑。
讲师团队





>左右滑动查看更多<
实践项目
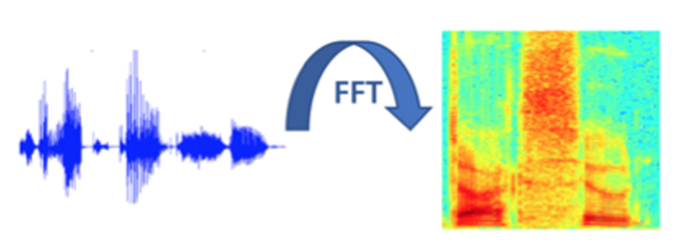
1.语音信号处理及特征提取
学习信号处理的基本知识,使用Python编程语言实现基本的信号处理操作,从0到1的提取常用语音特征。
2.GMM以及EM算法
学习通用的EM算法和GMM模型,并利用EM算法来进行GMM参数的估计,学习使用简化的数据来进行GMM模型训练的实现。

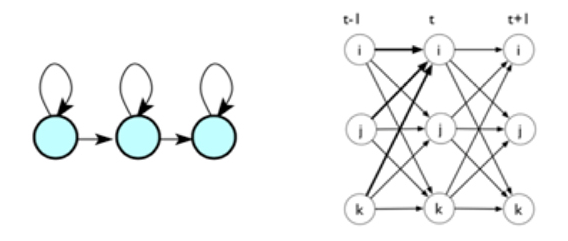
3.HMM模型
学习如何使用Python实现HMM的模型的关键算法,如前向算法、后向算法和维特比算法,通过实现掌握算法的细节,为阅读和理解更复杂的算法实现打下基础。
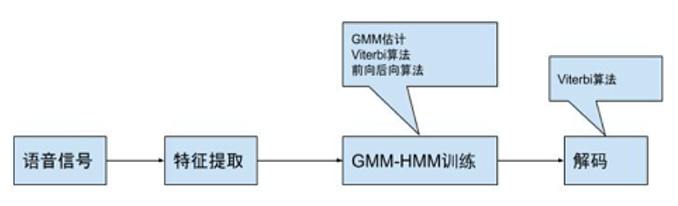
4.基于GMM-HMM的语音识别系统
在本次实践中,我们将实现一个基本的基于GMM-HMM的语音识别系统,包含训练和解码的部分,包括GMM训练、Viterbi算法、前向后向算法三个算法在语音识别中的实现。本次实验在一个孤立词系统上实现简单数字的训练和识别。
5.DNN-HMM声学模型
基于Pytorch分别实现前向神经网络FNN、卷积神经网络CNN和递归神经网络LSTM,并将其应用在声学模型建模中。
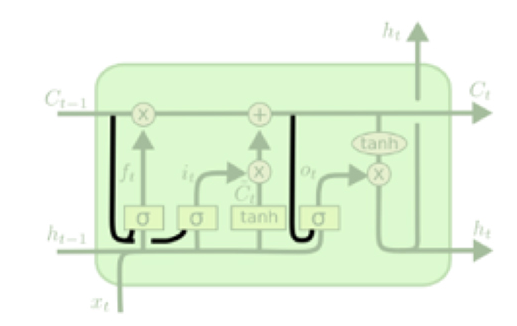
6.语言模型实战
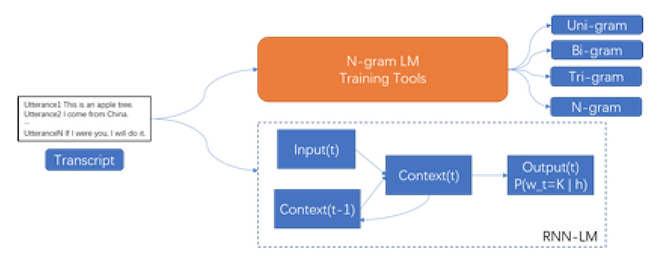
该部分实战旨在通过使用各种语言模型训练工具,进一步理解传统n-gram语言模型和RNN语言模型。学习使用irstlm、srilm和kaldi_lm等工具训练传统n-gram语言模型及相关回退算法。以 kaldi为例学习如何训练RNN-LM。
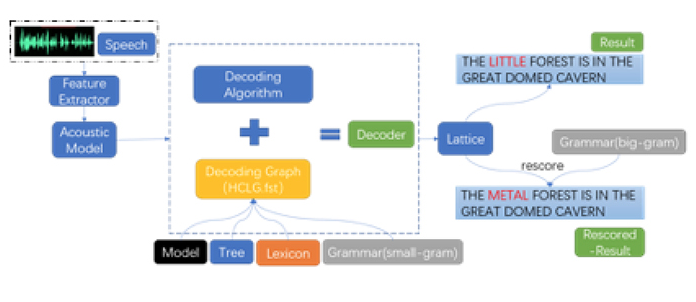
7.基于WFST的解码器实战
本次实战旨在以kaldi解码器为实例,学习FST的基本操作、Viterbi算法在解码器中具体实现(Token-Passing算法)以及rescore操作,从而更深刻的理解基于WFST的解码器。
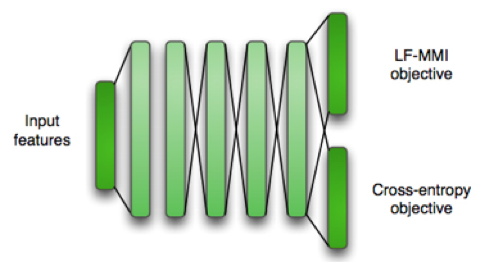
8.区分性训练
本章实战环节将复现aishell数据集在kaldi nnet3 LF-MMI模型上的结果。通过该实验,掌握基于TDNN的网络结构和LF-MMI优化准则的声学模型及其训练方法。该实验的入口脚本如链接所示:
https://github.com/kaldi-asr/kaldi/blob/master/eqs/aishell/s5/ run.sh。
课程大纲

课程亮点
1.讲师团队是国内语音方向的权威团队,学术界与产业界强强联合。
2.理论联系实践。强调极致的作业练习,助教手把手答疑解惑。
3.1v1批改作业。助教一对一的进行作业修改,直至达成优秀。
4.班主任全程带班,帮你克服学习的拖延症。
5.微信群答疑。讲师和助教会在课程微信群进行及时的答疑解惑,助你一臂之力。
了解更多
扫码添加叶子
备注【识别】,才会通过好友哦!

最后
以上就是妩媚麦片最近收集整理的关于语音识别入门:从菜鸟到大佬的全部内容,更多相关语音识别入门内容请搜索靠谱客的其他文章。








发表评论 取消回复