朋友们,之前的文章:手把手教你语音识别给大家讲过语音识别的流程,只不过,这些只是一个笼统的流程,下面开始从数据处理方面讲解怼入model之前都做了什么。
1、LogMelSpectrogramKaldi
第一步,就是读取后的数据要经过LogMel进行处理,这一部处理的目的一个是时域信号转频域信号,还有就是mel滤波器和log变换,具体这部分的至少可以参考:零基础入门语音识别: 一文详解MFCC特征(附python代码) - 知乎 (zhihu.com)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F9rAQUNz-1658977759410)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/3a2fb9dc132449ff8e709881ad6770e8~tplv-k3u1fbpfcp-watermark.image?)]](https://www.shuijiaxian.com/files_image/2023060313/10110ba8fed14c9fa3333c4b7fd91b3f.png)
如上,可以看到,接之前的文章,数据读入的时候长度为58362,然后这个地方,先对读入的audio进行了一下变换,使用paddle.to_tensor增加了一个维度,然后下面就开始进行fbank提取特征了,咱们继续往下看。
2、Fbank
_get_waveform_and_window_properties
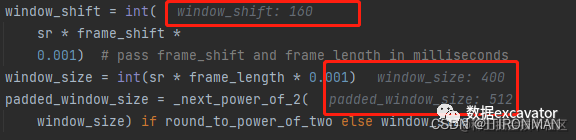
这里,是一个方法,用于得到窗口参数,可以看到,channel,也就是数据的维度,通道,这里默认给的是0,然后waveform这一行,相当于取了这个维度下面的所有值。然后可以看下图,window_shift的计算,也就是每次滑动的距离,咱们知道,之前默认是10ms,也就是时间10毫秒,但是他这个地方通过把16000Hz0.001变成了样本个数,频率时间=样本数,然后再乘以每秒的frame,实际上转化为滑动的样本数,window_size这也是一样的操作,经过这些处理后,padded_window_size 又把原来的400变成了512,这个是为何呢,其实是为了后期傅里叶变换更快,因为对于2的N次方,他更快。
def _get_waveform_and_window_properties(
waveform: Tensor,
channel: int,
sr: int,
frame_shift: float,
frame_length: float,
round_to_power_of_two: bool,
preemphasis_coefficient: float) -> Tuple[Tensor, int, int, int]:
channel = max(channel, 0)
assert channel < waveform.shape[0], (
'Invalid channel {} for size {}'.format(channel, waveform.shape[0]))
waveform = waveform[channel, :] # size (n)
window_shift = int(
sr * frame_shift *
0.001) # pass frame_shift and frame_length in milliseconds
window_size = int(sr * frame_length * 0.001)
padded_window_size = _next_power_of_2(
window_size) if round_to_power_of_two else window_size
assert 2 <= window_size <= len(waveform), (
'choose a window size {} that is [2, {}]'.format(window_size,
len(waveform)))
assert 0 < window_shift, '`window_shift` must be greater than 0'
assert padded_window_size % 2 == 0, 'the padded `window_size` must be divisible by two.'
' use `round_to_power_of_two` or change `frame_length`'
assert 0. <= preemphasis_coefficient <= 1.0, '`preemphasis_coefficient` must be between [0,1]'
assert sr > 0, '`sr` must be greater than zero'
return waveform, window_shift, window_size, padded_window_size
_get_window
接着,一个函数是得到窗口的函数,把前面的输出作为输入,这个函数之前有一个函数叫_get_strided,这个函数的处理如下图,其中最核心的是第15行代码,m = 1 + (num_samples - window_size) // window_shift,这行其实就做了一件事,就是如果我用滑动窗口去截取每一段的frame,我能截取多少个,也就是滑动窗口取值的时候,能够取多少个值。
比如,如果num_samples == window_size,也就是我的窗口和你的样本一样长,那么就意味着我压根不用移动啊,因为一旦移动就越界了,所以此时1+0=1,也就是只有一个窗口值,frame=1,当然,如果窗口小,自然就按照上面去截取,如果不减去window_size的时候,截取的窗口是不重合的,为了保证数据冗余,存在重合,保证连续性,减去他再计算就对了,最终结果为363,这个数值一定要记住,后面会反复出现363。
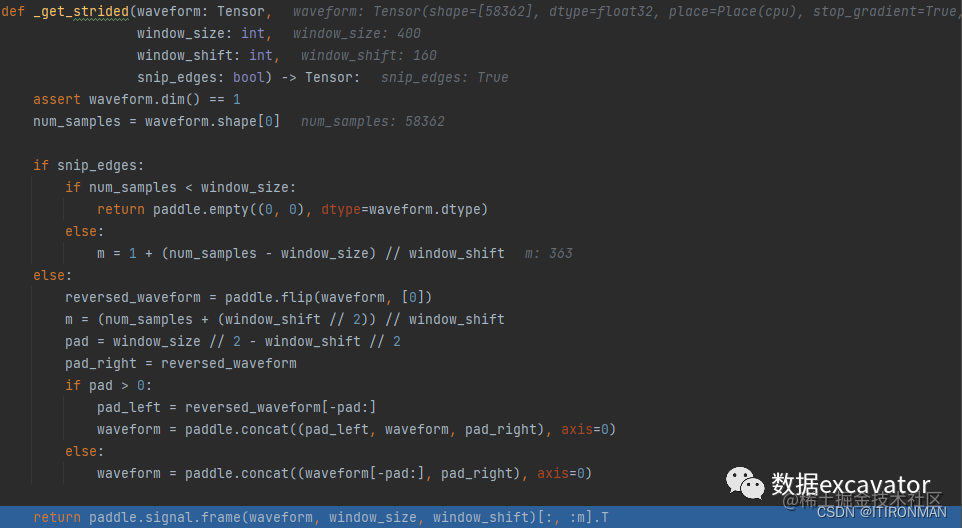
def _get_strided(waveform: Tensor,
window_size: int,
window_shift: int,
snip_edges: bool) -> Tensor:
assert waveform.dim() == 1
num_samples = waveform.shape[0]
if snip_edges:
if num_samples < window_size:
return paddle.empty((0, 0), dtype=waveform.dtype)
else:
m = 1 + (num_samples - window_size) // window_shift
else:
reversed_waveform = paddle.flip(waveform, [0])
m = (num_samples + (window_shift // 2)) // window_shift
pad = window_size // 2 - window_shift // 2
pad_right = reversed_waveform
if pad > 0:
pad_left = reversed_waveform[-pad:]
waveform = paddle.concat((pad_left, waveform, pad_right), axis=0)
else:
waveform = paddle.concat((waveform[-pad:], pad_right), axis=0)
return paddle.signal.frame(waveform, window_size, window_shift)[:, :m].T
def _get_window(waveform: Tensor,
padded_window_size: int,
window_size: int,
window_shift: int,
window_type: str,
blackman_coeff: float,
snip_edges: bool,
raw_energy: bool,
energy_floor: float,
dither: float,
remove_dc_offset: bool,
preemphasis_coefficient: float) -> Tuple[Tensor, Tensor]:
dtype = waveform.dtype
epsilon = _get_epsilon(dtype)
# (m, window_size)
strided_input = _get_strided(waveform, window_size, window_shift,
snip_edges)
if dither != 0.0:
x = paddle.maximum(epsilon,
paddle.rand(strided_input.shape, dtype=dtype))
rand_gauss = paddle.sqrt(-2 * x.log()) * paddle.cos(2 * math.pi * x)
strided_input = strided_input + rand_gauss * dither
if remove_dc_offset:
row_means = paddle.mean(strided_input, axis=1).unsqueeze(1) # (m, 1)
strided_input = strided_input - row_means
if raw_energy:
signal_log_energy = _get_log_energy(strided_input, epsilon,
energy_floor) # (m)
if preemphasis_coefficient != 0.0:
offset_strided_input = paddle.nn.functional.pad(
strided_input.unsqueeze(0), (1, 0),
data_format='NCL',
mode='replicate').squeeze(0) # (m, window_size + 1)
strided_input = strided_input - preemphasis_coefficient * offset_strided_input[:, :
-1]
window_function = _feature_window_function(
window_type, window_size, blackman_coeff,
dtype).unsqueeze(0) # (1, window_size)
strided_input = strided_input * window_function # (m, window_size)
# (m, padded_window_size)
if padded_window_size != window_size:
padding_right = padded_window_size - window_size
strided_input = paddle.nn.functional.pad(
strided_input.unsqueeze(0), (0, padding_right),
data_format='NCL',
mode='constant',
value=0).squeeze(0)
if not raw_energy:
signal_log_energy = _get_log_energy(strided_input, epsilon,
energy_floor) # size (m)
return strided_input, signal_log_energy
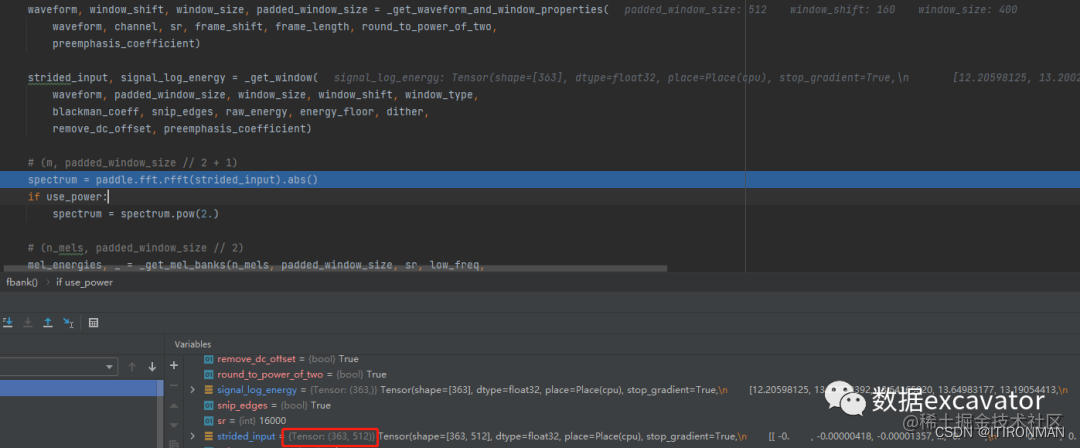
如上,经过上面的一系列处理,strided_input变成了(363,512),363前面讲过了,是363个截取的窗口,512是每一个窗口的维度,也就是向量表达,前面本应该是400,变成512也讲了,目的是傅里叶变换计算更快。
rfft,开始傅里叶变换

这个实现,就不具体讲了,因为底层是C++实现的,咱们直接看结果。

结果是363,257,为啥维度正好减半,这个是rfft的操作导致的,具体可以搜索相关文章,总之现在已经完成变换,并且进行了平方,转为频谱了。
_get_mel_banks
这部分,就不详细讲了,其实就是对上面的数据再次处理,用滤波器处理,至于啥是滤波器,我给你举个例子,三棱镜知道不,咱们的太阳光是看不见,摸不着的白光知道不,光是七色混合的知道不,我现在想把白光里面的红光取出来做点别的事情,我咋办?对了,用三棱镜,这个三棱镜就是滤波器,把里面某个分量取出来,然后我可以用它作为特征,就这么个意思。
最后
以上就是大气薯片最近收集整理的关于手把手教你语音识别(二)的全部内容,更多相关手把手教你语音识别(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复