目录
- Part1 视频学习
- 一、绪论
- 二、基本组成结构
- 1. 卷积
- 2. 池化
- 3. 全连接
- 一、绪论卷积神经网路典型结构
- 1. AlexNet
- 2. ZFNet
- 3. VGG
- 4. GoogleNet
- 5. ResNet
- Part2 问题回答
Part1 视频学习
一、绪论
- 卷积神经网络的应用包括:分类、检索、检测、分割、人脸识别、人脸表情识别、图像生成、图像风格转化、自动驾驶等;
- 深度学习的三步骤为:(1)搭建神经网络结构;(2)运用合适的损失函数,如交叉熵损失函数(cross entropy loss)、均方误差函数(MSE)等;(3)运用合适的优化函数,以此更新参数,如反向传播(BP)、随机梯度下降(SGD)等;
- 损失函数用于衡量训练模型时的预测结果与实际结果的吻合度,可以通过计算出的损失来调整模型的参数或者权重,以不断优化模型。损失函数分为分类损失和回归函数两类,常用的损失函数有:
- 关交叉熵损失 L o s s = − ∑ i y i l n y i p Loss = -sum_i y_i lny_i^p Loss=−∑iyilnyip
- hinge loss: L ( y , f ( x ) ) = m a x ( 0 , 1 − y f ( x ) ) L(y,f(x))=max(0,1-yf(x)) L(y,f(x))=max(0,1−yf(x))
- 均方误差 M S E = ∑ i = 1 n ( y i − y i P ) 2 MSE=sum_{i=1}^n(y_i-y_i^P)^2 MSE=∑i=1n(yi−yiP)2
- 平均绝对值误差(L1损失) M A E = ∑ i = 1 n ∣ y i − y i P ∣ MAE=sum_{i=1}^n|y_i - y_i^P| MAE=∑i=1n∣yi−yiP∣;
- 全连接网络和卷积神经网络都具有卷积层、激活层、池化层、全连接层,但全连接网络在处理图像时参数太多,会出现过拟合问题,卷积神经网络通过局部关联、参数共享解决;
二、基本组成结构
1. 卷积
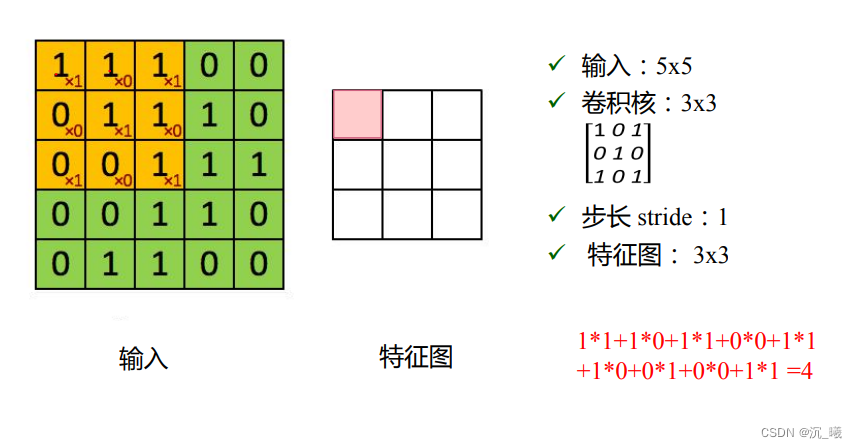
卷积是对两个实变函数的一种数学操作,在图像处理中,图像以二维矩阵的形式输入到神经网络中,此时通过二维卷积提取特征。
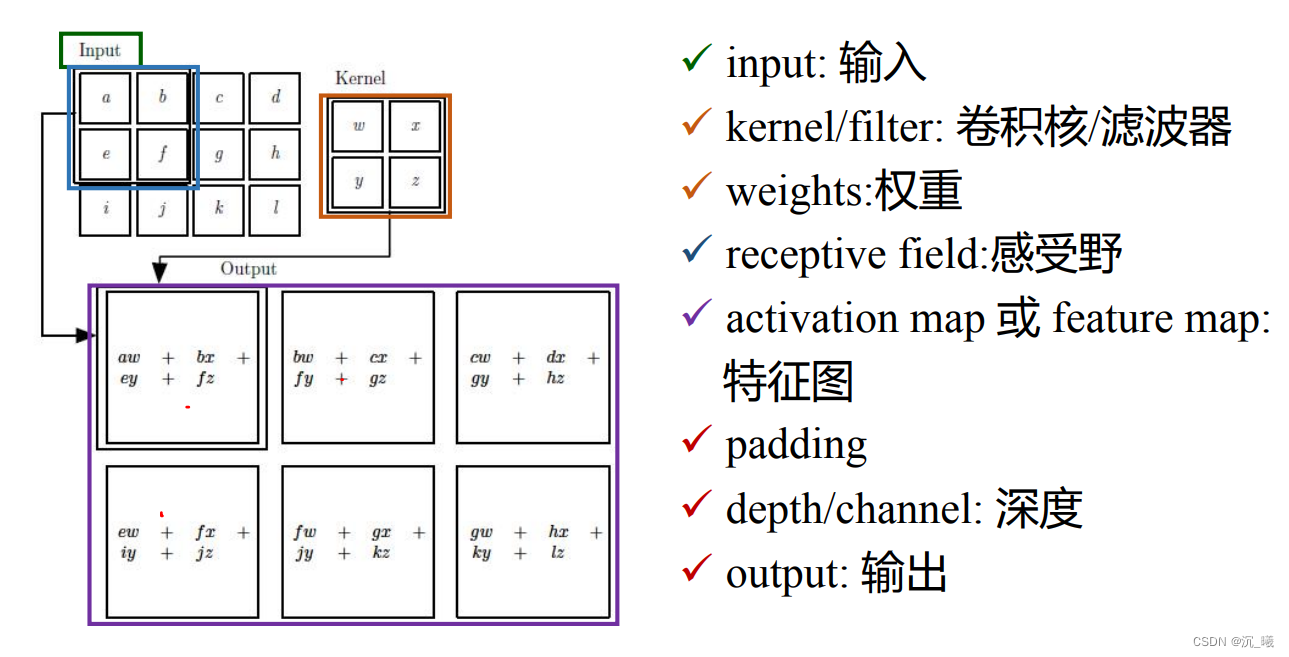
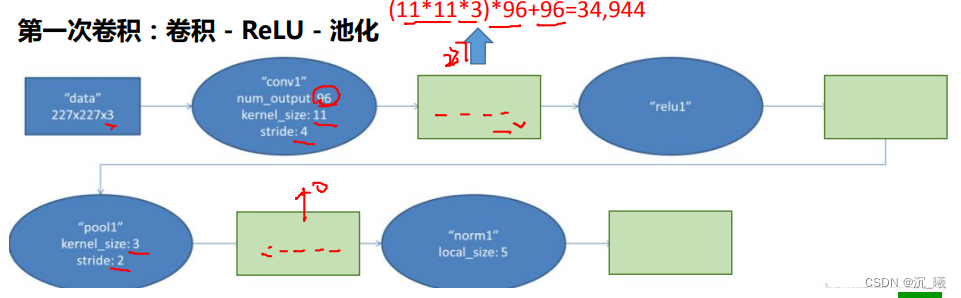
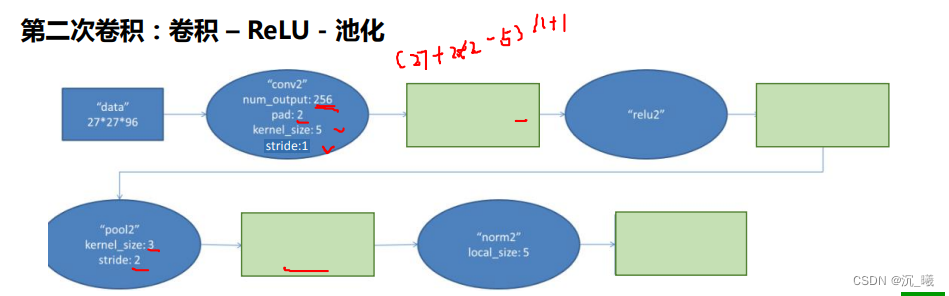
设定某一大小的卷积核(kernel)(卷积核也叫滤波器),如上图中的卷积核为二维矩阵,大小为2×2,卷积核里的数值称为权重(weights),如上图中的权重为w、x、y、z,将该卷积核与输入矩阵中对应大小同样为2×2的部分(即感受野(receptive field)为2×2)按位置进行乘积,再进行加和,即得到一位数值,将感受野逐步右移和下移,即可得到所有数值,所有数值构成一个新的二维矩阵,即为特征图,每次移动的距离称为步长(stride)。若卷积核数量为n个,即可得到n个特征图(feature map),n被称为深度(channel)。若输入矩阵在卷积核移动后剩余的大小不匹配,则用0进行填充(paddinng)。
输出的特征图大小为:
(
N
+
p
a
d
d
i
n
g
∗
2
−
F
)
/
s
t
r
i
d
e
+
1
(N+padding*2-F)/stride+1
(N+padding∗2−F)/stride+1。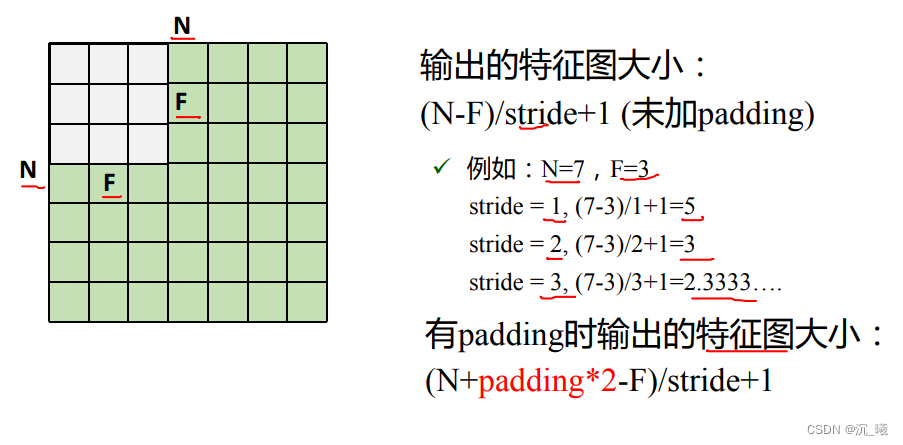
2. 池化
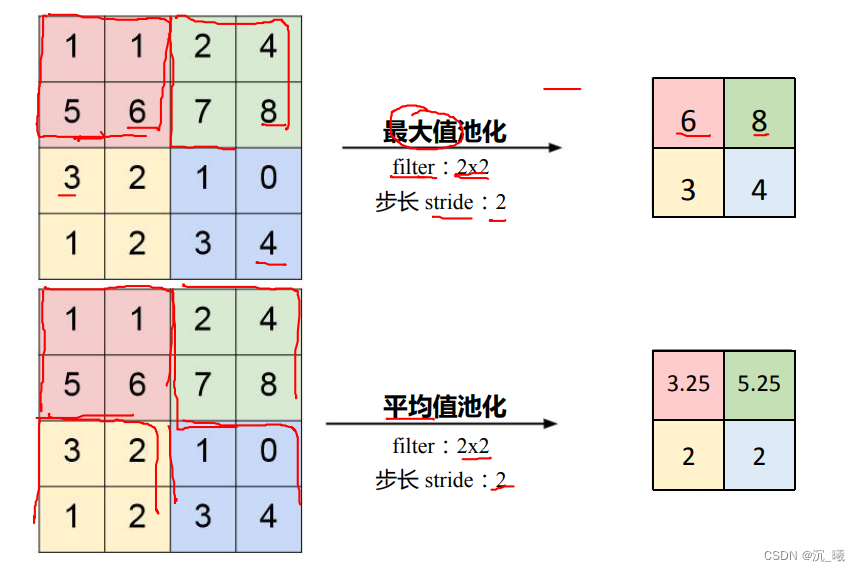
池化(Polling)一般处于卷积层与卷积层之间、全连接层与全连接层之间,可以达到保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力,常用的池化为:
- Max pooling 最大值池化
- Average pooling 平均池化
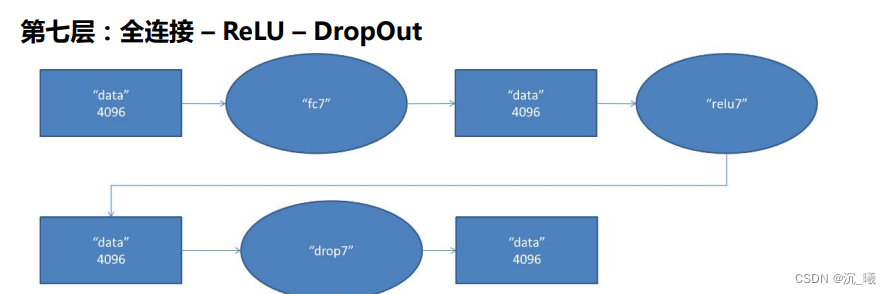
3. 全连接
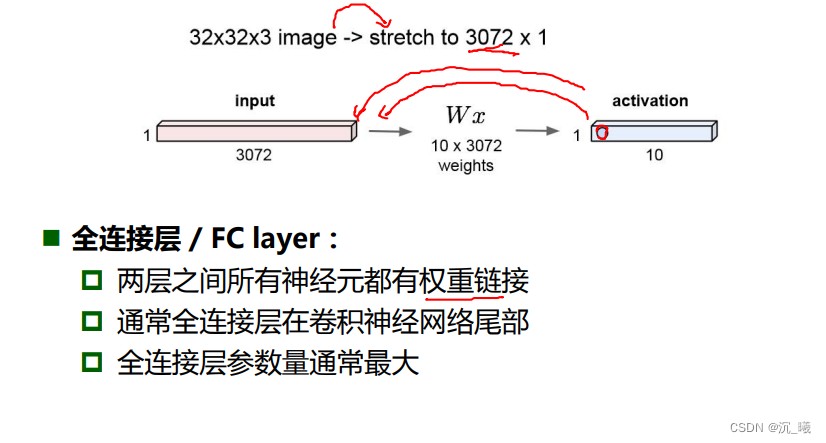
全连接层(FC layer)一般位于卷积神经网络的尾部,两层之间所有的神经元都有权重连接,其参数通常最大。
一、绪论卷积神经网路典型结构
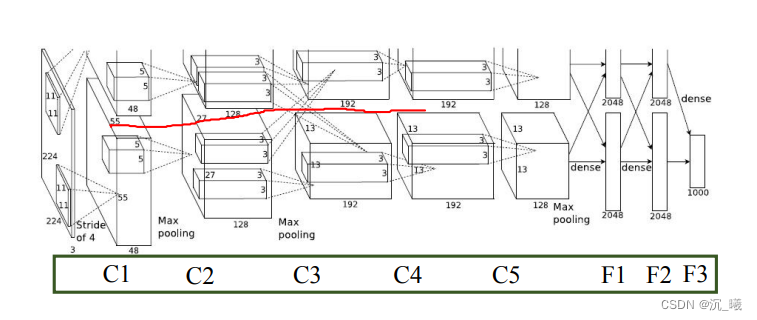
1. AlexNet
AlexNet具有重要历史意义,打破了当时深度学习沉寂已久的局面,原因在于:
- 大数据训练:百万级ImageNet图像数据
- 非线性激活函数:ReLU
- 防止过拟合:Dropout,Data augmentation
- 其他:双GPU实现
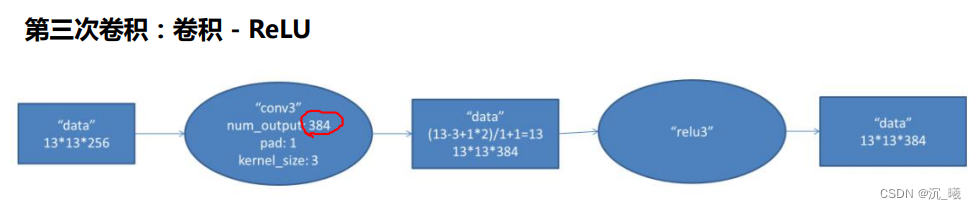
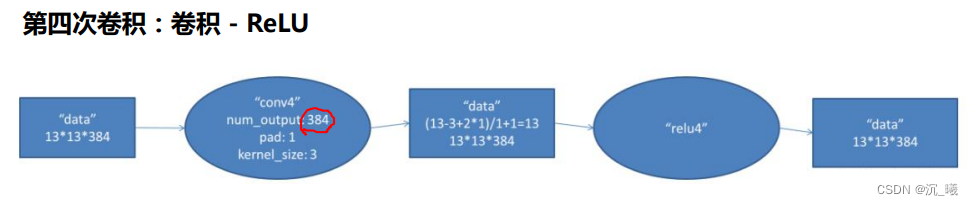
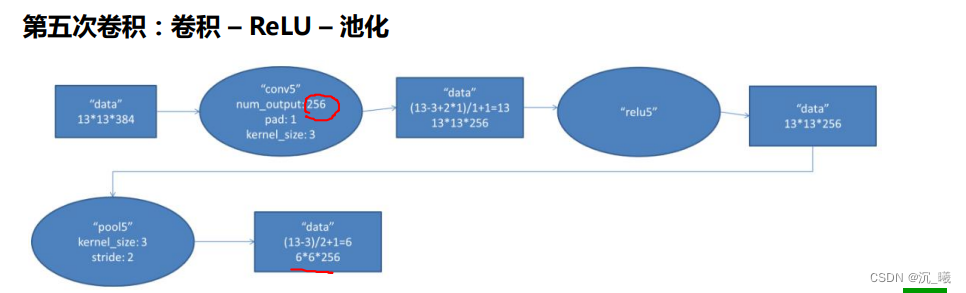
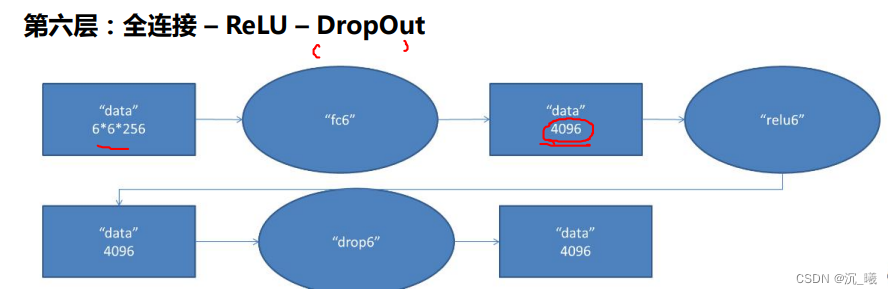
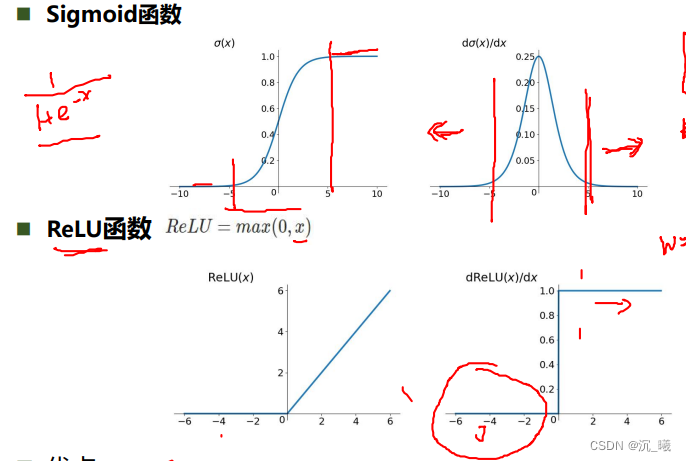
ReLu函数解决了梯度消失的问题(在正区间内);其计算速度很快,只需要判断输入是否大于0即可;收敛速度远快于sigmoid;
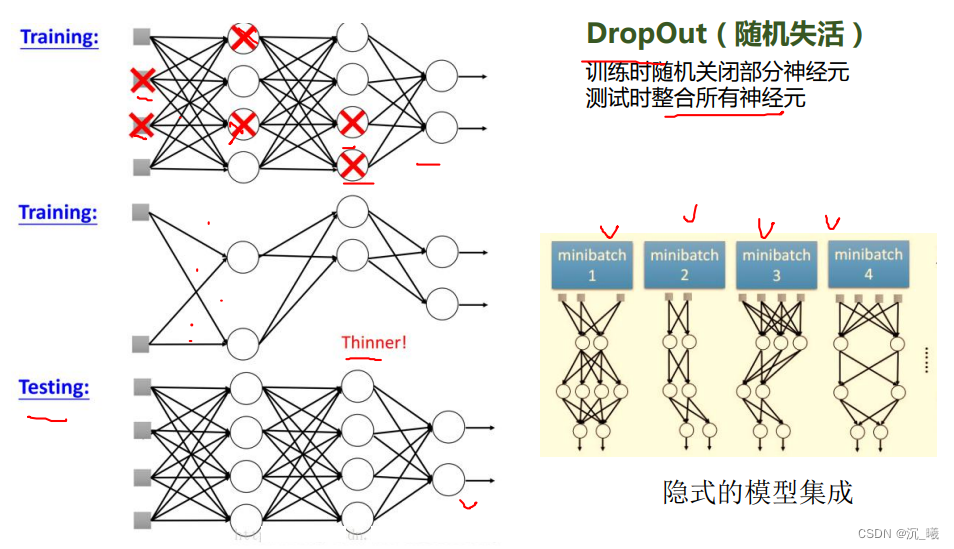
DropOut(随机失活)可使得在训练时随机关闭部分神经元,在测试时整合所有神经元。
并可通过平移、翻转、对称、改变RGB通道强度进行数据增强。

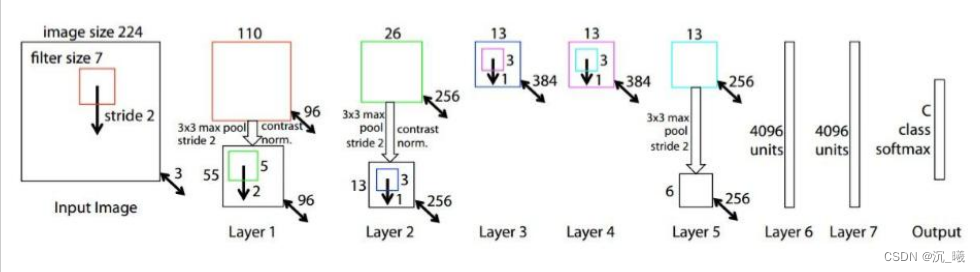
2. ZFNet
ZFNet的网络结构与AlexNet相同,其把卷积层1中的感受野大小由11×11改为7×7,步长由4改为2,卷积层3、4、5中的滤波器个数由384、384、256改为512、512、1024。
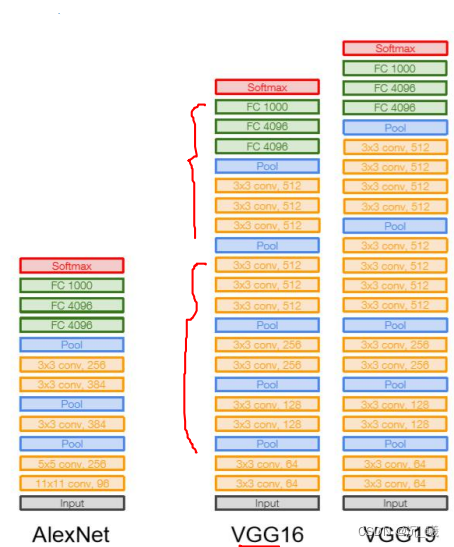
3. VGG
VGG在AlexNet的基础上加深深度,使得错误率从11.7%下降到7.3%。
4. GoogleNet
GoogleNet包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共约100个,其参数量大概为AlexNet的1/12,没有全连接层。
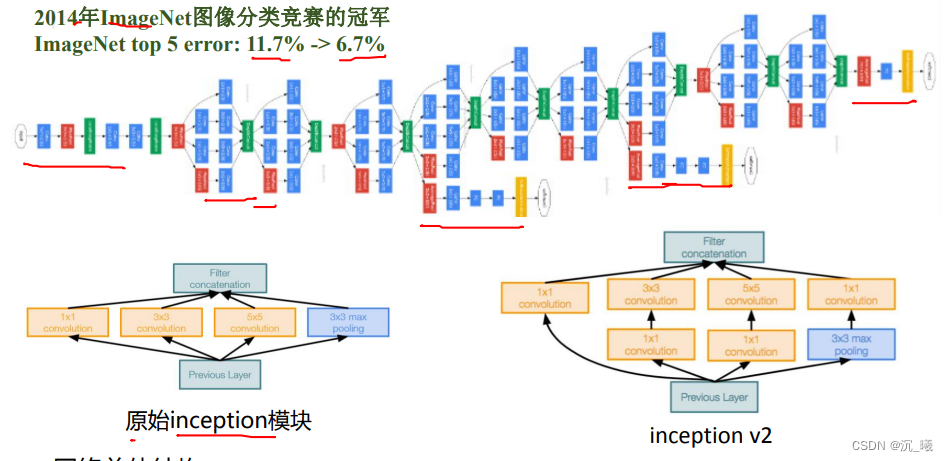
- Stem部分(stem network)为卷积-池化-卷积-卷积-池化;
- 多个Inception结构堆叠;
- ,除了最后的类别输出层,没有额外的全连接层;
- 通过辅助分类器解决模型深度多深导致的梯度消失问题;
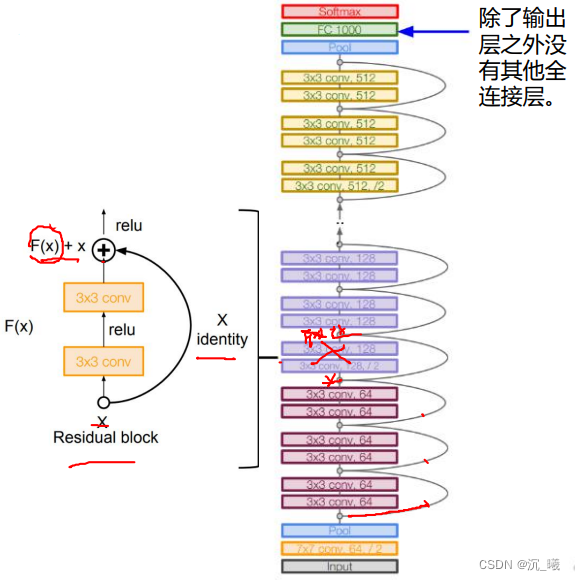
5. ResNet
残差学习网络(deep residual learning network)去掉相同的主体部分,从而突出微小的变化,其深度为152层,可以用于训练非常深的网络。
Part2 问题回答
Q:dataloader里面shuffle取不同值有什么区别?
A:
若shuffle设置为True,将打乱数据,通常在训练时使用;设置为False,不打乱数据,通常在测试时使用。
Q:transform里,取了不同值,这个有什么区别?
A:
对数据进行不同的预处理。如用ToTensor将PIL图像中每个灰度值归一化到[0,1],用RandomCrop则可以进行裁剪。
Q:epoch和batch的区别?
A:
epoch是训练轮数,batch是指一次训练中输入的一批数据。
Q:1x1的卷积和FC有什么区别?主要起什么作用?
A:
1x1的卷积是针对矩阵的卷积操作,而FC是针对神经元的操作。1x1卷积不改变宽度和高度,只改变channel数,主要作用是升维、降维以及提升网络的非线性;FC的作用主要是将局部特征进行整合,并得到分类标签。
Q:residual learning 为什么能够提升准确率?
A:
因为避免了网络深度过深时的退化问题。
Q:代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
A:
代码练习二中的网络相对于LeNet,在两个卷积层和最后一个全连接层后分别加入了ReLU激活函数,但没有最后的softmax。
Q:代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
A:
可以对变小的特征图进行1x1卷积来进行升维。
Q:有什么方法可以进一步提升准确率?
A:
可以通过进一步增加网络的层数或改进网络的结构来提升准确率。
最后
以上就是无辜音响最近收集整理的关于第二周学习心得 卷积神经网络基础Part1 视频学习Part2 问题回答的全部内容,更多相关第二周学习心得内容请搜索靠谱客的其他文章。








发表评论 取消回复