1. 什么是支持向量机?
在机器学习中,分类问题是一种非常常见也非常重要的问题。常见的分类方法有决策树、聚类方法、贝叶斯分类等等。举一个常见的分类的例子。如下图1所示,在平面直角坐标系中,有一些点,已知这些点可以分为两类,现在让你将它们分类。 (图1)
(图1)
显然我们可以发现所有的点一类位于左下角,一类位于右上角。所以我们可以很自然将它们分为两类,如图2所示:红色的点代表一类,蓝色的点代表一类。 (图2)
(图2)
现在如果让你用一条直线将这两类点分开,这应该是一件非常容易的事情,比如如图3所示的三条直线都可以办到这点。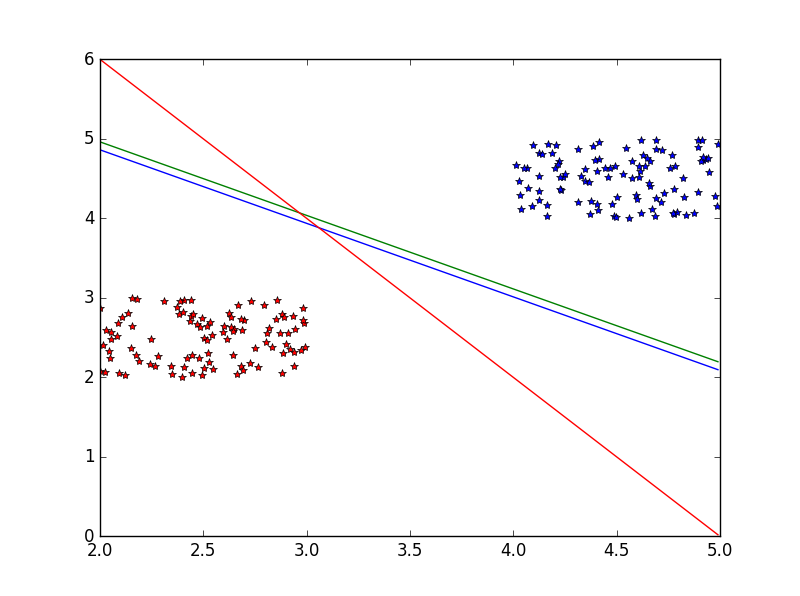 (图3)
(图3)
事实上,可以很容易发现,我们可以作无数条直线将这两类点分开。这里,我们不禁要问,是不是所有的直线分类的效果都一样好呢?如果不是,那么哪一条直线分类效果最好呢?评判的标准又是什么?比如对于如图4所示的两条直线,(line1)和(line2),这两条直线哪条分类效果更好呢?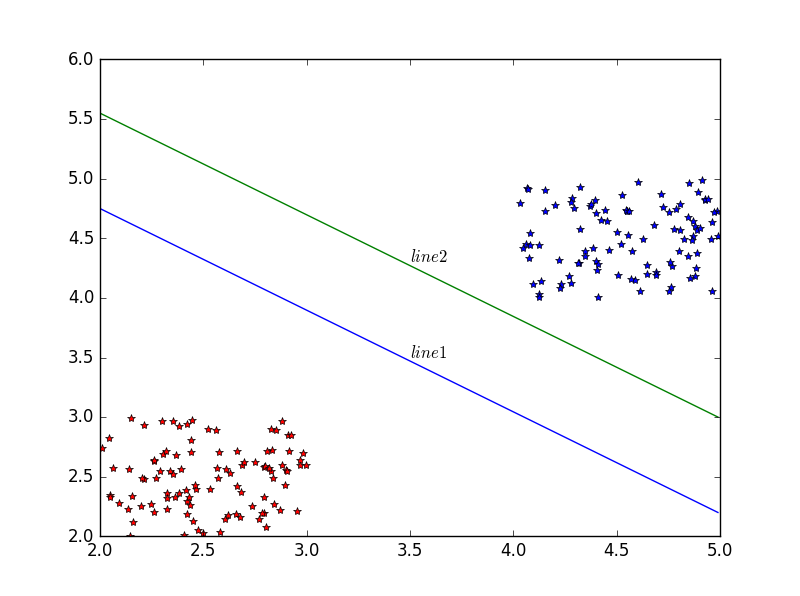 (图4)
(图4)
直观上可以发现,(line1)的分类效果要比(line2)更好的,这是因为(line1)几乎位于这两类点的中间,不偏向于任何一类点;而(line2)则偏向右上部分的点更多一些。如果这时又增加了一些点让你将它们归为这两类,显然(line1)要更“公正”一些,而(line2)则有可能将本来属于右上类的点错误地归为左下类。说到这里,你可能会问,如何才能确定那个最佳分类的直线呢?其实这正是支持向量机((SVM,Support Vector Machine))要解决的问题。
更一般地情况下,如图5所示,有时两类点(图5中红色的点和蓝色的点)是交错分布的,“你中有我,我中有你”,根本不可能用一条直线分开,这个时候该怎么办呢?这也是支持向量机要解决的问题,而且是支持向量机的优势所在。这类问题叫做非线性分类问题。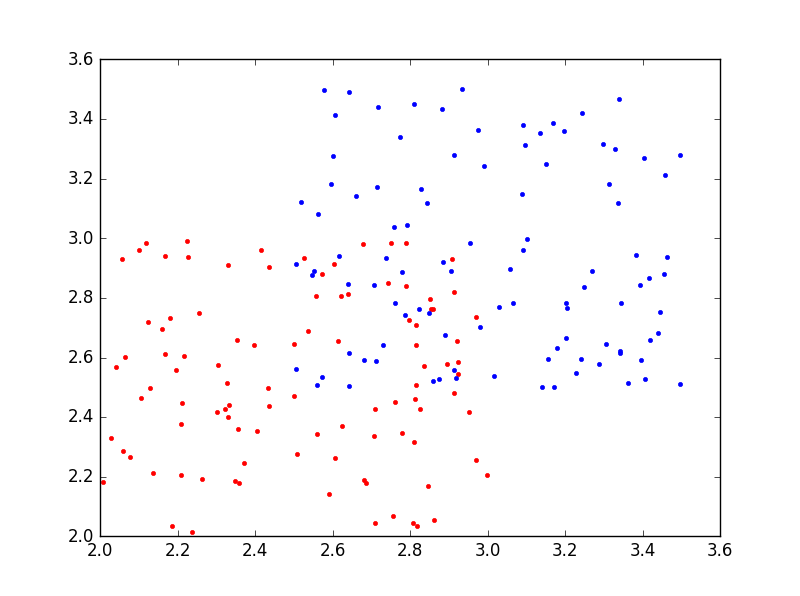 (图5)
(图5)
说到这里,你可能大概有些明白支持向量机是用来干什么的了。支持向量机的基本模型是定义在特征空间上的间隔最大的线性分类器。它是一种二分类模型。当采用了核技巧之后,支持向量机即可以用于非线性分类。不同类型的支持向量机解决不同的问题。
1.线性可分支持向量机:当训练数据线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机。
2. 线性支持向量机:当训练数据近似可分时,通过软间隔最大化,学习一个线性支持向量机。
3. 非线性支持向量机:当训练数据线性不可分时,通过使用核技巧以及软间隔最大化,学习一个非线性支持向量机。
以上只是对于支持向量机的最粗浅的说明,其实支持向量机内在的数学原理还是非常复杂的,其内容也十分丰富。我在学习的过程中参考了不少教材,比如《数据挖掘导论》、《神经网络与机器学习》、《Python大战机器学习》等。里面对于支持向量机有非常详细的说明,而且还从数学的角度推导了一遍。个人觉得好好研究一下原理以及数学推导对于深刻理解支持向量机还是非常有帮助的。鉴于我这里只是介绍,而非严格地教程,所以公式就不罗列了,感兴趣的请自行阅读相关文献与书籍。
2. 如何理解支持向量机?
如果不从数学公式的角度出发,在不涉及公式细节的情况下,如何直观理解支持向量机呢?虽然这并非易事(因为支持向量机的复杂性),但是还是可以办到的。我在查阅资料的过程中,看到了知乎上的一个问题,里面有几个答案我觉得非常棒,可以让你在不理解数学公式的情况下,对于支持向量机有一个直观的了解。地址如下:支持向量机(SVM)是什么意思?。这里我仍然以两类点的分类问题为例来谈谈我自己的理解。以图1中的两类点为例,前面我们已经说过了,存在无穷多条直线可以将这两类点分开。现在我们的目标是在一定的准则下,找出划分最好的那一条。从直观的理解来看,这条最佳直线应该满足“公正性”:即不偏向任何一类点,或者说处于中间位置。现在假设我们已经找到了一条分割直线(l),每一个样本点都到这条直线存在一个距离。设直线(l)的方程为:(wx + b = 0),共有(n)个点,(n)个点的坐标为((x_1,y_1),(x_2,y_2),cdots,(x_n,y_n)),(n)个点到直线(l)的距离分别为(d_1,d_2,cdots,d_n),现在我们需要找(d_1,d_2,cdots,d_n)中的最小值:(d_{min} = min{d_1,d_2,cdots,d_n}),显然我们希望(d_{min})越大越好,(d_{min})越大,说明它距离两类的距离都较远。于是问题转化为在所有可行的直线划分中,找到 使得(d_{min})最大的那条即是最佳划分直线。对于线性可分的情况而言,我们可以证明,这样的最佳直线总是存在的。我们称找到的最佳划分两类的直线为:最大几何间隔分离超平面(对于二维点而言是直线,三维空间中则是平面,更高维则是超平面了,这里统称为超平面)。
什么是支持向量?
支持向量机((SVM))之所以称之为支持向量机,是因为有一个叫作支持向量((Support Vector))的东西。那么什么叫作支持向量呢?假设我们现在已经找到了最大几何间隔分离超平面,容易理解,我们可以找到许多条与这条直线平行的直线,在所有平行的直线中,存在两条直线,它们恰好可以划分两类点,所谓恰好是指,如果再平移哪怕一点点,就会不能正确划分两类点,这两条临界直线(超平面)被称之为间隔边界。对于线性可分的情况而言,我们可以证明,在样本点中总会有一些样本点落在间隔边界上(但是对于线性不可分的情况,则未必如此),落在间隔边界上的这些样本点就被我们称为支持向量。之所以被称之为支持向量呢,是因为我们确定的最大几何间隔分离超平面只与这些支持向量有关,与其他的样本点无关,也就是说哪怕你去掉再多非支持向量的点,最大几何间隔分离超平面也一样不变。这也就是支持向量机名字的来源。
支持向量机如何处理线性不可分的情况?
这个问题其实涉及到(SVM)的核心了。在之前我们多次提到了一个词:核技巧。那么什么是核技巧呢?首先,我们需要明确输入空间与特征空间这两个概念。所谓输入空间就是我们定义样本点的空间,由于问题线性不可分,所以我们无法用一个超平面将两类点分开,但是我们总可以找到一个合适的超曲面将两类点正确划分。问题的关键就是找到这个超曲面。直接寻找显然是很困难的,所以我们聪明的数学家就定义了一个映射,简单来说就是从低维到高维的映射,研究发现,如果映射定义地恰当,则原来在低维线性不可分的问题,到了高维居然就线性可分了!这真的是一个让人惊喜的发现。所以我们只要在高维按照之前线性可分的情况去找最大几何间隔分离超平面,找到之后,再还原到低维就可以了。理论上已经证明,在低维线性不可分的情况下,我们总可以找到合适的从低维到高维的映射,使得在高维线性可分。于是问题的关键就是找这个从低维到高维的映射了,这个其实就是核函数(核技巧)要干的事情了。具体的定义较为复杂,这里不展开了。在给定核函数的情况下,我们可以利用求解线性分类问题的方法来求解非线性分类问题的支持向量机,学习是隐式地在特征空间(也就是映射之后的高维空间)进行的,这被称之为核技巧。在实际应用中,往往直接依赖经验选择核函数,然后再验证其是有效的即可。常用的核函数有:多项式核函数、高斯核函数、sigmoid核函数等。
3. 支持向量机的实际应用举例(附matlab代码与Python代码)
1. 将两类点分类(二维平面)
作为第一个例子,我们首先解决开头提到的那个平面上两类点的分类问题。我们找出最大几何间隔分离超平面与支持向量,然后验证该最佳超平面能否对新加入的点进行准确分类。这里我们分别使用Matlab与Pyhton来实现这个例子。Matlab中的(svmtrain)、(svmclassify)函数以及Python sklearn(一个机器学习的库)均对SVM有很好的支持。如果想要详细了解二者的用法,对于Matlab可以直接查看其帮助手册,对于Pyhton则可以参考相关机器学习的书籍或者直接去看sklearn的网站学习。
Matlab 对两类点分类的代码:
% 使用SVM(支持向量机)分割两类点并画出图形
XY1 = 2 + rand(100,2); % 随机产生100行2列在2-3之间的点
XY2 = 3+ rand(100,2);% 随机产生100行2列在3-4之间的点
XY = [XY1;XY2]; % 合并两点
Classify =[zeros(100,1);ones(100,1)]; % 第一类点用0表示,第二类点用1表示
Sample = 2+ 2*rand(100,2); % 测试点
%figure(1);
%plot(XY1(:,1),XY1(:,2),'r*'); % 第一类点用红色表示
%hold on;
%plot(XY2(:,1),XY2(:,2),'b*'); % 第二类点用蓝色表示
% 训练SVM
SVM = svmtrain(XY,Classify,'showplot',true);
% 给测试点分类,并作出最大间隔超平面(一条直线)
svmclassify(SVM,Sample,'showplot',true); 得到结果如图6所示: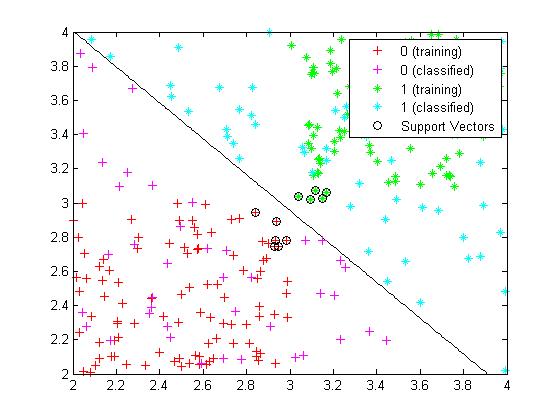 (图6)
(图6)
图6中的直线即是所求的最大几何间隔分离超平面,画黑圈的点为支持向量,而且可以看出其对新增加的点划分得很好,这说明了SVM最大几何间隔分离超平面分类的有效性。
再来看Python的代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/7/22 10:45
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : svm_split_points.py
'''
@Description:使用svm对两类点进行分类(线性可分)
'''
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVC # 导入SVM 线性分类器
XY1 = 2 + np.random.rand(100,2) # 100行2列在2到3之间的数据点
XY2 = 4 + np.random.rand(100,2) # 100行2列在4到5之间的数据点
XY = np.concatenate((XY1,XY2),axis=0)
test_data = 2 + 3*np.random.rand(100,2) # 测试数据,2-5之间
label = np.append(np.zeros(100),np.ones(100)) # XY1 用0标志,XY2用1标志
svm = LinearSVC()
svm.fit(XY,label)
predict_test =svm.predict(test_data) # 对测试数据进行预测
coef = svm.coef_ # 系数(w向量)
intercept = svm.intercept_ # 截距(b)
# print("coef:",coef)
# print("intercept:",intercept)
# print("predict_test:",predict_test)
sort1_index = predict_test == 0. # 测试数据属于第一类的序号(bool 数组)
sort2_index = predict_test == 1. # 测试数据属于第二类的序号(bool 数组)
test_sort1 = test_data[sort1_index,:] # 测试数据属于第一类的点
test_sort2 = test_data[sort2_index,:] # 测试数据属于第二类的点
# 最大间隔超平面的方程为:Wx + b = 0
# 画图
plt.plot(XY1[:,0],XY1[:,1],'r*',label='train data 1')
plt.plot(XY2[:,0],XY2[:,1],'b*',label='train data 2')
line_x = np.arange(2,5,0.01) # 直线x坐标
line_y = (coef[0,0]*line_x + intercept[0])/(-coef[0,1]) # 直线y坐标
# 画出直线
plt.plot(line_x,line_y,'-')
# 画出预测点
plt.plot(test_sort1[:,0],test_sort1[:,1],'r+',label='test data 1')
plt.plot(test_sort2[:,0],test_sort2[:,1],'b+',label='test data 2')
plt.legend(loc = 'best')
plt.show()结果如下图7所示: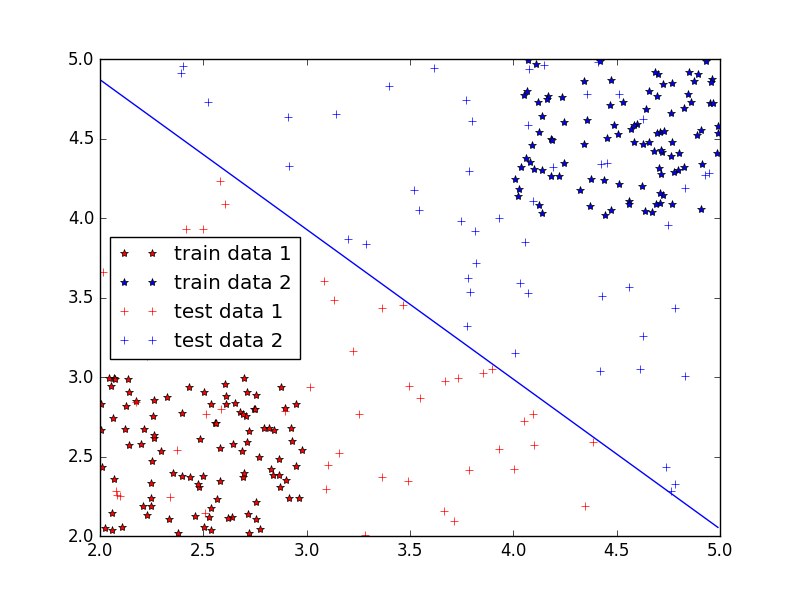 (图7)
(图7)
其中那条直线即是作出的最大几何间隔分离超平面,train data 1 和 train data 2为第一、二类训练数据,test data 1和 test data 2 为第一、二类测试数据。可以看出 SVM 分类的效果很好。
2. 将图像中的某个物体从背景中分割出来(这里以分割在湖中游泳的鸭子为例)
如图8所示,湖面上有一只鸭子,现在我们希望将鸭子从湖水(背景)中分割出来,该怎么做呢?
如果你手中有类似PS这样的软件,完成这个任务应该并不困难,不就是抠图么!!!但是,抠图需要我们自己手动找分割线啊,多麻烦呢,能不能让计算机自动完成这个工作呢?当然是可以的,利用上面说的SVM就可以办到。那么该怎么做呢?我们知道,彩色图片本质上是由一个一个的像素点组成的,每一个像素点由RGB三色组成,或者说本质上彩色图像就是三维数组,而灰度图像则是二维数组。如果我们将湖水和鸭子看做两类物体,那么现在的任务则是从整个图像中将这两类分割出来。显然鸭子与湖水的界限并不是一条单纯的直线,甚至有些地方是交杂在一起的,所以本质上这是一个非线性可分的问题。从图中可以看出,鸭子的颜色偏黑色和灰色,掺杂有少量白色以及黄色(鸭脚),而湖水则是浅绿色的。所以我们可以以颜色为标准对二者进行分类,即以RGB为分类标准。为了使用SVM,首先我们需要选取训练样本,这里就是找出典型的属于鸭子的像素点RGB值(为一个长度为3的向量),和属于湖水的RGB值。关于如何确定图像上某一点的RGB值,有很多办法,这里我推荐使用一个名为Colorpix的小软件,这个软件只有几百kb,一个exe执行文件,可以找出屏幕上任何一点的像素属性,用起来很方便,如果要用,请大家自行搜索。这里我对于湖水和鸭子分别选取了10个像素点,这样我就得到了一个20行3列的样本数据(每一行是一个样本,共有20个样本)。将湖水的像素点标记为0,鸭子的像素点标记为1,这样我们就可以得到长度为20的、前10个元素为0,后10个元素为1的向量。由于图像原始数据为三维矩阵,比如设其维度为((m,n,k)),我们首先需要将其转化为2维,即转化为((mn,k))的矩阵,然后使用线性不可分的SVM训练样本数据,接着使用训练好的SVM对((mn,k))矩阵进行归类,我们得到一个长为(mn)的数据取0或者1的一维数组(predict),为0的部分就是代表对应的像素点判定为湖水了。接着将(predict)数组在行的方向上扩展为3列,即变为((predict,predict,predict)),扩展之后的矩阵维度为((mn,k)),再将其变回三维矩阵,即((m,n,k))的矩阵。该矩阵与原始图像三维矩阵对应,该矩阵数据点为((0,0,0))的部分即判定为湖水,我们将图像上该像素点的RGB值变为((255,255,255))(白色),于是我们就可以得到去掉湖水(变为白色背景)的鸭子了。
以上就是使用SVM将鸭子从湖水中分割出来的步骤了。下面给出代码:
1. Matlab 代码
% 使用SVM将鸭子从湖面分割
% 导入图像文件引导对话框
[filename,pathname,flag] = uigetfile('*.jpg','请导入图像文件');
Duck = imread([pathname,filename]);
%使用ColorPix软件从图上选取几个湖面的代表性点的RGB的值
LakeTrainData = [147,168,125;151 173 124;143 159 112;150 168 126;...
146 165 120;145 161 116;150 171 130;146 112 137;149 169 120;144 160 111];
% 从图中选取几个有代表性的鸭子点的RGB值
DuckTrainData = [81 76 82;212 202 193;177 159 157;129 112 105;167 147 136;...
237 207 145;226 207 192;95 81 68;198 216 218;197 180 128];
% 属于湖的点为0,鸭子的点为1
group = [zeros(size(LakeTrainData,1),1);ones(size(DuckTrainData,1),1)];
% 训练得到支持向量分类机
LakeDuckSVM = svmtrain([LakeTrainData;DuckTrainData],group,'kernel_function','polynomial',...
'polyorder',2);
[m,n,k] = size(Duck); % 图像三维矩阵
% 将Duck转化为双精度的m*n行,3列的矩阵
Duck1 = double(reshape(Duck,m*n,k));
% 根据训练得到的支持向量机对整个图像像素点进行分类
IndDuck = svmclassify(LakeDuckSVM,Duck1);
% 属于湖的点的逻辑数组
IndLake = ~IndDuck;
result = reshape([IndLake,IndLake,IndLake],[m,n,k]); % 与图片的维数对应
Duck2 = Duck;
Duck2(result)= 255; % 湖面的点变为白色
figure;
imshow(Duck2); % 显示分割之后的图像结果如图8所示: (图8)
(图8)
可以基本看到鸭子的轮廓了,但是鸭子身体中有很多小点被扣去了(属于误判为湖水),这种情况可以改变一些选取的像素点,或者增加一些样本,可以优化分割的效果。
再来看Python的实现吧。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/7/22 13:58
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : svm_split_picture.py
'''
@Description:SVM 将在湖中的一只鸭子与湖水分割出来
'''
from PIL import Image
import numpy as np
from sklearn.svm import SVC # 非线性 分类 SVM
pic = 'duck.jpg' # 鸭子图片
img = Image.open(pic)
img.show() # 显示原始图像
img_arr = np.asarray(img,np.float64)
# 选取湖面上的关键点RGB值(10个)
lake_RGB = np.array(
[[147,168,125],[151,173,124],[143,159,112],[150,168,126],[146,165,120],
[145,161,116],[150,171,130],[146,112,137],[149,169,120],[144,160,111]]
)
# 选取鸭子上的关键点RGB值(10个)
duck_RGB = np.array(
[[81,76,82],[212,202,193],[177,159,157],[129,112,105],[167,147,136],
[237,207,145],[226,207,192],[95,81,68],[198,216,218],[197,180,128]]
)
RGB_arr = np.concatenate((lake_RGB,duck_RGB),axis=0) # 按列拼接
# lake 用 0标记,duck用1标记
label = np.append(np.zeros(lake_RGB.shape[0]),np.ones(duck_RGB.shape[0]))
# 原本 img_arr 形状为(m,n,k),现在转化为(m*n,k)
img_reshape = img_arr.reshape([img_arr.shape[0]*img_arr.shape[1],img_arr.shape[2]])
svc = SVC(kernel='poly',degree=3) # 使用多项式核,次数为3
svc.fit(RGB_arr,label) # SVM 训练样本
predict = svc.predict(img_reshape) # 预测测试点
lake_bool = predict == 0. # 为湖面的序号(bool)
lake_bool = lake_bool[:,np.newaxis] # 增加一列(一维变二维)
lake_bool_3col = np.concatenate((lake_bool,lake_bool,lake_bool),axis=1) # 变为三列
lake_bool_3d = lake_bool_3col.reshape((img_arr.shape[0],img_arr.shape[1],img_arr.shape[2])) # 变回三维数组(逻辑数组)
img_arr[lake_bool_3d] = 255. # 将湖面像素点变为白色
img_split = Image.fromarray(img_arr.astype('uint8')) # 数组转image
img_split.show() # 显示分割之后的图像
img_split.save('split_duck.jpg') # 保存结果如图9所示: (图9)
(图9)
可以看出,图9的效果要比图8好很多,基本已经将湖水全部去除了,只有少数点没有去除,如果增加一些训练样本,训练的效果应该会更好,大家有兴趣的可以自己尝试一下。不过我很奇怪的是,Matlab与pyhton我选取的像素点是一模一样的,SVM训练设置参数也是一样的,为什么python的效果要明显好于Matlab呢?我没有阅读二者SVM的源码,不好下结论,姑且认为是Python大法好吧!!!哈哈哈......
以上就是主要要讲的内容了。其实SVM在最近几年神经网络大火之前还是非常受欢迎的,不过现在做复杂分类(比如图像分类,语音识别等)好像更倾向于神经网络了,SVM的一个重大缺点就是其对于处理大规模数据不是很适合,因为其主流的算法复杂度都是(O(n^2))的,不过其在高维数据以及规模适中的情况下做分类效果还是很不错的。以后有机会再来和大家探讨深度学习以及神经网络吧,目前正入坑中。。。
Reference
- 《数据挖掘概念与技术》
- 《神经网络与机器学习》
- 《Python大战机器学习》
- 《Matlab在数学建模中的应用》
特别感谢《Matlab在数学建模中的应用》,图像分割的那个例子Matlab代码改编于此,Python代码也是基于此书改写的。
最后
以上就是快乐歌曲最近收集整理的关于以图像分割为例浅谈支持向量机(SVM)的全部内容,更多相关以图像分割为例浅谈支持向量机(SVM)内容请搜索靠谱客的其他文章。








发表评论 取消回复