SVM 支持向量机(二)
1、支持向量机
这样,由于 w , x mathbf{w,x} w,x初始值的不同,最后得到的分割超平面也有可能不同,那么一定存在一个最优的超平面,这种方法就是支持向量机。
由上述可知感知机模型,即在数据集线性可分的条件下,利用分割超平面 w T ⋅ x + b = 0 mathbf {w^T cdot x} + mathbf b = 0 wT⋅x+b=0 把样本点划分为两类,通过计算误分类点距离超平面距离总和作为损失函数,使其最小化从而调整超平面,直至所有误分类点被纠正正确后迭代结束。
因为 w T , b mathbf {w^T ,b} wT,b 的取值不同,所以得到的分割超平面也可能不相同,所以感知机模型得到的超平面可能有多个,这就是不适定问题。那么,支持向量机模型就是找到一个最优的分割超平面。
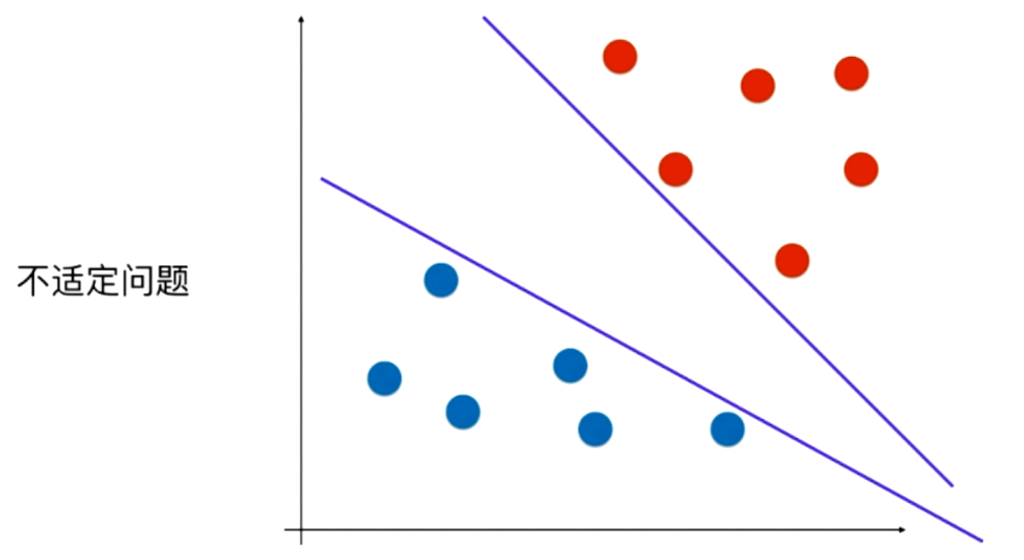
SVM模型和感知机模型一样。SVM模型的方法是:不仅要让样本点被分割超平面分开,还希望那些离分割超平面最近的点到分割超平面的距离最小。
SVM 和 线性分类器对比如下:
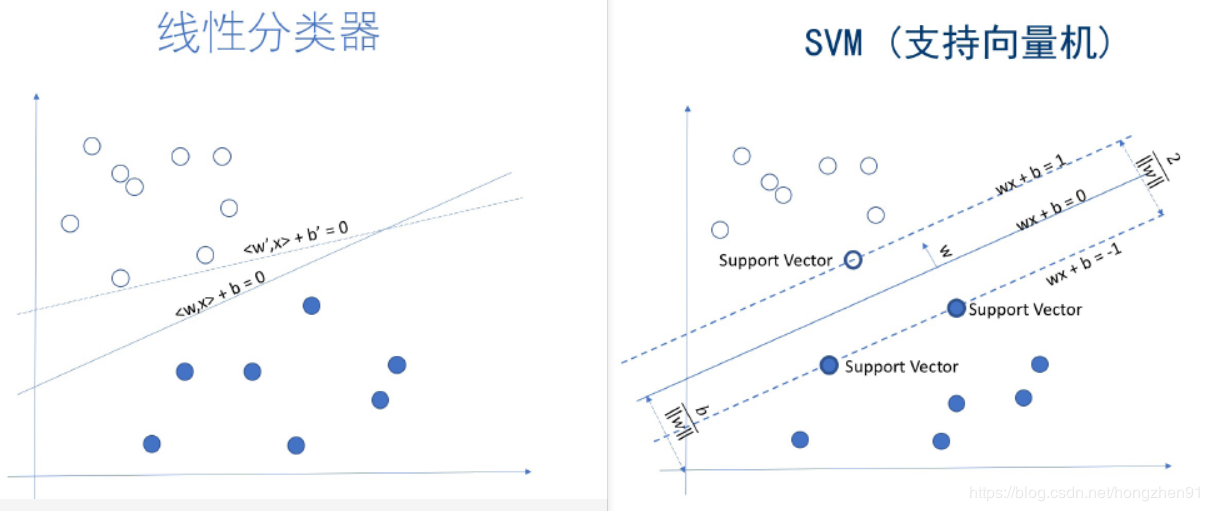
支持向量机(SVM)是一个功能强大并且全面的机器学习模型,它能够执行线性或非线性分类问题、回归问题,甚至是异常值检测任务。
支持向量机分为两种:硬间隔支持向量机和软间隔支持向量机。
SVM的思想:不仅要让样本点被分割超平面分开,还要去离分割平面最近的点(min)到分割超平面的距离尽可能远(max)。这些点称为支持向量,即支持向量到决策边界的距离尽可能远。
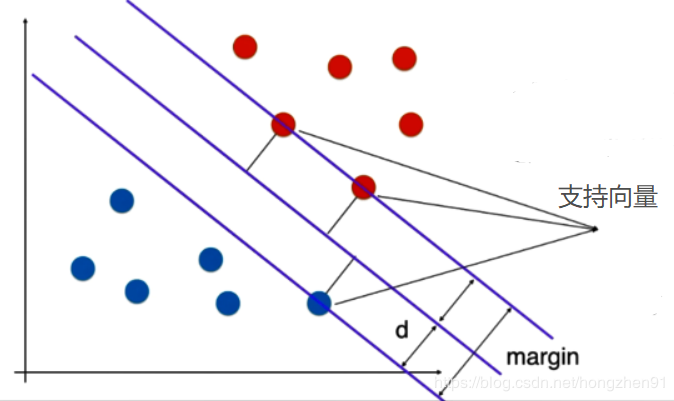
决策边界和支持向量关系如下:
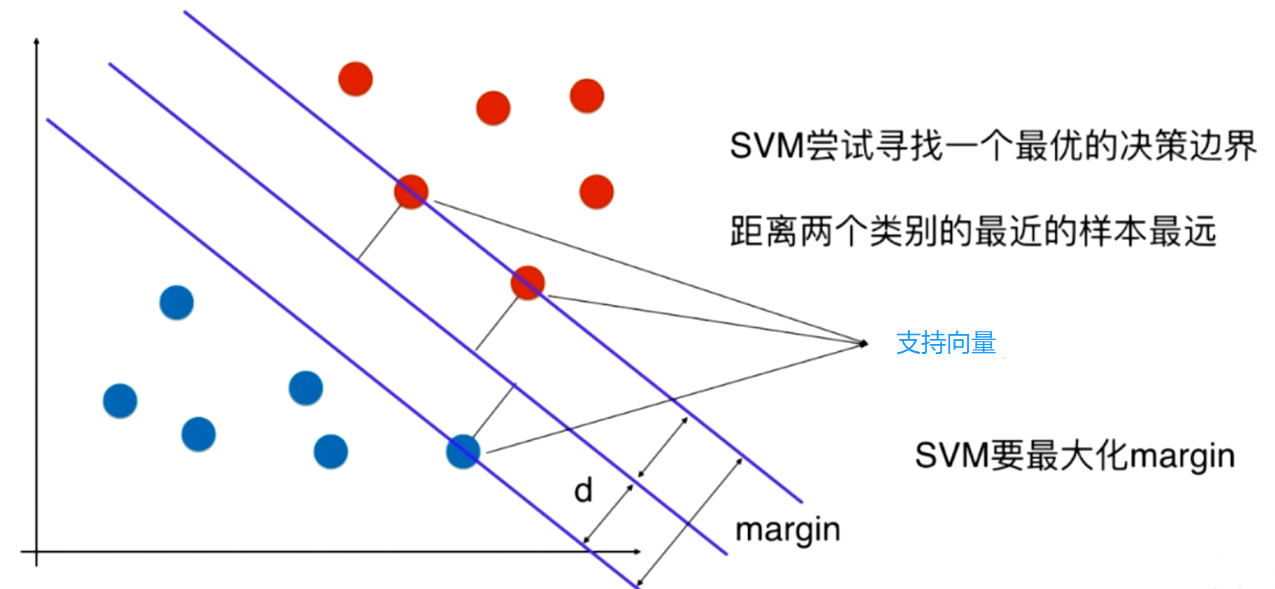
2、硬间隔支持向量机(Hard Margin SVM)
2.1、数学方法推导
2.1.1、点到直线的距离
由解析几何的知识,可知,二维平面中,点
(
x
,
y
)
(x, y)
(x,y)到直线
A
x
+
B
y
+
C
=
0
Ax + By +C = 0
Ax+By+C=0的距离为:
d
=
∣
A
x
+
B
y
+
C
∣
A
2
+
B
2
d = frac{|Ax + By +C |}{sqrt{A^2 + B^2}}
d=A2+B2∣Ax+By+C∣
则,拓展到 n 维空间中,
w
x
+
b
=
0
mathbf {wx + b} = 0
wx+b=0,点到直线的距离为:
d
=
∣
w
x
+
b
∣
∣
∣
w
∣
∣
,
∣
∣
w
∣
∣
=
w
1
2
+
w
2
2
+
.
.
.
+
w
n
2
d = frac{| mathbf {wx + b} |}{ ||mathbf w||} quad , quad ||mathbf w|| = sqrt{w_1^2 + w_2^2 + ... +w_n^2 }
d=∣∣w∣∣∣wx+b∣,∣∣w∣∣=w12+w22+...+wn2
其中,
∣
∣
w
∣
∣
||mathbf w||
∣∣w∣∣ 或
∣
∣
w
∣
∣
2
||mathbf w||_2
∣∣w∣∣2也叫 “ L2范数 ”,也就是模。当数据为 n 维时,直线就变成了平面,
w
mathbf w
w 可以表示超平面的法向量。
2.1.2、超平面的建立
对于给定样本点: D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } , y = { − 1 , 1 } D={ (x_1,y_1), (x_2,y_2), ... , (x_n,y_n) } , y={ -1, 1 } D={(x1,y1),(x2,y2),...,(xn,yn)} , y={−1,1},这里的 y y y 是指的样本点的标签,因为 SVM 解决二分类问题,所以只有 ±1 两种标签。
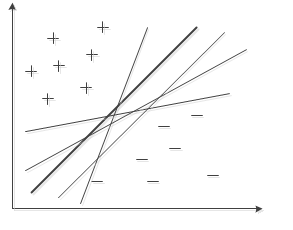
如上图,将两类样本点分开的直线有无数多条,那么 SVM 选择最优的一条直线即上述推导,使离分割超平面最近的点的距离最大,也就是几何间隔最大化。从图中观察可知,中间最粗的黑色直线是当前最好的分割超平面。
2.1.3、两种距离
1. 函数间隔
考虑样本点求解到超平面的距离公式中,对于同一个超平面而言,距离公式中的分母都是相同的,即
∣
∣
w
∣
∣
||mathbf w||
∣∣w∣∣,所以,比较各个样本点到超平面距离的远近,只比较分子即可,即
∣
w
⋅
x
+
b
∣
| mathbf{w cdot x + b}|
∣w⋅x+b∣, 而对于函数值的正负号与类别标签是否一致表示了分类正确性,即
h
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
h(mathbf x) = sign(mathbf{w cdot x + b})
h(x)=sign(w⋅x+b)的符号。如果
f
f
f 与样本点标签
y
y
y 同号,则代表分类正确;反之,分类错误。而
∣
y
∣
≡
1
|y| equiv 1
∣y∣≡1,所以可以使用
y
(
w
⋅
x
+
b
)
y(mathbf{w cdot x + b})
y(w⋅x+b)表示样本点分类正确与否的判断,将该式称为函数间隔:
γ
∼
i
=
y
⋅
(
w
⋅
x
i
+
b
)
overset{sim}gamma_i = y cdot (mathbf{w cdot x_i + b})
γ∼i=y⋅(w⋅xi+b)
对于数据集D,最终的目的是要选取所有样本点中最小的函数间隔作为整个数据集到超平面的函数间隔。目的是为了找到数据集中的某些样本点,这些样本点满足到超平面的距离最近,这些点就是支持向量。然后,使这些点到超平面距离最远得到的参数
w
mathbf w
w 所对应的超平面就是最优的超平面。又因为定义的分割超平面
w
⋅
x
+
b
=
0
mathbf{w cdot x +b = 0}
w⋅x+b=0,所以支持向量距离最近,即对应的函数值
f
(
w
,
x
i
,
b
)
=
w
⋅
x
i
+
b
f(w,x_i,b)=mathbf{w cdot x_i +b}
f(w,xi,b)=w⋅xi+b 最小,因为在分割超平面两侧都有支持向量,所以距离超平面远近和正负号没有关系,所以可以用函数间隔表示,即:
γ
∼
=
m
i
n
γ
∼
i
,
i
=
1
,
.
.
,
n
overset{sim}gamma = min overset{sim}gamma_i quad , quad i=1,..,n
γ∼=min γ∼i,i=1,..,n
函数间隔,表征的是样本点在函数值上和分割超平面函数值(=0)的“远近”
2. 几何间隔
函数间隔无法决定所要选择的超平面是哪一个。因为当我们把 w , b mathbf{w, b} w,b 都扩大2倍,那么函数间隔 γ ∼ overset{sim}gamma γ∼(函数值)也会跟着扩大2倍,但是超平面并没有发生改变,还是原来的超平面。所以需要增加一些某些约束,所以,采用几何间隔。
由上可知,几何间隔可以用函数间隔表示:
γ
=
γ
∼
∣
∣
w
∣
∣
γ
∼
=
γ
⋅
∣
∣
w
∣
∣
gamma = frac{overset{sim}gamma}{||mathbf w||} \ \ overset{sim}gamma = gamma cdot ||mathbf w||
γ=∣∣w∣∣γ∼γ∼=γ⋅∣∣w∣∣
由于几何间隔
γ
gamma
γ 是支持向量到超平面的距离,满足最小,所以其他样本点到超平面的几何距离都大于等于
γ
gamma
γ ,即:
y
i
⋅
(
w
⋅
x
i
+
b
)
∣
∣
w
∣
∣
≥
γ
frac{y_i cdot (mathbf{w cdot x_i + b})}{||mathbf w||} ≥ gamma
∣∣w∣∣yi⋅(w⋅xi+b)≥γ
几何间隔,表征的是样本点到分割超平面实际距离的远近
2.1.3、SVM 求解目标
根据 SVM 模型的思想,即需要求解以下优化问题:
max
w
,
b
γ
s
.
t
.
y
i
⋅
(
w
⋅
x
i
+
b
)
∣
∣
w
∣
∣
≥
γ
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & maxlimits_{mathbf{w, b}} gamma \ & s.t. quad frac{y_i cdot (mathbf{w cdot x_i + b})}{||mathbf w||} ≥ gamma quad , quad i=1,2,...,n end{aligned}
w,bmax γs.t.∣∣w∣∣yi⋅(w⋅xi+b)≥γ,i=1,2,...,n
即:
max
w
,
b
γ
s
.
t
.
y
i
⋅
(
w
⋅
x
i
+
b
)
≥
γ
⋅
∣
∣
w
∣
∣
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & maxlimits_{mathbf{w, b}} gamma \ \ & s.t. quad y_i cdot (mathbf{w cdot x_i + b}) ≥ gamma cdot ||mathbf w|| quad , quad i=1,2,...,n end{aligned}
w,bmax γs.t.yi⋅(w⋅xi+b)≥γ⋅∣∣w∣∣,i=1,2,...,n
上式又等价于:
max
w
,
b
γ
∼
∣
∣
w
∣
∣
s
.
t
.
y
i
⋅
(
w
⋅
x
i
+
b
)
≥
γ
∼
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & maxlimits_{mathbf{w, b}} frac{overset{sim}gamma}{||mathbf w|| } \ \ & s.t. quad y_i cdot (mathbf{w cdot x_i + b}) ≥ overset{sim}gamma quad , quad i=1,2,...,n end{aligned}
w,bmax ∣∣w∣∣γ∼s.t.yi⋅(w⋅xi+b)≥γ∼,i=1,2,...,n
由于函数间隔的大小取值对最终优化问题不产生影响,因为无论函数间隔取值多少,最终目的是为了寻找最优的
w
,
b
mathbf{w, b}
w,b。所以为了简单,不妨直接取
γ
∼
=
1
overset{sim}gamma = 1
γ∼=1。
所以上式可进一步变形:
max
w
,
b
1
∣
∣
w
∣
∣
s
.
t
.
y
i
⋅
(
w
⋅
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & maxlimits_{mathbf{w, b}} frac{1}{||mathbf w|| } \ \ & s.t. quad y_i cdot (mathbf{w cdot x_i + b}) ≥ 1 quad , quad i=1,2,...,n end{aligned}
w,bmax ∣∣w∣∣1s.t.yi⋅(w⋅xi+b)≥1,i=1,2,...,n
等价于:
min
w
,
b
1
2
⋅
∣
∣
w
∣
∣
2
s
.
t
.
y
i
⋅
(
w
⋅
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & minlimits_{mathbf{w, b}} frac{1}{2}cdot ||mathbf w||^2 \ \ & s.t. quad y_i cdot (mathbf{w cdot x_i + b}) ≥ 1 quad , quad i=1,2,...,n end{aligned}
w,bmin 21⋅∣∣w∣∣2s.t.yi⋅(w⋅xi+b)≥1,i=1,2,...,n
所以,上式即SVM最终需要优化求解的目标函数。
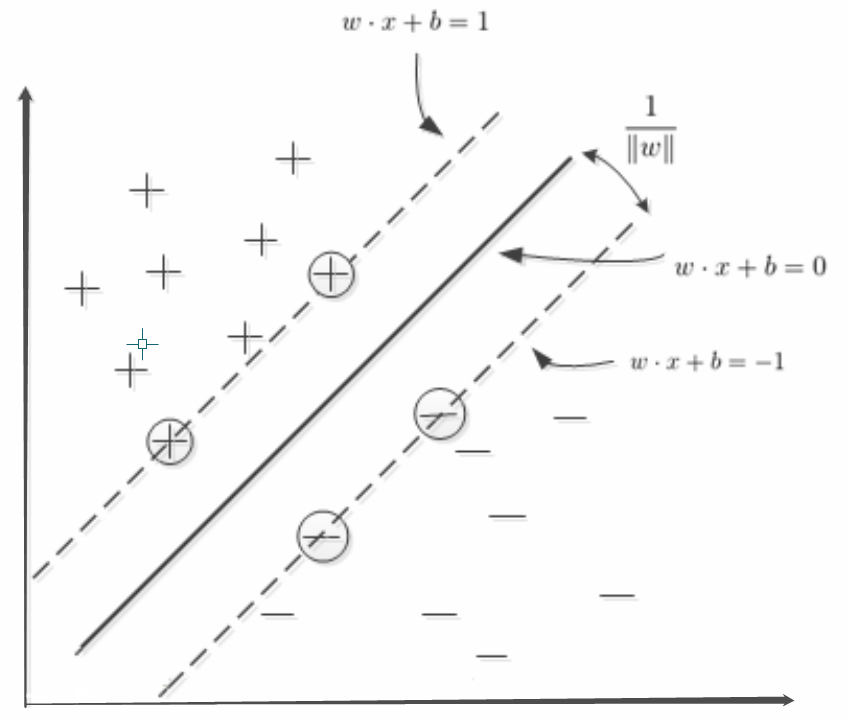
我们令 γ ∼ = 1 overset{sim}gamma = 1 γ∼=1,也就意味着到超平面的距离为1的点都是支持向量,即下图中画圈的点,如下图所示:
2.2、模型方法推导
对于上述数学推导较为复杂,不易理解,根据支持向量机可以直观的从SVM模型思想上进行推导。
所以,对于数据集的样本点,有:
{
∣
w
⋅
x
+
b
∣
∣
∣
w
∣
∣
2
≥
d
,
∀
y
(
i
)
=
+
1
∣
w
⋅
x
+
b
∣
∣
∣
w
∣
∣
2
≥
d
,
∀
y
(
i
)
=
−
1
begin{cases} frac{| mathbf {wcdot x + b} |}{ ||mathbf w||_2} ≥ d , forall y^{(i)} = +1 \ \ frac{| mathbf {wcdot x + b} |}{ ||mathbf w||_2} ≥ d , forall y^{(i)} = -1 \ end{cases}
⎩⎪⎨⎪⎧ ∣∣w∣∣2∣w⋅x+b∣≥d, ∀y(i)=+1 ∣∣w∣∣2∣w⋅x+b∣≥d, ∀y(i)=−1
将上式分子分母同时除以
d
d
d,可得:
{
∣
w
⋅
x
+
b
∣
∣
∣
w
∣
∣
d
≥
1
,
∀
y
(
i
)
=
+
1
∣
w
⋅
x
+
b
∣
∣
∣
w
∣
∣
d
≤
−
1
,
∀
y
(
i
)
=
−
1
begin{cases} frac{| mathbf {wcdot x + b} |}{ ||mathbf w||d} ≥ 1 , forall y^{(i)} = +1 \ \ frac{| mathbf {wcdot x + b} |}{ ||mathbf w||d} ≤ -1 , forall y^{(i)} = -1 \ end{cases}
⎩⎪⎨⎪⎧ ∣∣w∣∣d∣w⋅x+b∣≥1, ∀y(i)=+1 ∣∣w∣∣d∣w⋅x+b∣≤−1, ∀y(i)=−1
令
w
d
=
∣
w
∣
∣
∣
w
∣
∣
d
,
b
d
=
∣
b
∣
∣
∣
w
∣
∣
d
mathbf {w_d } = frac{| mathbf {w} |}{ ||mathbf w||d} , mathbf {b_d} = frac{| mathbf {b} |}{ ||mathbf w||d}
wd=∣∣w∣∣d∣w∣, bd=∣∣w∣∣d∣b∣ ,所以,可得下式:
{
w
d
x
+
b
d
≥
1
,
∀
y
(
i
)
=
+
1
w
d
x
+
b
d
≤
−
1
,
∀
y
(
i
)
=
−
1
begin{cases} mathbf {w_dx + b_d } ≥ 1 , forall y^{(i)} = +1 \ \ mathbf {w_dx + b_d } ≤ -1 , forall y^{(i)} = -1 \ end{cases}
⎩⎪⎨⎪⎧ wdx+bd≥1, ∀y(i)=+1 wdx+bd≤−1, ∀y(i)=−1
不妨令
w
=
w
d
b
=
b
d
mathbf {w = w_d } , mathbf {b = b_d }
w=wd b=bd ,所以:
{
w
⋅
x
+
b
≥
1
,
∀
y
(
i
)
=
+
1
w
⋅
x
+
b
≤
−
1
,
∀
y
(
i
)
=
−
1
begin{cases} mathbf {w cdot x + b } ≥ 1 , forall y^{(i)} = +1 \ \ mathbf {w cdot x + b } ≤ -1 , forall y^{(i)} = -1 \ end{cases}
⎩⎪⎨⎪⎧ w⋅x+b≥1, ∀y(i)=+1 w⋅x+b≤−1, ∀y(i)=−1
对于公式(6)可得;
-
对于分类正确的样本点,有 y i ( w ⋅ x + b ) ≥ 1 > 0 y_i ( mathbf{w cdot x + b} ) ≥1 > 0 yi(w⋅x+b)≥1>0 恒成立,即:
- y i = + 1 y_i = +1 yi=+1时,有 w ⋅ x + b > 0 mathbf{w cdot x + b} >0 w⋅x+b>0 ;
- y i = − 1 y_i = -1 yi=−1时,有 w ⋅ x + b < 0 mathbf{w cdot x + b}<0 w⋅x+b<0 。
-
对于分类错误的样本点,有 y i ( w ⋅ x + b ) ≤ − 1 < 0 y_i ( mathbf{w cdot x + b} ) ≤ -1 < 0 yi(w⋅x+b)≤−1<0 恒成立,即:
- y i = + 1 y_i = +1 yi=+1时,有 w ⋅ x + b < 0 mathbf{ w cdot x + b}<0 w⋅x+b<0 ;
- y i = − 1 y_i = -1 yi=−1时,有 w ⋅ x + b > 0 mathbf{w cdot x + b}>0 w⋅x+b>0 。
所以,对于正确分类的样本点,恒有: y i ⋅ ( w ⋅ x i + b ) ≥ 1 y_icdot ( mathbf {w cdot x_i + b} ) ≥ 1 yi⋅(w⋅xi+b)≥1
所以,可得 SVM 最终优化目标:
min w , b 1 2 ⋅ ∣ ∣ w ∣ ∣ 2 s . t . y i ⋅ ( w ⋅ x i + b ) ≥ 1 , i = 1 , 2 , . . . , n begin{aligned} & minlimits_{mathbf{w, b}} frac{1}{2}cdot ||mathbf w||^2 \ \ & s.t. quad y_i cdot (mathbf{w cdot x_i + b}) ≥ 1 quad , quad i=1,2,...,n end{aligned} w,bmin 21⋅∣∣w∣∣2s.t.yi⋅(w⋅xi+b)≥1,i=1,2,...,n
结论同上。
2.3、硬间隔向量机求解
2.3.1、求最优解
利用拉个格朗日对偶性,使用求解对偶问题的方法可以得到问题的最优解。使用对偶问题求解的方法是因为更容易求解,且在后面更容易引入核函数。
第一步,可以构造拉格朗日函数:
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
−
∑
i
=
1
N
α
[
y
i
(
w
⋅
x
i
+
b
)
−
1
]
begin{aligned} L(mathbf{w,b},alpha) &= frac{1}{2}||mathbf w||^2 - sumlimits_{i=1}^Nalpha[y_i(mathbf{w cdot x_i + b}) -1 ] \ end{aligned}
L(w,b,α)=21∣∣w∣∣2−i=1∑Nα[yi(w⋅xi+b)−1]
其中,
α
=
(
α
1
,
α
2
,
.
.
.
,
α
N
)
alpha = (alpha_1 , alpha_2 ,..., alpha_N)
α=(α1,α2,...,αN) 是拉格朗日乘子向量,
α
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
alpha ≥ 0 , i=1,2,...,N
α≥0, i=1,2,...,N 。
由拉格朗日对偶性,上述问题的对偶问题是求极大极小问题,即:
max
α
min
w
,
b
L
(
w
,
b
,
α
)
maxlimits_{alpha} minlimits_{mathbf{w,b}} L(mathbf{w,b},alpha)
αmaxw,bminL(w,b,α)
(1)、先求解
min
w
,
b
L
(
w
,
b
,
α
)
minlimits_{mathbf{w,b}} L(mathbf{w,b},alpha)
w,bminL(w,b,α)
对
w
,
b
mathbf{w,b}
w,b 分别求偏导数,并令偏导数等于0,可得:
{
∂
∂
w
L
(
w
,
b
,
α
)
=
w
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
∂
∂
b
L
(
w
,
b
,
α
)
=
∑
i
=
1
N
α
i
y
i
=
0
⇒
{
w
=
∑
i
=
1
N
α
i
y
i
x
i
∑
i
=
1
N
α
i
y
i
=
0
begin{cases} frac{partial}{partial mathbf w}L(mathbf{w,b},alpha) &= mathbf w - sumlimits_{i=1}^Nalpha_i y_i mathbf x_i = 0 \ frac{partial}{partial mathbf b}L(mathbf{w,b},alpha) &= sumlimits_{i=1}^Nalpha_i y_i = 0 end{cases} quadquad Rightarrow begin{cases} mathbf w = sumlimits_{i=1}^Nalpha_i y_i mathbf x_i \ sumlimits_{i=1}^Nalpha_i y_i = 0 end{cases}
⎩⎪⎪⎨⎪⎪⎧∂w∂L(w,b,α)∂b∂L(w,b,α)=w−i=1∑Nαiyixi=0=i=1∑Nαiyi=0⇒⎩⎪⎪⎨⎪⎪⎧w=i=1∑Nαiyixii=1∑Nαiyi=0
带入拉格朗日函数,可得:
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
−
∑
i
=
1
N
α
i
[
y
i
(
w
⋅
x
i
+
b
)
−
1
]
=
1
2
w
⋅
∑
i
=
1
N
α
i
y
i
x
i
−
∑
i
=
1
N
α
i
[
y
i
(
w
⋅
x
i
+
b
)
−
1
]
=
−
1
2
w
⋅
∑
i
=
1
N
α
i
y
i
x
i
+
∑
i
=
1
N
α
i
=
−
1
2
(
∑
i
=
1
N
α
i
y
i
x
i
)
⋅
∑
j
=
1
N
α
j
y
j
x
j
+
∑
i
=
1
N
α
i
=
−
1
2
∑
j
=
1
N
∑
i
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
begin{aligned} L(mathbf{w,b},alpha) &= frac{1}{2}||mathbf w||^2 - sumlimits_{i=1}^Nalpha_i[y_i(mathbf{w cdot x_i + b}) -1 ] \ &= frac{1}{2}mathbf w cdot sumlimits_{i=1}^Nalpha_i y_i mathbf x_i - sumlimits_{i=1}^Nalpha_i[y_i(mathbf{w cdot x_i + b}) -1 ] \ &= -frac{1}{2}mathbf w cdot sumlimits_{i=1}^Nalpha_i y_i mathbf x_i + sumlimits_{i=1}^Nalpha_i \ &= -frac{1}{2}(sumlimits_{i=1}^Nalpha_i y_i mathbf x_i ) cdot sumlimits_{j=1}^Nalpha_j y_j mathbf x_j + sumlimits_{i=1}^Nalpha_i \ &= -frac{1}{2}sumlimits_{j=1}^N sumlimits_{i=1}^Nalpha_i alpha_j y_i y_j (mathbf {x_i cdot x_j}) + sumlimits_{i=1}^Nalpha_i \ end{aligned}
L(w,b,α)=21∣∣w∣∣2−i=1∑Nαi[yi(w⋅xi+b)−1]=21w⋅i=1∑Nαiyixi−i=1∑Nαi[yi(w⋅xi+b)−1]=−21w⋅i=1∑Nαiyixi+i=1∑Nαi=−21(i=1∑Nαiyixi)⋅j=1∑Nαjyjxj+i=1∑Nαi=−21j=1∑N i=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
所以,最后可得:
min
w
,
b
L
(
w
,
b
,
α
)
=
−
1
2
∑
j
=
1
N
∑
i
=
1
N
α
i
α
j
y
i
y
j
x
i
⋅
x
j
+
∑
i
=
1
N
α
i
minlimits_{mathbf{w,b}} L(mathbf{w,b},alpha) = -frac{1}{2}sumlimits_{j=1}^N sumlimits_{i=1}^Nalpha_i alpha_j y_i y_j mathbf {x_i cdot x_j} + sumlimits_{i=1}^Nalpha_i
w,bminL(w,b,α)=−21j=1∑N i=1∑Nαiαjyiyjxi⋅xj+i=1∑Nαi
从上式可知,
L
(
w
,
b
,
α
)
L(mathbf{w,b},alpha)
L(w,b,α) 的结果只取决于
(
x
i
⋅
x
j
)
(mathbf {x_i cdot x_j})
(xi⋅xj) ,即两个向量的点乘结果。
(2)、然后求解 max α min w , b L ( w , b , α ) maxlimits_{alpha} minlimits_{mathbf{w,b}} L(mathbf{w,b},alpha) αmaxw,bminL(w,b,α)
将第一步求解的结果带入对偶问题
max
α
min
w
,
b
L
(
w
,
b
,
α
)
maxlimits_{alpha} minlimits_{mathbf{w,b}} L(mathbf{w,b},alpha)
αmaxw,bminL(w,b,α) ,可得对偶优化问题:
max
α
−
1
2
∑
j
=
1
N
∑
i
=
1
N
α
i
α
j
y
i
y
j
x
i
⋅
x
j
+
∑
i
=
1
N
α
i
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
,
α
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & maxlimits_{alpha} -frac{1}{2}sumlimits_{j=1}^N sumlimits_{i=1}^Nalpha_i alpha_j y_i y_j mathbf {x_i cdot x_j} + sumlimits_{i=1}^Nalpha_i \ \ & s.t. quad sumlimits_{i=1}^Nalpha_i y_i = 0 quad , quad alpha_i ≥ 0 , i=1,2,...,n end{aligned}
αmax−21j=1∑N i=1∑Nαiαjyiyjxi⋅xj+i=1∑Nαis.t.i=1∑Nαiyi=0,αi≥0,i=1,2,...,n
等价于:
min
α
1
2
∑
j
=
1
N
∑
i
=
1
N
α
i
α
j
y
i
y
j
x
i
⋅
x
j
+
∑
i
=
1
N
α
i
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
,
α
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
n
begin{aligned} & minlimits_{alpha} frac{1}{2}sumlimits_{j=1}^N sumlimits_{i=1}^Nalpha_i alpha_j y_i y_j mathbf {x_i cdot x_j} + sumlimits_{i=1}^Nalpha_i \ \ & s.t. quad sumlimits_{i=1}^Nalpha_i y_i = 0 quad , quad alpha_i ≥ 0 , i=1,2,...,n end{aligned}
αmin 21j=1∑N i=1∑Nαiαjyiyjxi⋅xj+i=1∑Nαis.t.i=1∑Nαiyi=0,αi≥0,i=1,2,...,n
2.3.2、求解 w , b mathbf{w,b} w,b
w ∗ = ∑ i = 1 M α ∗ y i x i mathbf w^*= sumlimits_{i=1}^M alpha^* y_i mathbf x_i w∗=i=1∑Mα∗ yi xi
b ∗ = 1 S ∑ s = 1 S [ y s − w ∗ ⋅ x s ] mathbf b^*= frac{1}{S}sumlimits_{s=1}^S [ y_s - mathbf {w^* cdot x^s}] b∗=S1s=1∑S[ys−w∗⋅xs]
2.4、求解硬间隔支持向量机
输入:线性可分训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } T={ (mathbf x_1 ,y_1) ,(mathbf x_2 ,y_2), ..., (mathbf x_n ,y_n) } T={(x1,y1),(x2,y2),...,(xn,yn)},且 y i ∈ { − 1 , 1 } y_i in {-1,1} yi∈{−1,1}。
输出:分割超平面 w T ∗ ⋅ x + b ∗ = 0 mathbf {w^{T* }cdot x + b^*} = 0 wT∗⋅x+b∗=0 和分类决策函数 h ( x ) = s i g n ( w T x + b ) h(mathbf x) =sign(mathbf {w^Tx + b}) h(x)=sign(wTx+b)。
求解步骤:
-
构造约束优化问题.
min α 1 2 ⋅ ∑ i = 1 M α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 M α i s . t . ∑ i = 1 M α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . , M min_{alpha} frac{1}{2} cdot sumlimits_{i=1}^M alpha_i alpha_j y_i y_j (mathbf x_i cdot mathbf x_j) - sumlimits_{i=1}^M alpha_i \ s.t. quad sumlimits_{i=1}^M alpha_iy_i = 0 \ alpha_i ≥ 0 , i=1,2,...,M αmin 21⋅i=1∑Mαiαjyiyj(xi⋅xj)−i=1∑Mαis.t.i=1∑Mαiyi=0αi≥0,i=1,2,...,M -
利用SMO算法求解上面的优化问题,得到 α mathbf {alpha} α向量的值 α ∗ mathbf {alpha^*} α∗, α = ( α 1 , α 2 , . . , α M ) alpha = (alpha_1, alpha_2 ,.., alpha_M) α=(α1,α2,..,αM) 是拉格朗日乘子向量, α i ≥ 0 alpha_i ≥0 αi≥0 .
-
求解计算 w mathbf w w向量的值 w ∗ mathbf w^* w∗.
w ∗ = ∑ i = 1 M α ∗ y i x i mathbf w^*= sumlimits_{i=1}^M alpha^* y_i mathbf x_i w∗=i=1∑Mα∗ yi xi -
找到满足 α s ∗ > 0 alpha^*_s > 0 αs∗>0 对应的支持向量点 ( x s , y s ) (mathbf {x_s}, y_s ) (xs,ys),从而求解计算 b mathbf b b 的值 b ∗ mathbf {b^*} b∗.
b ∗ = 1 S ∑ s = 1 S [ y s − w ∗ ⋅ x s ] mathbf b^*= frac{1}{S}sumlimits_{s=1}^S [ y_s - mathbf {w^* cdot x^s}] b∗=S1s=1∑S[ys−w∗⋅xs] -
由 w ∗ mathbf w^* w∗ 和 b ∗ mathbf {b^*} b∗ 得到分割超平面 w ∗ ⋅ x + b ∗ = 0 mathbf {w^* cdot x + b^*} = 0 w∗⋅x+b∗=0 和分类决策函数 h ( x ) = s i g n ( w T ∗ + b ) h(mathbf x) =sign(mathbf {w^{T* } + b}) h(x)=sign(wT∗+b).
3、支持向量机实践
3.1、简单支持向量机
通过使用 sklearn.datasets 数据集实现简单的 SVM 。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns; sns.set()
# 1、创建模拟数据集
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
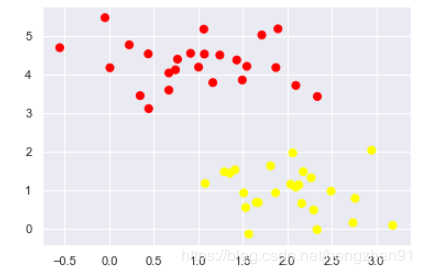
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn');
输出结果:
# 2、可以有多种方法分类
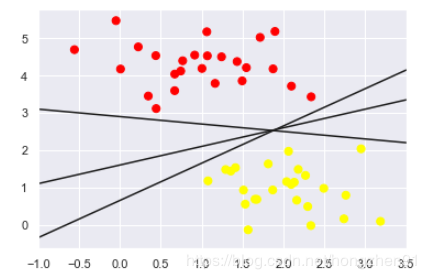
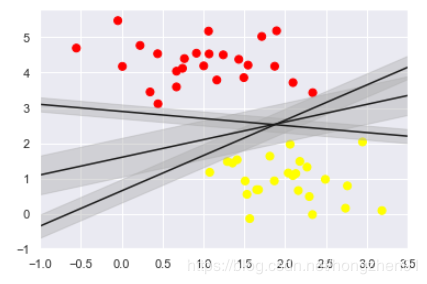
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, '-k')
plt.xlim(-1, 3.5);
输出结果:
SVM 的思想: 假想每一条分割线是有宽度的。在SVM的框架下, 认为最宽的线为最优的分割线
# 3、绘制有宽带的分割线
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
输出结果:
训练SVM
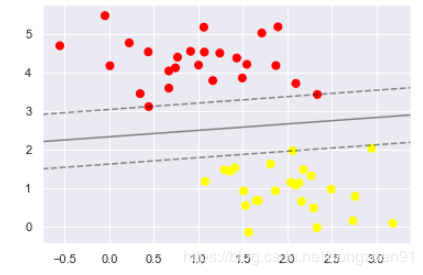
# 4、使用线性SVM和比较大的 C
from sklearn.svm import SVC # "Support vector classifier"
model = SVC(kernel='linear', C=1E10)
model.fit(X, y)
创建一个显示SVM分割线的函数
# 5、定义 SVM 分割线函数
def plot_svc_decision_function(model, ax=None, plot_support=True):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(model);
输出结果:
3.2、非线性支持向量机
3.2.1、SVM 中使用多项式特征
(1)、导入数据集
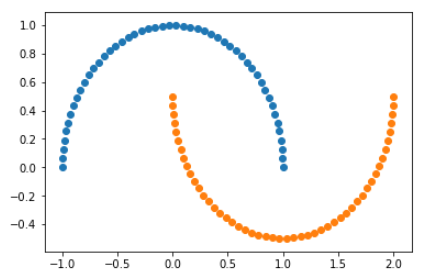
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons()
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
输出结果:
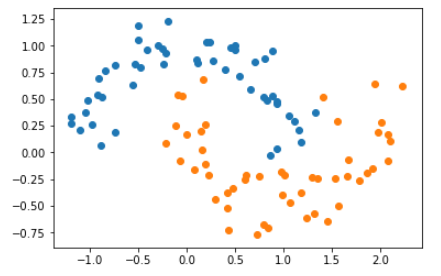
(2)、通过增加噪声,增大数据集标准差
X, y = datasets.make_moons(noise=0.15, random_state=666)
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
输出结果:
(3)、使用多项式核函数的SVM
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree, C=1.0):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("linearSVC", LinearSVC(C=C))
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
输出结果:
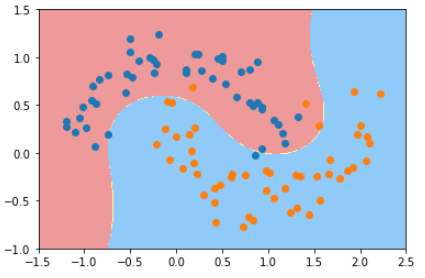
(4)、使用多项式核函数的SVM
from sklearn.svm import SVC
def PolynomialKernelSVC(degree, C=1.0):
return Pipeline([
("std_scaler", StandardScaler()),
("kernelSVC", SVC(kernel="poly", degree=degree, C=C))
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X, y)
输出结果:
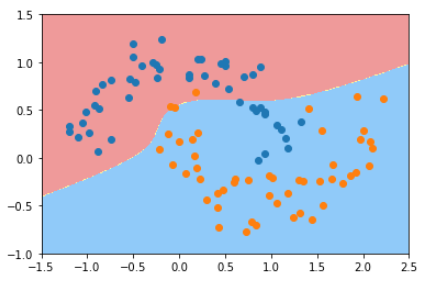
3.3、SVM 解决回归问题
SVM 解决回归问题和解决分类问题的思想正好相反。即SVM解决分类问题希望在margin中的数据点越少越好,而SVM解决回归问题则希望落在margin中的数据点越多越好。
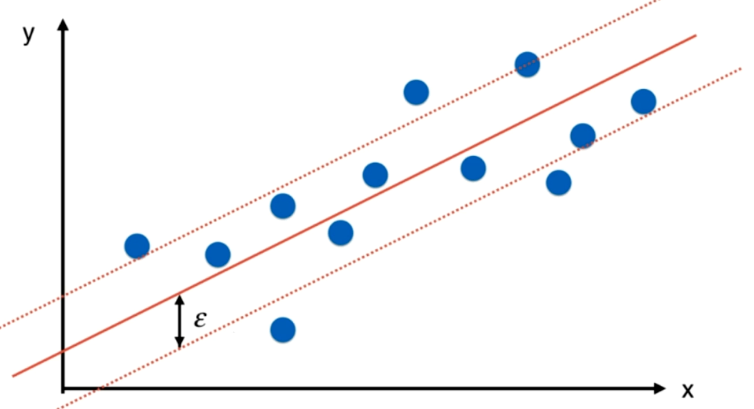
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
boston = datasets.load_boston()
X = boston.data
y = boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
def StandardLinearSVR(epsilon=0.1):
return Pipeline([
('std_scaler', StandardScaler()),
('linearSVR', LinearSVR(epsilon=epsilon))
])
svr = StandardLinearSVR()
svr.fit(X_train, y_train)
svr.score(X_test, y_test)
输出 output : 0.6358806887937369
3.4、SVM 实现人脸的分类识别
对输入的人脸图像使用PCA(主成分分析)将图像(看作一维向量)进行了降维处理,然后将降维后的向量作为支持向量机的输入。PCA降维的目的可以看作是特征提取, 将图像里面真正对分类有决定性影响的数据提取出来,从而实现支持向量机人脸的分类识别.。
(1)、导入人脸实例数据集
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
# 人脸实例
fig, ax = plt.subplots(3, 5)
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])

每一幅图的尺寸为 [62×47] , 大约 3000 个像素值。
我们可以将整个图像展平为一个长度为3000左右的一维向量, 然后使用这个向量做为特征. 通常更有效的方法是通过预处理提取图像最重要的特征. 一个重要的特征提取方法是PCA(主成分分析), 可以将一副图像转换为一个长度为更短的(150)向量。
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='linear', class_weight='balanced')
model = make_pipeline(pca, svc)
(2)、将数据分为训练和测试数据集
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,
random_state=42)
(3)、调参
通过交叉验证寻找最佳的 C (控制间隔的大小)
from sklearn.model_selection import GridSearchCV
param_grid = {'svc__C': [1, 5, 10, 50]}
grid = GridSearchCV(model, param_grid)
grid.fit(Xtrain, ytrain)
model = grid.best_estimator_
yfit = model.predict(Xtest)
(4)、使用训练好的SVM做预测
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == ytest[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14);
预测结果:

(5)、生成报告与混淆矩阵
from sklearn.metrics import classification_report
print(classification_report(ytest, yfit,
target_names=faces.target_names))
from sklearn.metrics import confusion_matrix
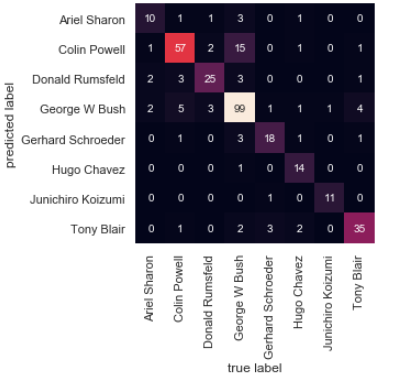
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');
报告数据
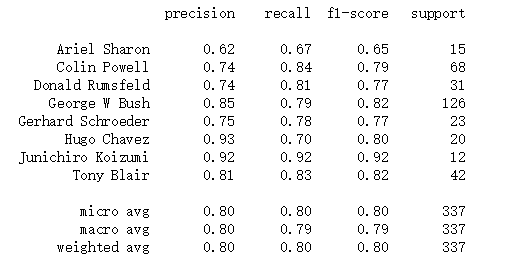
混淆矩阵
4、SVM总结
4.1、优点
- SVM模型具有很好的泛化能力,特别是在小样本训练集上能比其他算法得到好很多的结果。其本身的优化目标是结构化风险最小,通过引入 margin 的概念,可以得到数据分布的结构化描述,降低了对数据规模和数据分布的要求;
- 模型只需要保存支持向量, 模型占用内存少, 预测快;
- SVM 模型具有较强的数据理论支撑;
- 分类只取决于支持向量, 适合数据的维度高的情况, 例如DNA数据;
- SVM 模型引入核函数之后可以解决非线性分类问题,并且 SVM 模型还可以解决回归问题。
4.2、缺点
- SVM 模型不适合解决多分类问题,对于多分类问题,只能采用一对多模式间接实现;
- SVM 模型存在两个对结果影响比较大的超参数,如超参数惩罚项系数 c ,所以复杂度比一般非线性模型要高,需要做调参 c c c 当数据量大时非常耗时间;
- 训练的时间复杂度为 O [ N 3 ] mathcal{O}[N^3] O[N3] 或者至少 O [ N 2 ] mathcal{O}[N^2] O[N2], 当数据量巨大时候不合适使用。
4.4、SVM模型与 LR模型的异同
- SVM 与 LR 模型都是有监督的机器学习算法,且都属于判别模型;
- 如果不考虑 SVM 核函数情况,两者都属于是线性分类算法 ;
- SVM模型与 LR模型的构造原理不同;
- SVM模型与 LR模型在学习时考虑的样本点不同 ;
- SVM 模型中自带正则化项 1 2 ∣ ∣ w ∣ ∣ 2 frac{1}{2}||mathbf w||^2 21∣∣w∣∣2,和 LR模型相比,不容易产生过拟合问题。
文中实例及参考:
- 刘宇波老师《Python入门机器学习》
- 《机器学习基础》
- 贪心学院,https://www.greedyai.com
最后
以上就是大胆母鸡最近收集整理的关于【Python机器学习】之 SVM 支持向量机算法(二) SVM 支持向量机(二) 的全部内容,更多相关【Python机器学习】之内容请搜索靠谱客的其他文章。








发表评论 取消回复