离散LQR与iLQR的推导思路
- 一、最优控制
- 最优控制定义
- 数学基础
- 里程碑工作
- 二、LQR问题
- LQR定义
- 极小值原理方法求解
- 动态规划方法求解
- 两种方法的比较
- 三、iLQR框架
一、最优控制
最优控制定义
首先介绍一下LQR的背景,也就是最优控制,最优控制的背景在之前介绍HJB方程的时候也有介绍:HJB方程的一些简单理解和过程推导。假设现在有一辆自动驾驶汽车,我们要设置控制方法,让其沿着指定路线到达某一个位置。要完成这项工作,首要的任务就是了解这辆车当前的“状态”和关于“控制”的变化规律:比如我们一般最关心当前的位置和车速,通过当前位置和速度去进行控制,比如打方向盘,踩刹车,踩油门等,从而又会引起当前位置和车速的变化。与此同时,我们可能还希望省油,车速平稳,不超速等要求。要满足以上的需求,需要合理的设计控制方法,以上问题我们就可以把它写成一个最优控制问题。
最优控制问题的四个基本元素:
-
状态方程:描述系统(自动驾驶汽车)的运动学或动力学方程
x ˙ ( t ) = f ( x ( t ) , u ( t ) , t ) , t ∈ [ t 0 , t f ] . x ( t 0 ) = x 0 dot{x}(t)=f(x(t),u(t),t) , tin[t_0,t_f]. x(t_0)=x_0 x˙(t)=f(x(t),u(t),t),t∈[t0,tf].x(t0)=x0
-
容许控制:控制与状态满足的约束
u ∈ U , x ∈ X . uin U , xin X. u∈U,x∈X.
-
目标集:在结束时间 t f t_f tf,被控对象的状态 x ( t f ) x(t_f) x(tf)应符合的条件
S = { x ( t f ) : m ( x ( t f ) , t f ) = 0 } S= left{ x(t_f):m(x(t_f),t_f)=0 right} S={x(tf):m(x(tf),tf)=0}
- 性能指标:
h
h
h为终端成本,
g
g
g为运行成本
J ( u ) = h ( x ( t f ) , t f ) + ∫ t 0 t f g ( x ( t ) , u ( t ) , t ) d t . displaystyle{J(u)=h(x(t_f),t_f)+int_{t_0}^{t_f}g(x(t),u(t),t)dt.} J(u)=h(x(tf),tf)+∫t0tfg(x(t),u(t),t)dt.
最优控制可以理解为求解满足状态方程、容许控制,且能达到目标点的情况下使性能指标最优的控制。
数学基础
这里传统的最优控制方法主要有两个:一个是极小值原理,一个是动态规划。这两种方法的产生可谓是神仙打架。在冷战的最初十年中,美苏双方的空军部门都遇到了同一个问题——如何以最短的时间拦截敌方的飞机。双方各自组件了研究团队,寻找切合实际的通用数学工具。
美国自1948年开始进行研究,苏联1955年才开始正是组建团队。尽管苏联方面着手较晚,但是在1956-1957年间苏联团队提出适用范围极广的Pontryagin极小值原理而暂时胜出,美方在1952-1957年提出的动态规划方法则在20世纪60年代被发现可用于最优控制问题,在特定的情况下还可以得到和苏联相同的结果。
里程碑工作
在这场较量中,诞生出了许许多多的重要成果:
- Hestenes问题:寻求最优飞机攻角和坡度。首次使用了Hamiltonian函数
- Isaacs的问题:微分博弈
- Bellman的问题:Bang-Bang控制
- Bellman的多级决策问题与离散时间最优控制
- 开环控制与闭环控制
- Pontryagin极小值原理
- 连续时间最优控制问题与两点边值问题
- 二次性能指标与卡尔曼调节器问题
二、LQR问题
LQR定义
LQR问题其实是一种最简单的最优控制问题。L代表状态方程或者动力学方程是线性的。Q代表目标函数是二次的。具体形式如下:
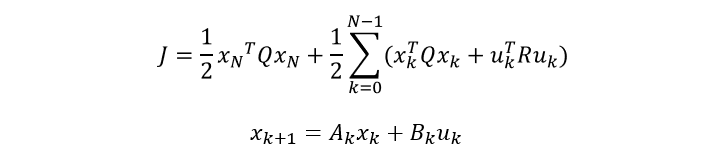
对于一个路径规划问题,当我们拥有了状态方程,通过任意给出控制,就可以产生无数条路径,而这些路径的优劣需要根据目标函数去抉择。所以我们希望找到一个控制率,这个控制率起一个向导的作用,当一个机器人在某一个位置的时候,控制率会告诉你在现在所处的位置,根据目标函数的判断标准最优控制应该是什么,这种思想的一个简单的数学表达是:
u
k
=
F
k
x
k
+
v
k
u_k=F_kx_k+v_k
uk=Fkxk+vk
这样可以理解为:状态方程+控制率=最优路径。所以在状态方程已知的情况下,我们的目标就是求解一个控制率,也就是控制对于位置的函数。
在搜索LQR问题的求解推导时,网上的方法不是很统一,这是因为一部分人使用的极小值原理,一部分人使用的是动态规划,下面分别对这两种方法进行简要说明。
极小值原理方法求解
在离散情况下的,极小值原理其实可以不必非要写成哈密尔顿方程的形式,更好理解的方式就是使用拉格朗日法,求解KKT条件。
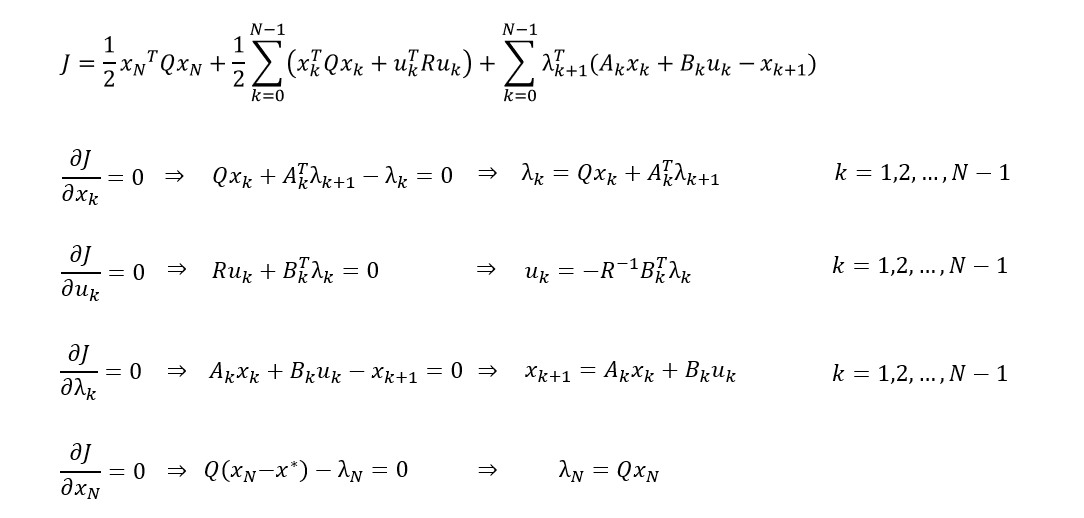
我们将动力学约束放入目标函数中,分别对变量和拉格朗日乘子进行求导,得出以下的四个方程,其中最后一个是终值条件。
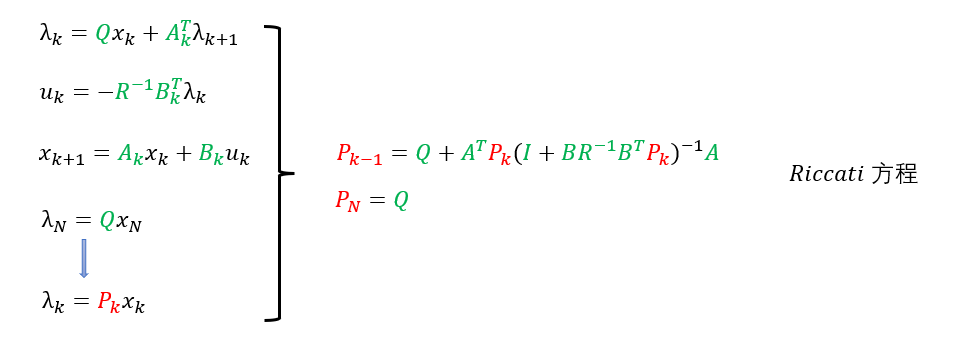
这里我们还需要根据这个终值条件做一个假设,在任意时刻的
λ
k
λ_k
λk都具有类似终值条件那样的形式,这里绿色是表示已知量,红色代表未知量。如果我们将红色的
P
P
P求解出来,那么将其带入到第二个式子中,不就把控制率求解出来了吗。我们将求解
P
P
P的这个方程成为:
R
i
c
c
a
t
i
Riccati
Riccati方程。一般来说迭代几步就会收敛。
通过这几个式子的消除变量,可以将
P
k
P_k
Pk的迭代式求解出来,而我们又已知了最后一个时刻的
P
P
P,这样就可以迭代的求出任意时刻的
P
P
P值,顺理成章的得出控制率:
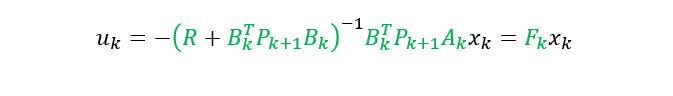
具体的推导过程可以详见:https://zhuanlan.zhihu.com/p/465054562
动态规划方法求解
使用动态规划之前需要了解什么是最优性原理,可以参考:HJB方程的一些简单理解和过程推导
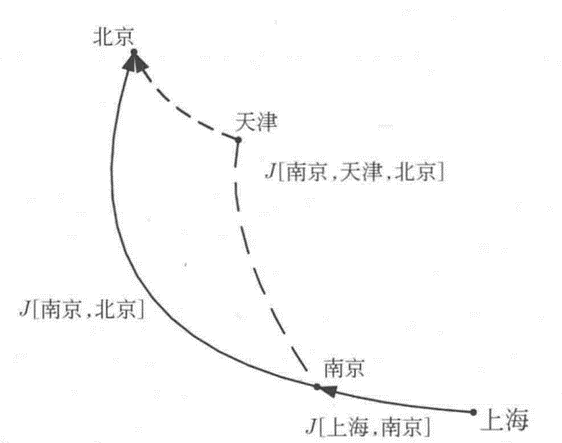
blog.csdnimg.cn/8bc06d608206439fa084555e331a12a5.png#pic_center)
我们的推导思路其实很简单,举个例子,已知从上海到北京的最短路径是上海-南京-北京,那么根据最优性原理,从南京到北京的最短路径是南京-北京,那么我们可以先求出南京-北京这一段的控制率,然后这段有了之后,再去求上海-南京-北京的最后路径,即从后往前求。
我们这里重新定义一下目标函数,因为要一个阶段一个阶段的求解,所以我们不妨设相邻两个状态的目标函数为:
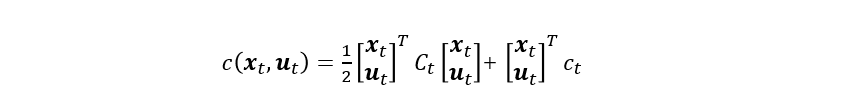
动力学方程为:
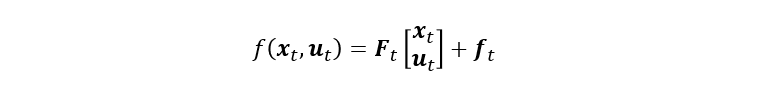
同样我们希望根据上面两个式子找到一个控制率:
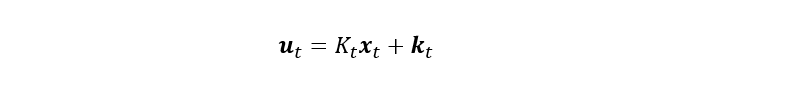
我们希望先求出南京-北京这段路的最优控制率,那么这一段的评判标准就是
c
(
x
T
,
u
T
)
c(x_T,u_T)
c(xT,uT),这里写成了他的展开形式:
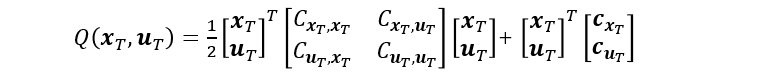
希望对于控制最优,所以直接对控制进行求导等于零,得出:
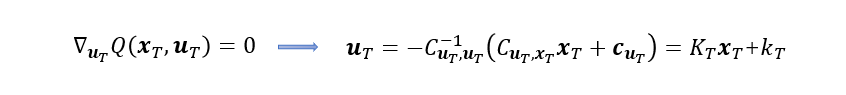
这样我们就轻而易举的求出了这一阶段的控制率,尝到了甜头,那么我们希望继续用这种方法求上海-南京-北京的最优控制率,也即找到
Q
(
x
T
−
1
,
u
T
−
1
)
Q(x_{T-1},u_{T-1})
Q(xT−1,uT−1),然后求导等于零,得出最优控制率。很自然的想法就是
Q
(
x
T
−
1
,
u
T
−
1
)
Q(x_{T-1},u_{T-1})
Q(xT−1,uT−1)的构建是:
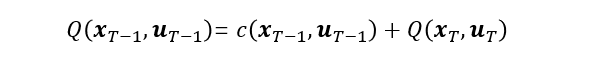
但是这里我们需要将
x
T
x_T
xT和
u
T
u_T
uT用
x
T
−
1
x_{T-1}
xT−1和
u
T
−
1
u_{T-1}
uT−1替换掉。如何替换呢?
其实就是简单的变量消除。首先我们可以使用得到的最优控制,将
u
T
u_T
uT用
x
T
x_T
xT替换掉:
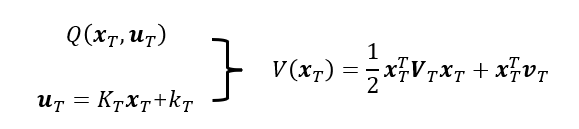
其中:
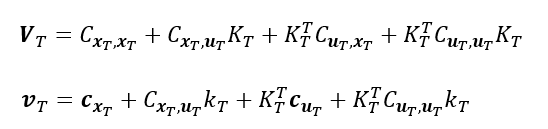
之后使用状态方程或者动力学防尘将:
x
T
x_T
xT替换成
x
T
−
1
x_{T-1}
xT−1和
u
T
−
1
u_{T-1}
uT−1:
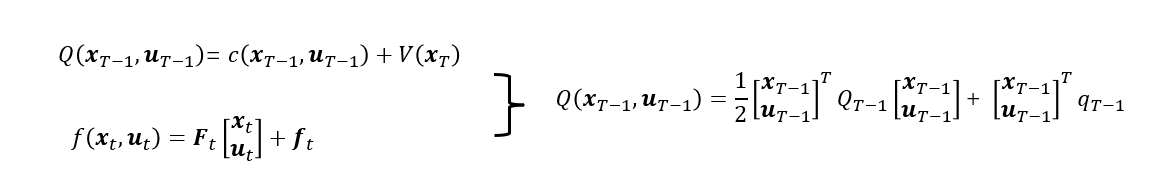
其中:
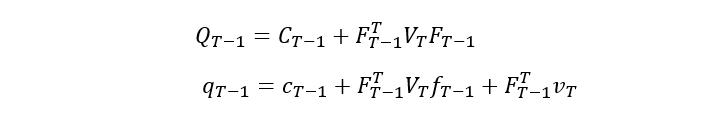
这样我们就可以对其进行求导,如此向前迭代,求出最优控制率,整理成算法就呈现出了如下的反向迭代结构:
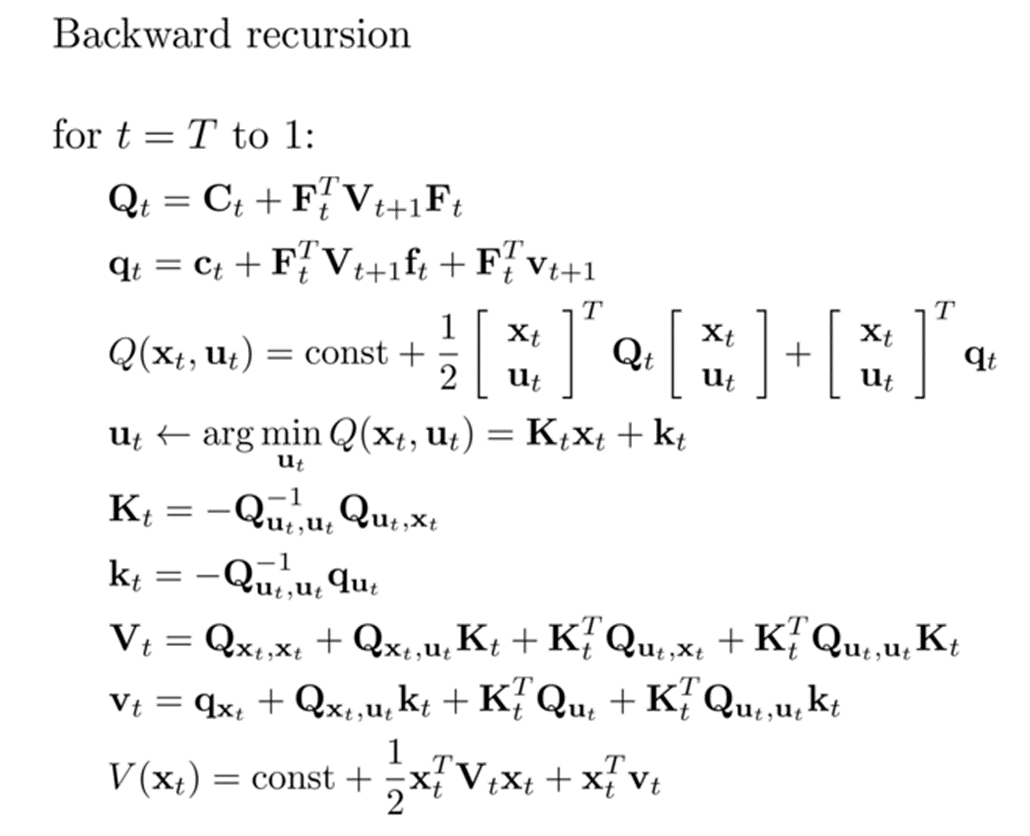
两种方法的比较
对于极小值原理,求解的一个开环问题。通过使用变分法,基于哈密尔顿方程组,一次性将最优曲线求解出来。
对于动态规划,他求解的是一个闭环问题。通过将问题变成一个多级决策问题,使用最优性原理,通过迭代的方式求出曲线。
两者虽然出发点不同,但是在求解问题的时候都有一个反馈-前馈结构。反馈主要体现在控制率的求解,前馈体现是使用控制率和状态方程计算轨迹。
三、iLQR框架
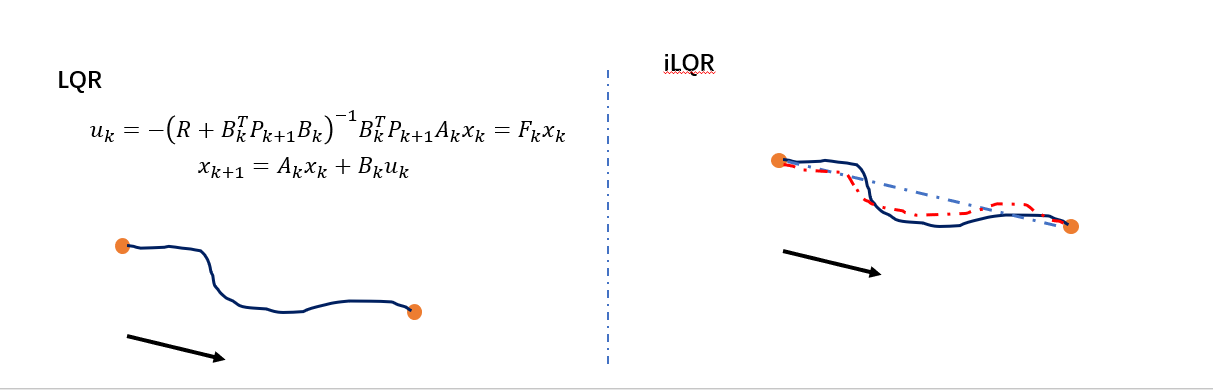
对于LQR问题,可以根据求解出来的控制率和状态方程,直接算出最优轨迹,如左边的示意图。
对于iLQR,其实就是目标函数和状态方程出现了非线性,这个时候控制率不是那么好求解。解决思路就是使用迭代的思想进行求解。首先给定一个初始的轨迹,如蓝色的直线,那么为了让其能够求解,可以将目标函数泰勒二次展开,状态方程泰勒一阶展开,之后使用LQR算法生成一条新的轨迹,如红色的虚线,之后反复迭代,直到轨迹的变化在一个规定的极小值内,就认为收敛,达到了最优。
具体的算法可以参考文献:Iterative Linear Quadratic Regulator Design for Nonlinear Biological Movement Systems。
推导思路是使用极小值原理。
最后
以上就是舒适宝马最近收集整理的关于离散LQR与iLQR的推导思路一、最优控制二、LQR问题三、iLQR框架的全部内容,更多相关离散LQR与iLQR内容请搜索靠谱客的其他文章。








发表评论 取消回复