Accurate Scale Estimation for Robust Visual Tracking DSST学习笔记:
尺度变化是跟踪中比较基础和常见的问题,目标变小,跟踪器就会吸收大量没有用的背景信息,目标过大,跟踪器就会丢失很多特征。
Accurate Scale Estimation for Robust Visual Tracking
DSST (Discriminative Scale Space Tracker)是VOT2014年的冠军。
作者的主页是:http://www.cvl.isy.liu.se/en/research/objrec/visualtracking/
DSST算法是基于MOSSE
correlation filter做的改进和拓展,实现了快速且准确的目标尺度评估,原程序有详细的注释。
首先是算法的理解:
基于mosse tracker的改进,原理:相关滤波原理在: https://mp.csdn.net/mdeditor/88087940#
本文的改进:
l是维数,位置滤波器用的28,尺寸滤波器用的是33,h是改进的相关滤波器,是训练或者是前一帧的图片,是通过滤波器输出的图片,也就是后一帧的图片。λ是调整参数需要大于一,用以控制影响正则化的影响。作者建立了一个改进的模型:(我类似mosse模型进行改写,便于自己理解)
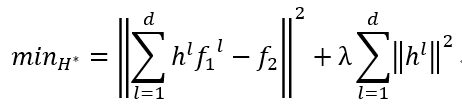
FFT之后求偏导,与MOSSE类似,化简得到:
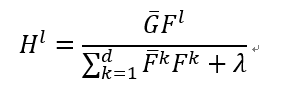
G是傅里叶变换后的,F是傅里叶变换后的,再求解的过程中,分别计算分子和分母:
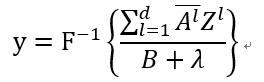
F是逆傅里叶变换,A分子,B分母,z是计算出来的特征图,通过改变z的值从而改变y的值,当y最大时,就是相关滤波器最适配的时候。
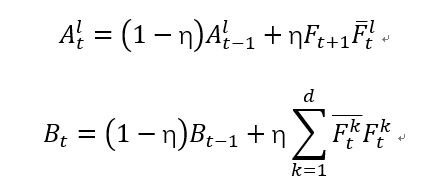
η是学习速率,t表示第几帧。加上划线表示共轭。我的理解,从第一帧时,分子和分母都没有前一项,很好得到初始分子分母。
算法流程:
输入:当前的图片;
上一帧的位置和尺度;
当前的位置模型和尺度模型;
位置更新:参照上一帧的位置,在当前帧提取2倍大小的样本,利用公式@,寻找令y最大的位置;
尺度更新:选择33种不同尺度的样本,利用位置滤波器得到的中心位置,结合公式@,对比寻找出最接近的尺度;
@
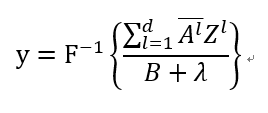
输出:目标的估计位置和尺度
更新位置模型和尺度模型;
程序中的关键点:
1、运行环境:matlab2017a,同时也需要高版本的opencv,对图片进行放大裁剪等处理;
2、数据集:OTB100,将图片集放置于sequences目录下,在run_tracker.m中调整第八行的输入位置,同时在load_video.m中正确匹配图片格式。在函数choose_video.m中,已经将图片地址整合完毕,ground_truth是人工标注的坐标和尺寸,frames文件里是图片的总数。
3、参数及其代表的意义:
位置滤波器输出差设定为1/16内;尺寸滤波器输出标准误差1/2内;调整参数(λ)0.01
跟踪器学习速率(η)为0.025;论文中的比例数(S)为33,和比例因子(a)为1.0;最大像素512。
4、初始化阶段:在dsst.m函数中:
初始化的作用目前的理解就是提取了第一帧的信息,建立输入和输出的滤波器模型。
已知初始目标框的为
再建立模型,一维和二维的高斯公式的形式,分别对应的是位置滤波器和尺寸滤波器
作者首先获取不同大小的分块,获取过程如下:
[rs, cs] = ndgrid((1:sz(1)) - floor(sz(1)/2), (1:sz(2)) - floor(sz(2)/2));
y = exp(-0.5 *(((rs.^2 + cs.^2) / output_sigma^2)));
和
ss = (1:nScales) - ceil(nScales/2);
ys = exp(-0.5 *(ss.^2) / scale_sigma^2);
5、提取特征的函数:
get_translation_simple.m中获得用于计算最佳位置时,所需的图片的HOG特征,以及get_scale_sample.m中可以获得求解最佳比例时的图片的特征,分成33个部分的HOG特征。两个函数提取的HOG特征是不一样的。
6、求解最佳位置,更新位置滤波器;
%得到的是样本的HOG特征图,并且用hann窗口减少图像边缘频率对FFT变换的影响,之后用快速傅里叶变换。
xt = get_translation_sample(im, pos, sz,currentScaleFactor, cos_window);
xtf = fft2(xt);
%这里是找到新到位置response就是公式里的y,用find函数找坐标里能使y最大的值。
response = real(ifft2(sum(hf_num .* xtf, 3)./ (hf_den + lambda)));
[row, col] = find(response == max(response( : )),1);
% 更新位置可以得到坐标和尺寸,更新位置
pos = pos + round((-sz/2 + [row, col]) *currentScaleFactor);
positions(frame,:) = [pos target_sz];
在提取位置特征的时候,先将输入图片Im的尺寸整合成固定值,然后选取一个二倍于跟踪框的图片,一共提取了32个sz(1)*sz(2)大小的hog特征,在用先前生成的cos_window与这32个特征图分别进行点乘操作,这样做的目的是为了减少图像边缘对FFT变换的影响。xt就是经过加窗处理后的hog特征图。其一共有28个hog特征。
7、求解最佳尺度,更新尺度滤波器的参数;
%提取样本的HOG特征
xs=get_scale_sample(im, pos,
base_target_sz, currentScaleFactor * scaleFactors, scale_window,scale_model_sz);
% 傅里叶变换
xsf = fft(xs,[ ],2);
scale_response = real(ifft(sum(sf_num .*xsf, 1) ./ (sf_den + lambda)));
% 同理,用find函数寻找可以使,滤波器最佳的比例值
recovered_scale = find(scale_response == max(scale_response( : )), 1);
%更新比例因子
currentScaleFactor = currentScaleFactor *scaleFactors(recovered_scale);
if currentScaleFactor < min_scale_factor
currentScaleFactor = min_scale_factor;
elseif currentScaleFactor > max_scale_factor
currentScaleFactor = max_scale_factor;
end
每个样本都要重新调整尺寸,分别提取31维fhog特征,每个样本的所有fhog再
串联成一个特征向量构成33层金字塔特征,乘以一维hann窗后作为输入F
用于尺寸相关滤波器。
8、更新模型:
% 位置滤波器
xl=get_translation_sample(im, pos, sz,
currentScaleFactor, cos_window);
xlf = fft2(xl);
new_hf_num = bsxfun(@times, yf, conj(xlf));
new_hf_den = sum(xlf .* conj(xlf), 3);
%尺度滤波器
xs=get_scale_sample(im,pos,base_target_sz,currentScaleFactor*scaleFactors,
scale_window, scale_model_sz);
xsf = fft(xs,[ ],2);
new_sf_num = bsxfun(@times, ysf, conj(xsf));
new_sf_den = sum(xsf .* conj(xsf), 1);
if frame == 1
hf_den = new_hf_den;
hf_num= new_hf_num;
sf_den = new_sf_den;
sf_num= new_sf_num;
else
hf_den= (1 - learning_rate) * hf_den + learning_rate * new_hf_den;
hf_num= (1 - learning_rate) * hf_num + learning_rate * new_hf_num;
sf_den= (1 - learning_rate) * sf_den + learning_rate * new_sf_den;
sf_num= (1 - learning_rate) * sf_num + learning_rate * new_sf_num;
end
对应公式里的就是,hf_den就是位置滤波器中的分子A,hf_num就是位置滤波器中的分母B,sf_den就是尺寸滤波器中的分子A,sf_num就是尺寸滤波器中的分母B。考虑到第一帧的图片没有公式里的前一项,所以分子hf_den = new_hf_den,但是求的是第一帧之后的,则需要先计算公式里后一项的那一长串的结果,存储在new_hf_den中,对应其他分子分母,这就是对应公式的理解。
9、关于使用HOG特征
本文只使用了这一种特征,借鉴了另一篇大佬的代码选择效果更好的分区域求HOG特征。来自:fhog.m函数,是由Felzenszwalb论文《Discriminatively trained deformable part models》里提取HOG的代码整合,主要函数是:GradientMag()和GradientHist(),由C++编写。计算出的HOG特征为3*nOrients+5维。文章选取得是2+2+4+1个通道,nOrients=9因此每个单元上是32维特征向量。这种取HOG特征的方法,即为fhog,已被证明实现了优于原始性能。输入图片得色彩灰度数组和切割框的参数,得到的是33个计算后的HOG特征。
HOG是一个局部特征,如果对一大幅图片直接提取特征,是得不到好的效果,所以把图像分割成很多区块,然后对每个区块计算HOG特征,这也包含了几何(位置)特性。
2)提取当前尺寸和位置的特征图谱;
10、使用hann窗是在FFT中为了降低图像边缘的影响,而引入的。
cos_window = single(hann(sz(1)) * hann(sz(2))’);
这里需要使用的是一个2维的窗函数;hann(x)表示窗分为多少个精度。
11、绘制跟踪框,之后用已经经过人工标注的每一帧数据作比较,再计算跟踪时的fps重叠率和误差率。(当年人工标记测试序列的时候还真是个体力活,不过有了测试序列之后,做算法的比较确实是一大进步)
Dsst.m函数内 %visualization
之后的部分。
自己的总结:DSST尺度滤波器的应用对于解决目标跟踪中的尺度变化很有帮助。同时期有个更早的相关滤波算法SAMF,在之后几年的比赛中互有胜负,都是对于尺度变换有良好解决的算法,结合资料,SAMF只有7个尺度比较粗犷,而DSST有33个尺度比较精细准确,并且DSST先检测平移再检测尺度,是分步最优,而SAMF是平移尺度一起检测,是平移和尺度同时最优,另外就是使用滤波器的数量不同,计算次数也差的很多,所以是一起效果好还是分开效果好再叠加好,我想再去了解一下。。其实算法理解了还是容易的,还有就是模型怎么建立的就让我觉得很神奇了。
补充的想法:
1、遇到目标脱离边界的情况,有没有比较好的表现?
2、除了HOG特征,使用别的数据作为跟踪的特征有没有更好的表现?
3、现在学习的跟踪用的视频清晰度都太低了,个人认为实用价值有限,毕竟如果要做会议室或者无人驾驶,还是要解析高清晰度的,不过低清晰度的视频有个好处就是,计算速度会比较快,实际使用时,会不会是两种清晰度的相互结合使用呢。
4、在机器学习应用到跟踪领域之前,目标跟踪的问题,就像是一个数学矩阵找另外一个数学矩阵中重叠部分最多的数学题,接下来这个阶段应该会再多看看不同的算法总结一些比较有价值的。
本文学习于
https://blog.csdn.net/autocyz/article/details/48651013
https://blog.csdn.net/weixin_38128100/article/details/80557460
https://blog.csdn.net/autocyz/article/details/48651013
最后
以上就是尊敬钢笔最近收集整理的关于Accurate Scale Estimation for Robust Visual Tracking 学习笔记:的全部内容,更多相关Accurate内容请搜索靠谱客的其他文章。








发表评论 取消回复