文章目录
- 系统整体结构
- 用户故事
- 诉求分析
- 诉求1
- 诉求2
- 诉求3
- 诉求4
- 诉求实现要点理解之关键概念
- 整体数据抽象
- 云端“图书馆”
- 云端“图书馆”的扩展功能之触发器
- 云端“图书馆”的扩张
- 诉求实现要点理解之平台化
系统整体结构
本小节主要讲解远程运维系统的典型作用和整体结构。
用户故事
A公司是一家做螺栓连接技术的公司,他们生产的螺栓被用到机械设备上。这些螺栓的作用是加固这些设备,保证机械的稳固性。
这些螺栓被用在大型设备上,可想而知,必须保证这些设备的连接稳定,不然会发生松动,造成意外事故。但是如何监测螺栓的松紧程度?如何在安装螺栓的时候将其拧紧到一个合适的程度?等等这些都是问题。
所以客户N年前找人开发了监测系统:即由一个采集器搭配四个压力传感器,通过将四个压力传感器分别放在需要螺栓固定的设备连接处,来监测螺栓的拧紧程度。采集器定时去采集传感器的数据,并显示在自带的屏幕上。这样子,工作人员就可以实时查看采集器的数据,从而判断螺栓的拧紧程度。
到这里,你觉得这套系统具有什么优缺点呢?
优点包括不限于:简单,低成本。
缺点主要有下列几点:
(1) 必须到现场才能看到采集的数据
(2) 必须不断的主动查看采集的数据,从而判断是否松动
(3) 由于第二点导致无法及时收到松动消息
(4) 人工成本高
(5) 无法统计从螺栓安装好后,一直到出现松动这一时间段内的螺栓拧紧程度的数据变化趋势。所以很难针对性的去提升螺栓品质。
(6) ….
客户使用了一段时间后,也发现如果继续沿用这套系统,那么上述问题无法解决,会持续痛苦下去。那么如何解决客户这个痛点呢?
通过对比原始系统,其实核心诉求可以归纳为以下几个核心点:
(1) 不需要去现场即可看到数据,即无人值守式工作
(2) 可以远程通过浏览器、APP等看到设备实时数据
(3) 能够看到历史数据曲线
(4) 能够被动接收推送消息,从而无需轮询即可及时得知螺栓松动情况。
其他诉求实际都属于附加诉求。
那么如何实现这些诉求呢?
诉求分析
诉求1
需要采集器能够把传感器数据传到云端,而不是简单的显示在屏幕上。在不改变采集器硬件的情况下,只能通过现有的采集器硬件接口去对接新的传输设备。示意图如图1.1所示:
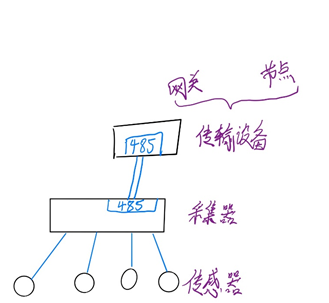
图1.1 采集示意图
传输设备的作用就是将设备数据最终传输到云端。其中,网关和节点均可以作为传输设备。二者的最大区别在于网关能够连接外网即广意上的互联网,而节点只能和网关配合组成局域网,他们的通信都是通过无线通信的,这里用虚线表示。网络的分层结构如示意图1.2所示:
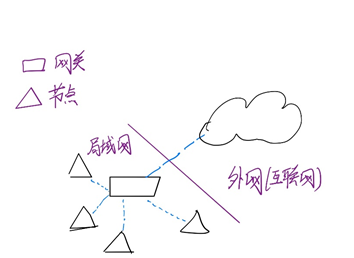
图1.2 网络示意图
整体采集与传输层面的示意图如图1.3所示:
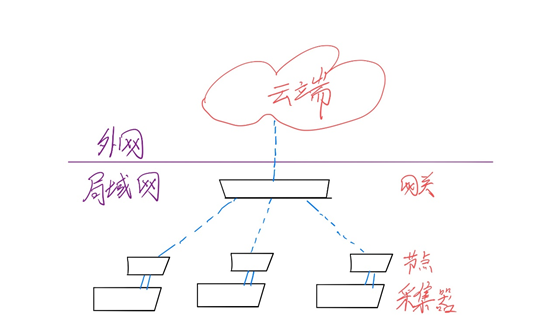
图1.3 采集传输整体示意图
图1.3中忽略了采集器所接的传感器。节点负责将各个采集器数据发送到中央的网关,再由网关上报到云端,这样数据最终就可以存储到云端。
有了底层这样的采集与通信结构以后,才可以实现将设备数据发布到云端,诉求1就有了实现的依据。
诉求2
需要开发web网页、APP等应用。这些应用从云端获取设备采集到的实时数据并展示在页面上即可。
诉求3
需要云端能够保存设备采集到的所有数据,便于查询历史数据。当然,应用也需要具备查询并显示历史数据的功能。
诉求4
需要云端能够建立推送机制,即当检测到某个螺栓传感器的数据符合触发条件时,比如传感器2上报的数值大于50时能够自动通知到用户。
这样子,当数据符合推送条件时,用户即可收到消息通知,比如收到报警短信,从而得知某个螺栓的松动情况。
诉求实现要点理解之关键概念
整体数据抽象
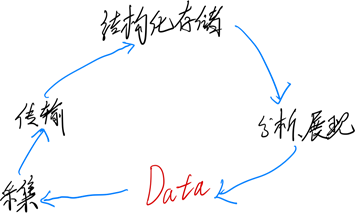
图1.4 数据抽象
图1.4可以看出,整体链路是围绕数据打通的。原始数据被采集到出来,然后经过传输层,在云端进行存储,最终数据还是回馈客户,被分析或者汇总等展现给客户。
从这个数据抽象层面来看,图1.3中局域网内的采集层和传输层就不必考虑其技术细节,只要知道数据通过底层硬件设备采集并传输到了云端即可。
二手书店和图书馆的区别之一是图书馆分门别类,不同的楼层不同的房间放的是不同类书籍,同一间房间还用书架来细分。所有图书遵循一套编号法则,每一本图书都有自己的唯一编号。而二手书店就不一样了,一堆书籍杂乱无序的堆放,从里面找本书费时费力。
如果把书籍看作是数据,那么云端的存储就不能向二手书店学习,而要向图书馆看起,所以图1.4将云端的存储标记为结构化存储(此结构化非数据库的名词概念)。
下面,我们将数据当作书籍,来建立自己的图书馆。
云端“图书馆”
现在云端图书馆开张了,但是面对这么多杂乱的底层上报的数据,我们只好向杭电图书馆的先进管理方式看齐。
我们首先定义每个数据的“唯一编号”。因为和云端直接交互的是网关类设备,而至于网关底下接了什么设备等等一切我们不考虑,这也是分层解耦思想和单一职责原则的体现。所以,针对不同的网关,我们对其定义唯一的ID,这里定义为deviceId,这样就可以区分哪些数据是由哪个网关上传的了。
但是,一个网关下可以采集多种数据,比如采集压力,湿度,或者采集四个地方的温度信息,然后上报时这些数据在云端如何区分?
比如压力,随着时间的流逝,压力这种数据给我们呈现的是一条“数据流”,就像无数水滴汇聚成的河流一样。只不过河流是流经大地,而数据是流过时间。
再次抽象一点,即网关下挂了好多这样的“数据流”,随着时间的流逝,站在我们云端图书馆的视角来看,一个网关下的数据区分就是按照数据流来区分的。所以需要我们为数据流制定唯一ID,我们将其命名为:streamId,stream即水流的意思,streamId高端大气上档次。
至此,通过deviceId + streamId就唯一定位到了一个数据流,再配合上时间这个参考坐标,我们云端图书馆的一个数据(点)的唯一编号就是:deviceId + streamId + timestamp。
云端“图书馆”的扩展功能之触发器
本图书馆了解到,有些客户想要制定触发功能,即通过监控某一个数据流中的实时最新数据,当数据符合条件时进行触发逻辑,去通知客户当前的情况。
经过不懈努力,我们创造了“触发器”这个系统。客户只需要简单配置,告诉我们他想监控哪个数据流(即deviceId + streamId),并且当数据值符合什么条件(比如大于、小于)时通知他,通知地址可以是邮箱或者客户通讯地址。
这样就配置好了一个触发规则。由于非常好用,好多客户都制定了许多规则,这些规则太难管理了,所以我们又要对其进行编号,编码方式从1开始递增即可。编码名字就叫“ruleId”,不过这样容易混淆,索性叫“triggerId”好了,trigger是触发的意思。
云端“图书馆”的扩张
由于具备这么多好用的功能和清晰的结构,接入的客户越来越多。那么有什么办法将各个客户的设备隔离开呢?
我们参考图书馆的房间分离方式,建立了“产品”这种概念。每个客户可以在本馆建立多种产品,每个产品下又包含了多个网关(设备)。通过这种分层,最终本馆的结构如下:
- 产品
- 设备(网关)
- 数据流
- 数据点
- 触发器
- 数据流
- 设备(网关)
因为触发器最终是关联到某个(些)数据流上面的,所以和数据流属于平级。
基于这种分层方式,很好的实现了大量设备及数据的接入及管理。
诉求实现要点理解之平台化
谁都想做平台,比如微信要构建自己的生态、平台。本图书馆也想构建自己的平台,平台意味着不仅能够让设备接入进来,数据上报上来,也同样意味着需要开发者或者相关企业的入住,能够在本平台上进行开发。
基于这个考虑,本馆对外暴露了一些开放的API接口,并且提供了相关的demo及SDK包供大家使用。同时提供了简易的设备之类的管理界面,客户可以查看自己在平台上的设备、数据等信息。
总之,本平台的宗旨就是:让客户更加方便地开发物联网应用,专注于应用层的处理,而不用考虑网关如何接入、数据如何存储、如何触发等复杂问题。
平台化以后,本平台运行良好,我们起了一个响亮的名字:OneNET平台。
由于这两年物联网发展迅速,各个传统企业都想结合物联网进行转型,各大公司也都开始眼红物联网平台的巨大潜在价值。最终,中国移动把我们这个平台收购了,所以我们最新的名字叫做—“中国移动OneNET物联网平台”!
注:以上图书馆故事纯属虚构。
再注:
OneNET平台地址
最后
以上就是忧伤月光最近收集整理的关于OneNET概述:以远程运维为例的全部内容,更多相关OneNET概述内容请搜索靠谱客的其他文章。








发表评论 取消回复