上一篇写到pipeline的实现,但是在存在大规模流水线电路中很容易出现长路径时序问题。所以需要对时序进行优化。
https://blog.csdn.net/loading_up/article/details/116722760?spm=1001.2014.3001.5501
握手信号中的优化时序方式:
1. 对vld和data进行打拍寄存一级,且ready实现无气泡传输。
与上一篇的区别在于控制信号的产生逻辑上:
//control path
always@(posedge clk)
begin
if (!rst_n)
begin
vld_s0 = 0;
vld_s1 = 0;
vld_o0 = 0;
vld_o1 = 0;
vld_s2 = 0;
end
else if (vld_in)
begin
vld_s0 = vld_in;
vld_o0 <= en0 ? vld_s0 : vld_o0;
vld_s1 = vld_in;
vld_o1 <= en1 ? vld_s1 : vld_o1;
vld_s2 = (vld_o0 & vld_o1) ? vld_in: vld_s2;
vld_o2 <= en2 ? vld_s2 : vld_o2; // vld寄存一拍,判定条件可直接简化成rdy_s2
end
end
wire en0,en1,en2,rdy_o0,rdy_o1;
assign rdy_o0 = rdy_s0 || ~vld_o0 ; // TO the pre level
assign rdy_o1 = rdy_s1 || ~vld_o1 ; //no campping
assign rdy_o2 = rdy_s2 || ~vld_o2 ;
assign en0 = vld_s0 & rdy_o0;
assign en1 = vld_s1 & rdy_o1;
assign en2 = vld_s2 & rdy_o2;
assign rdy_s0 = rdy_o2 ;
assign rdy_s1 = rdy_o2 ; //from the post level2. 对ready信号优化:不能采用打拍的形式,否则不满足两组输入输出握手信号的同步。 采用一个类似深度为1的FIFO来实现:
`timescale 1ns / 1ps
module PIPELINE_ADDER#(
parameter DATA_WIDTH = 4
)
(
input clk,
input rst_n,
input [DATA_WIDTH-1:0] a_in ,
input [DATA_WIDTH-1:0] b_in,
input [DATA_WIDTH-1:0] c_in ,
input [DATA_WIDTH-1:0] d_in ,
input vld_in,
input rdy_s2,
output reg [DATA_WIDTH-1:0] s_out,s0_r,s1_r,
output rdy_o2
);
wire [DATA_WIDTH-1:0] s0,s1,s2;
//reg [DATA_WIDTH-1:0] s0_r,s1_r;
wire vld_s1; //vld_in
wire vld_o1,rdy_s1; //vld_out
wire vld_o0,vld_o2; //vld_out
wire vld_s0,vld_s2; //vld_out
wire rdy_s0; //need back pressure
wire en0,en1,en2,rdy_o0,rdy_o1;
// assign en0 = vld_s0 & rdy_o0;
// assign en1 = vld_s1 & rdy_o1;
// assign en2 = vld_s2 & rdy_o2;
//control path
//buffer 1 depth
wire [3:0]buf_dout,buf_dout1,buf_dout2;
buffer b0(.clk(clk),.rst_n(rst_n),.vld_s(vld_s0),.din(s0),.rdy_o(rdy_o0),.vld_o(vld_o0),.dout(buf_dout),.rdy_s(rdy_o1));
buffer b1(.clk(clk),.rst_n(rst_n),.vld_s(vld_s1),.din(s1),.rdy_o(rdy_o1),.vld_o(vld_o1),.dout(buf_dout1),.rdy_s(rdy_o2));
buffer b2(.clk(clk),.rst_n(rst_n),.vld_s(vld_s2),.din(s2),.rdy_o(rdy_o2),.vld_o(vld_o2),.dout(buf_dout2),.rdy_s(rdy_s2));
//data path
//the first level
//comb
assign s0 = a_in + b_in;
assign s1 = c_in + d_in;
assign s2 = s0_r + s1_r;
//data寄存器打拍
always@(posedge clk)
begin
if (!rst_n)
begin
s0_r <= 4'b0;
s1_r <= 4'b0;
end
else
begin
s0_r <= buf_dout ;
s1_r <= buf_dout1;
end
end
//the second level
always@(posedge clk)
begin
if (!rst_n)
s_out <= 4'b0;
else
s_out <= buf_dout2 ;
end
endmodule
module buffer(
input clk,rst_n,
input vld_s,
input [3:0]din,
output reg rdy_o,
output vld_o,
output [3:0]dout,
input rdy_s
);
reg buf_vld;
reg [3:0] buf_data;
wire store;
assign store = vld_s & rdy_o & ~rdy_s;
always@(posedge clk)
begin
if (!rst_n) buf_vld <= 0;
else buf_vld <= buf_vld ? ~rdy_s : store;//if buf_vld is 1, rdy_s0 must be 1, next state is 0,
end
always@(posedge clk)
begin
if (!rst_n) buf_data <= 0;
else buf_data <= store ? din : buf_data;
end
always@(posedge clk)
begin
if (!rst_n) rdy_o <= 0;
else rdy_o <= rdy_s || (~store && ~buf_vld) ;
end
assign vld_o = rdy_s ? vld_s : buf_vld;
assign dout = rdy_s ? din : buf_data;
endmodule
module tb_pipeline2();
wire [3:0]s_out,s0_r,s1_r;
wire rdy_o2;
reg clk,rst_n;
reg [3:0]a_in,b_in,c_in,d_in;
reg vld_in;
reg rdy_s2;
PIPELINE_ADDER pipe_adder(
.clk(clk),
.rst_n(rst_n),
.a_in(a_in),
.b_in(b_in),
.c_in(c_in),
.d_in(d_in),
.vld_in(vld_in),
.rdy_s2(rdy_s2),
.s_out(s_out),
.rdy_o2(rdy_o2),
.s0_r(s0_r),
.s1_r(s1_r)
);
initial begin
clk = 0;
forever #5 clk = ~clk;
end
initial begin
rst_n = 0;
repeat(10) @(posedge clk);
rst_n = 1'b1;
a_in = 4'b0001;
b_in = 4'b0100;
c_in = 4'b0010;
d_in = 4'b1000;
vld_in = 1'b1;
rdy_s2 = 1'b1;
#10;
rdy_s2 = 0;
#10;
rdy_s2 = 1 ;
#30;
a_in = 4'b0011;
b_in = 4'b0001;
c_in = 4'b0010;
d_in = 4'b0100;
#10;
a_in = 4'b0001;
b_in = 4'b0011;
c_in = 4'b0111;
d_in = 4'b0000;
repeat(10) @(posedge clk);
end
endmodule
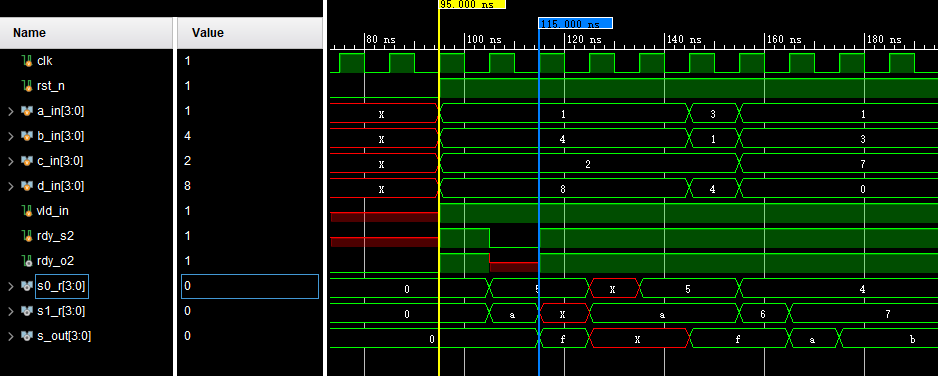
最后
以上就是光亮烧鹅最近收集整理的关于一种优化协议时序的pipeline的全部内容,更多相关一种优化协议时序内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复