一:综合策略
top-down & bottom-up
1:top-down
层次化结构,只对顶层设计进行全面约束,针对个别模块有特殊约束;比如管理模块(clock模块,reset模块等)的综合不会与工作模块(顶层模块)放在一起综合的。
2:bottom-up
对底层的各个模块定为current_design,进行综合,加上dont touch属性;若各层之间有group logic(如与门),还需要对group logic约束;这种风格的综合约束复杂且多。
所有top-dowm方式用得更多
3:综合里的关键字
边界优化, ungroup(模块被打散,只能看到顶层设计),扫描链(DFT)。。。。
二:compile_ultra的三级分类
虚拟机不支持,是对compile进行优化;
将模块全部打散,对于后端来说,全部打散不方便后续操作,只能看到各个与或非门,无法得到具体模块与模块之间的关系或者问题。
对关键路径优化,循环迭代优化。目标是满足时序要求的同时保证面积最小。
分为三个阶段的优化:
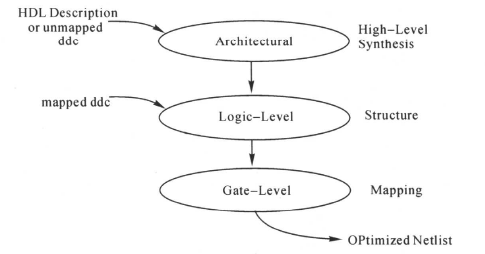
主要包括:第一阶段的结构级的优化(Architectural-Level Optimization)、第二阶段的逻辑级优化(Logic-Level Optimization)、最后阶段的门级优化(Gate-Level Optimization)。
1:结构级优化(archiiture-level)
结构级优化包括的内容如下:

包括:设计结构的优化,数据通路的优化,共享共同的子表达式,资源共享,重新排序运算符号(详见http://www.cnblogs.com/IClearner/p/6636176.html)
例如:加法器有普通加法器,超前进位加法器,DC会根据应用场合挑选出合适的加法器。
2:逻辑级优化(logic-level)
一个逻辑表达式可以是与非格式,也可以是或非格式,DC会选择合适的逻辑表达式来描述逻辑功能。
逻辑优化的内容如下:

做完结构的优化后,电路的功能以GTECH的器件来表示。在逻辑级优化的过程中,可以作结构(Structuring)优化和展(开)平(Flattening)优化。
3:门级优化(Gate-level)
得到网表后的优化,局部优化。
三:其他知识点
1:re-synthesis
网表文件生成后,静态时序分析时,DC工具对路径进行分析,对关键路径进行优化,逻辑级优化与门级优化可以迭代使用(若路径延时过大,不满足设计规则,DC会resynthesis,一直到路径延迟满足要求)。
2:DesignWare Library
IP库,包含算术操作,标准IP;优点在于设计更快更可靠;在使用compile_ultra会自动使用该库。
3:综合最基本的要求是满足时序要求;
4:CSA算法优化数据通路的设计
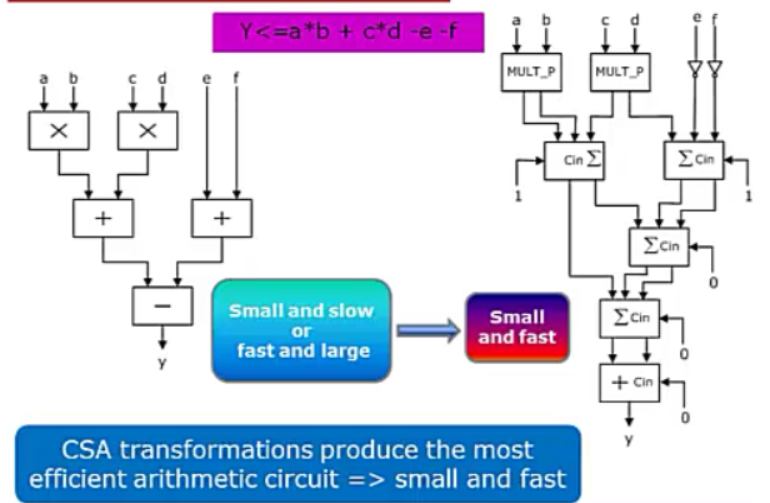
5:常见算术优化方法

尤其是第五条,乘法运算改为移位运算,减少资料占用。
6:逻辑复制(logic duplication)
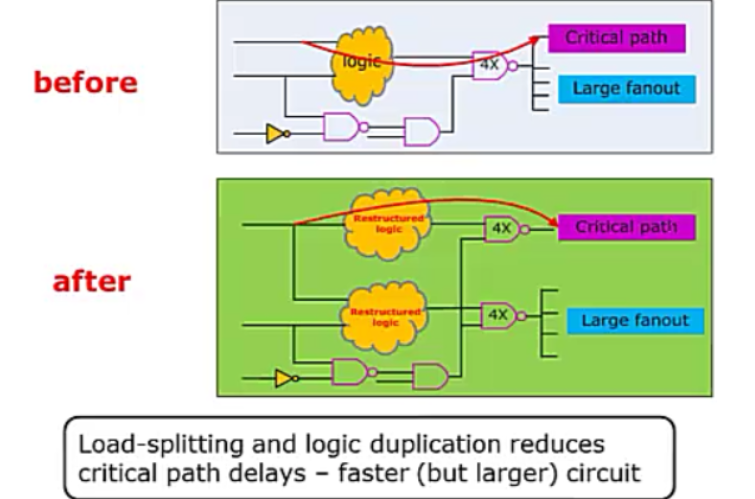
对关键路径部分的负载放在其他路径上,减少关键路径延时,以面积换速度。
7:库分析
一个逻辑表达式可由不同的表达方式表达,DC挑选出合适的库单元实现逻辑。
三:其他有关命令的时序优化及方法
DC综合之后,我们查看详细的报告,如果没有违规,设计既能满足时间和面积的要求又不违犯设计规则,那么综合完成。可以把门级网表和设计约束等交给后端(backend)工具做布局(placement )、时钟树综合(clock tree synthesis)和布线(route)等工作,产生GDSII文件。如果设计不能满足时间和面积的要求或违犯设计规则等,就要分析问题所在,判断问题的大小,然后采取适当的措施解决问题。问题往往是时序的问题,发生时序违规时可以采取相应的措施,如下图所示:
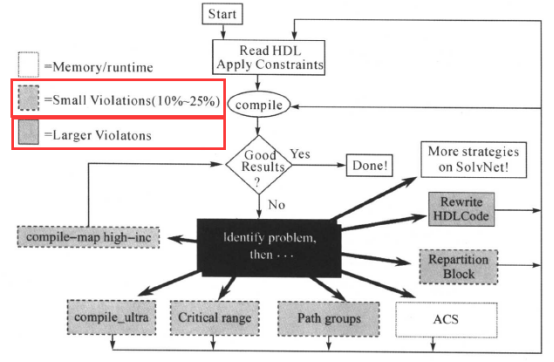
(1)当违规得比较严重时,也就是时序的违规(timing violation)在时钟周期的25%以上时,就需要重新修改RTL代码了。
(2)时序违规在25%以下,有下面的时序优化方法:
①使用compile_ultra命令(在拓扑模式下运行)
compile_ultra跟compile一样,是进行编译的命令。compile_ultra命令适用于时序要求比较严格,高性能的设计。使用该命令可以得到更好的延迟质量( delay QoR ),特别适用于高性能的算术电路优化。该命令非常容易使用,它自动设置所有所需的选项和变量。下面是这个命令的一些介绍:
compile_ultra命令包含了以时间为中心的优化算法,在编辑过程中使用的算法有:A以时间为驱动的高级优化(Timing driven high-level optimization);B为算术运算选择适当的宏单元结构;C从DesignWare库中选择最好的数据通路实现电路;D映射宽扇入(Wide-fanin)门以减少逻辑级数;E积极进取地使用逻辑复制进行负载隔离;F在关键路径自动取消层次划分(Auto-ungrouping of hierarchies)。
compile_ultra命令支持DFT流程,此外compile_ultra命令非常简单易用,它的开关选项有:
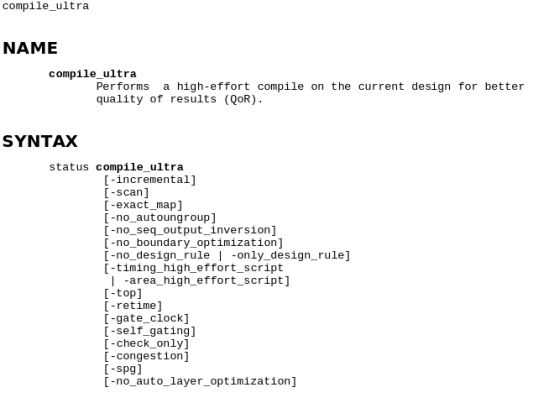
部分解释如下所示:
-scan :做可测试(DFT)编辑;
-no_autoungroup :关掉自动取消划分特性;
-no_boundary_optimization :不作边界优化;
-no_uniquify : 加速含多次例化模块的设计的运行时间
-area_high_effort_script : 面积优化
-timinq_high_effort_script : 时序优化
上面的开关部分说明如下所示:
**Boundary optimization边界优化
在编辑时,Design Compiler会对传输常数,没有连接的引脚和补码信息进行优化,也就是说边界优化会把边界引脚一些固定的电平,固定的逻辑进行优化。但是在formility(形式验证),需要告诉formility电路结构发生了改变。这个改变存放在DC的生成文件里。
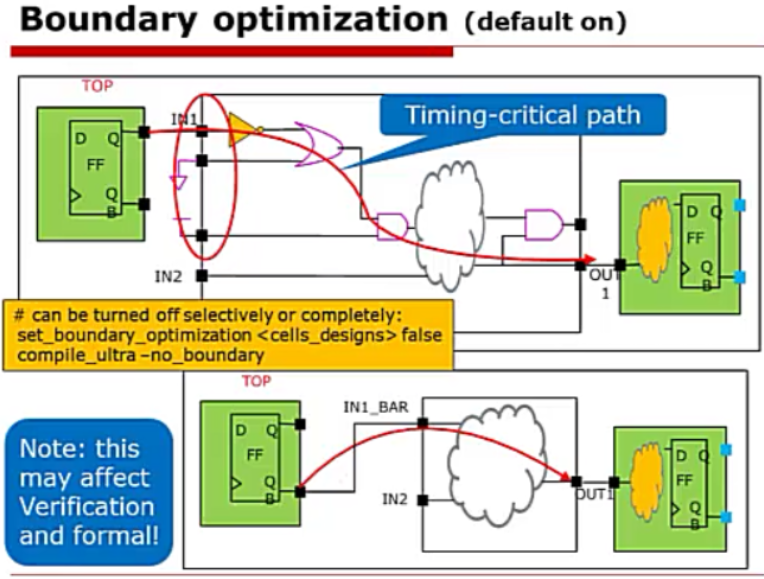
以下命令会禁止边界优化
set_boundary_optimization<cells_designs> false
compile_ultra -no_boundary
**Auto-ungrouping及其取消
compile默认不打散,compile_ultra会自动将模块打散,打散后只能看到top层和具体实现;
set_ungroup <reference_or_cells> false ;#禁止cell打散
set_app_var compile_ultra_ungroup_dw false ;#禁止打散,使用designware层次
set compile_ultre_ungroup_dw true ;#允许打散,取消desigware层次。也就是说,你你调用的一个加法器和一个乘法器,本来他们是以IP核的形式,或者说是以模块的形式进行综合的,但是设置了上面那么变量之后,综合后那个模块的界面就没有了,你不知道哪些门电路是加法器的,哪些是乘法器的。
compile_ultra -no autoungroup ;#全部都不打散
为了使设计的结果最优化,我们建议将compile_ultra命令和DesignWare library一起使用。也就是说不打散较好。
**scan扫描链
扫描链是在寄存器前加入选择器,在DFT时可能会有影响,如果想加入scan扫描链,在综合的时候必须评估扫描链寄存器的影响,即加入-scan命令。
scan寄存器只是换成mux选择器,并没有形成一个链。
在多级寄存器级联时,中间加入buffer或者反相器,只在第一级加入扫描链。
**-timing
compile_ultra -timing 关键路径上时序的优化,但如果时序余量较大,不适宜使用该命令,否则会使时序优化的优先级大于DRC(DRC,时序优化,面积优化)
寄存器复制
**Behavior Retiming(简称BRT技术)
对门级网表的时序进行优化,也可以对寄存器的面积进行优化。BRT通过对门级网表进行管道传递(pipeline)(或者称之为流水线),使设计的传输量(throughput)更快。BRT有两个命令:
optimize_registers :适用于包含寄存器的门级网表(不是compile_ultra的开关选项)。
pipeline_design :适用于纯组合电路的门级网表。
对于寄存器的的优化,举例如下,对于下面的电路,既包含有组合逻辑电路又包含有寄存器:
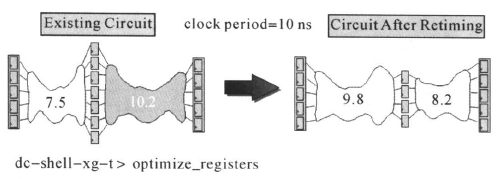
后级的寄存器与寄存器之间的时序路径延迟为10. 2 ns,而时钟周期为10 ns,因此,这条路径时序违规。但是前级的寄存器与寄存器之间的时序路径延迟为7. 5 ns,有时间的冗余。使用optimize_registers命令,可以将后级的部分组合逻辑移到前级,使所有的寄存器与寄存器之间的时序路径延迟都小于时钟周期,满足寄存器建立时间的要求。optimize_registers命令首先对时序做优化,然后对面积作优化。优化后,在模块的入/输出边界,电路的功能保持不变。该命令只对门级网表作优化。
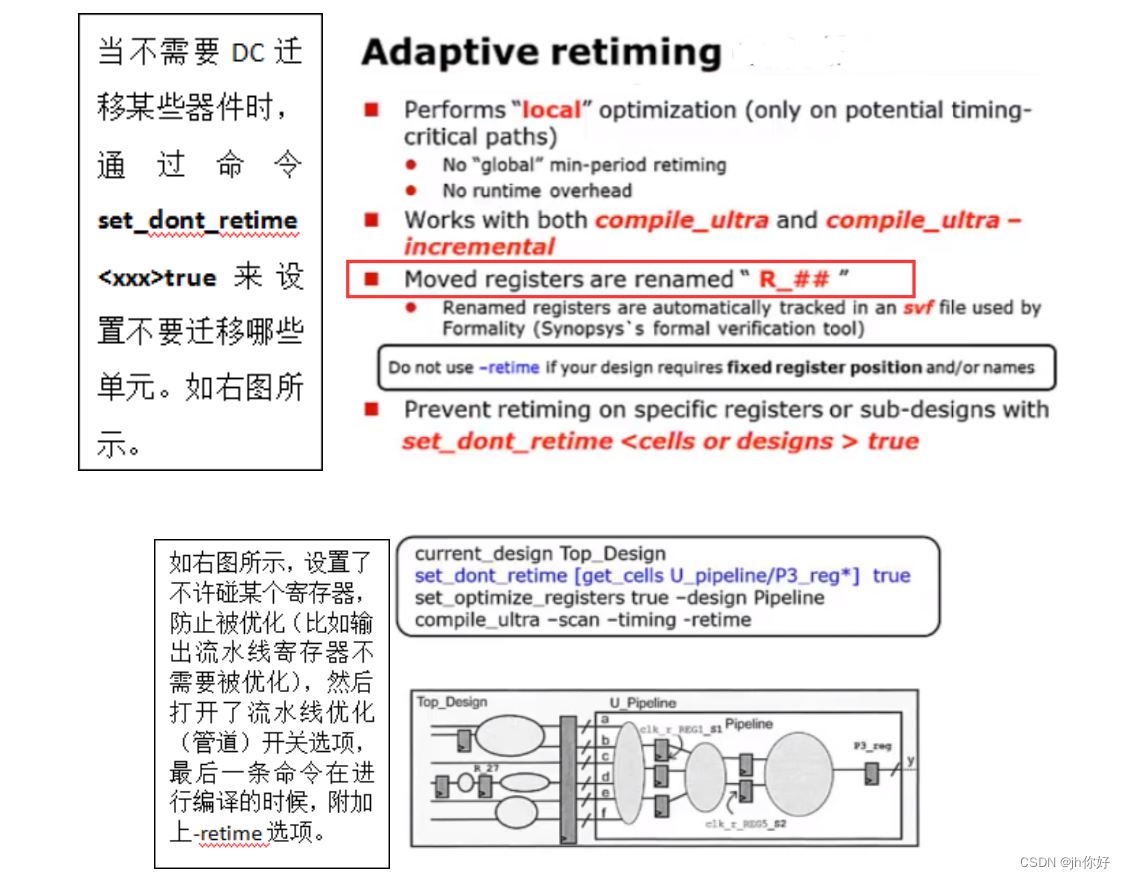
除了单独使用这个命令之外,还可以在编译的时候往往加上选项-retime(这个好像只有compile_ultra才有这个开关选项)。
-retime与optimize_registers区别:-retime针对一般逻辑,optimize_reggisters针对pipeline结构进行优化;两者可以同时使用。
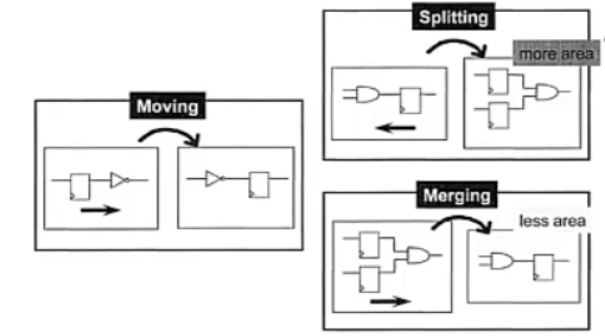
-retime选项的功能也就是:当有一个路径不满足,而相邻的路径满足要求时,DC会进行路径间的逻辑迁移,以同时满足两条路径的要求,这也叫adaptive retiming,如下图所示:
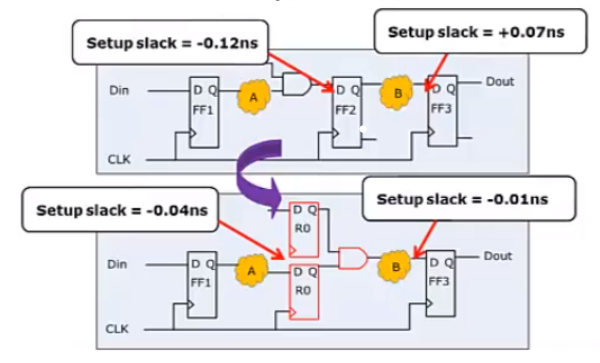
retime主要通过moving,spliting,merging来进行优化,如下图
当不需要DC迁移某器件时,例如寄存器输出,不希望改变,可使用set_dont_retime <cells or designs> true
对于纯组合逻辑的流水线(管道)优化,举例如下,对于纯组合逻辑电路进行优化如下所示:
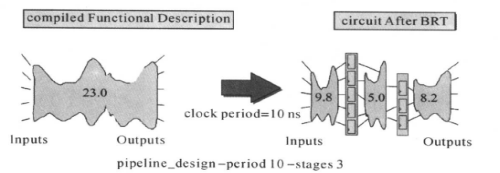
左边电路,是一个纯组合电路,它的路径延迟为23. 0 ns。对这个电路进行管道传递优化后,得到右边所示的电路。显然,电路的传输量(throughput)加快了。需要注意的是,在使用这个命令时,需要在RTL设计中把寄存器预置好,否则DC不知道这些寄存器是怎么来的。
**路径分组group_path
DC为了便于分析电路的时间,时序路径又被分组。路径按照控制它们终点的时钟进行分组。如果路径不被时钟控制,这些路径被归类于默认(Default)的路径组。我们可以用report_path_group命令来报告当前设计中的路径分组情况。
Design Compiler中,常用report_timing命令来报告设计的时序是否满足目标。执行report_timing命令时,DC做4个步骤:
·把设计分解成单独的时间组;
·每条路径计算两次延迟,一次起点为上升沿,另一次起点为下降沿;
·在每个路径组里找出关键路径(critical path),即延迟最大的路径;
·显示每个时间组的时间报告。
关于怎么阅读时序报告,我们后面进行介绍。
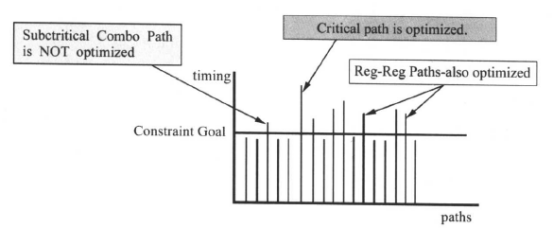
如果DC不进行专门的分组,只有默认(Default)的路径组,DC只对默认组的关键路径进行优化,当它不能为关键路径找到一个更好的优化解决方案时,综合过程就停止。DC不会对次关键路径(Sub-critical paths)作进一步的优化。因此,如果关键路径不能满足时序的要求,违反时间的约束,次关键路径也不会被优化,它们仅仅被映射到工艺库,如下图所示:
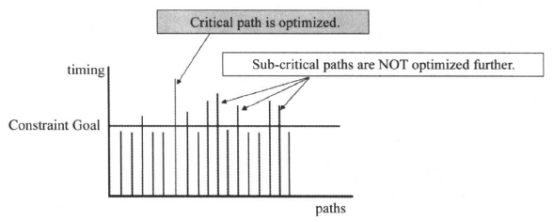
对于下面的电路,假设加设计约束后,所有的路径属于同样的时钟组,也就是只有一个路径组:
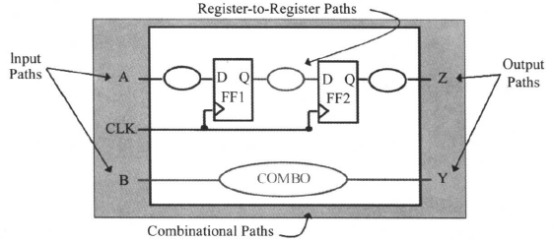
如果组合电路部分的优化不能满足时序要求,并且关键路径在组合电路里,根据DC的默认行为,组合电路中关键路径的优化将会阻碍了与它属于相同时钟组的寄存器和寄存器之间路径的优化。防止出现这种情况可用下面两种方法:自定义路径组和设置关键范围。
**多核优化:
report_host_options 显示有多少核
多核时:set_host_options -max_cores 4 ;#申请4个内核,系统不一定给4个核
compile -ultra
一般一个license只支持2个核,多个license支持多个核;
关掉多个核:remove_host_options
set_host_options -max_cores 1
四:group_path继续研究(自定义路径与设置关键范围)
1:自定义路径
综合时,工具只对一个路径组的最差(延时最长)的路径作独立的优化,但并不阻碍另外自定义路径组的路径优化。产生自定义路径组也可以帮助综合器在做时序分析时采用各自击破(divide-and-conquer)的策略,因为report_timing命令分别报告每个时序路径组的时序路径。这样可以帮助我们对设计的某个区域进行孤立,对优化作更多的控制,并分析出问题所在,如下图所示的:
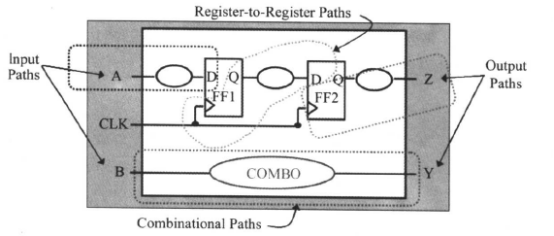
产生自定义路径组的命令如下所示:
#Avoid getting stuck on one path in the reg-reg group
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_outputs]
group_path -name COMBO -from [all_inputs] -to [all_outputs]
上面的命令产生三个自定义的路径组,加上原有的路径组,即寄存器到寄存器的路径组(因为受CLK控制,默认的是CLK的路径组),现在有4个路径组。组合电路的路径,属于“COMBO”组,由于该路径组的起点是输入端,在执行“group_path -name INPUTS -from [all_inputs]”命令后,命令中用了选项“-from [all_inputs]",它们原先属于“INPUTS”组。在执行“group_path -name OUTPUTS -to [all_outputs]”命令后,组合电路的路径不会被移到“OUTPUTS”组,因为开关选项‘'-from”的优先级高于选项”-to”,因此组合电路的路径还是留在“INPUTS”路径组。但是由于“group_path -name COMBO -from [all_inputs] -to [all-outputs]”命令中同时使用了开关选项“-from”和“-to" ,组合电路路径的起点和终点同时满足要求,因此它们最终归属于“COMBO”组。DC以这种方式工作来防止由于命令次序的改变而使结果不同。我们可以用report_path_group命令来得到设计中时序路径组的情况。
产生自定义的路径组后,路径优化如下图所示,此时,寄存器和寄存器之间的路径可以得到优化:
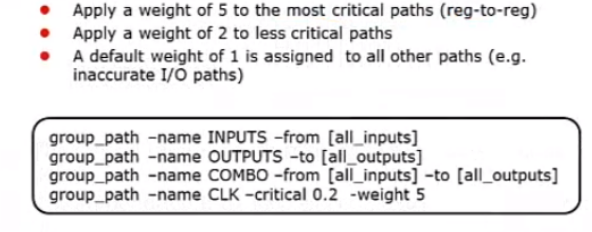
DC可以指定权重进行优化,当某些路径的时序比较差的时候,可以通过指定权重,着重优化该路径。权重最高5,其次是2,默认是1;因此最差的要设置5;如下图所示,下面的命令就是着重优化CLK这个路径组:-weight
2:设置关键范围
-critical_range:对路径优化的范围设置,每个组内在范围内的路径都会被优化
set_critical_range 2 [current_design]
使用上面的命令之后,DC会对在关键路径2ns的范围内的所有路径作优化,解决相关次关键路径的时序问题可能也可以帮助关键路径的优化。时序优化的示意图如下所示:
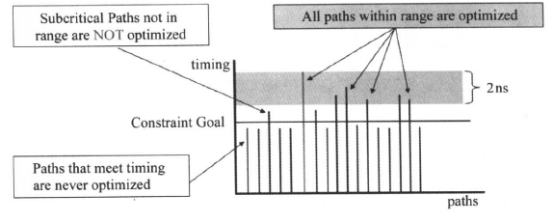
如果在执行set_critical_range命令后,优化时使关键路径时序变差,DC将不改进次关键路径的时序。我们建议关键范围的值不要超过关键路径总值的10%。
3: 自定义路径组+关键范围
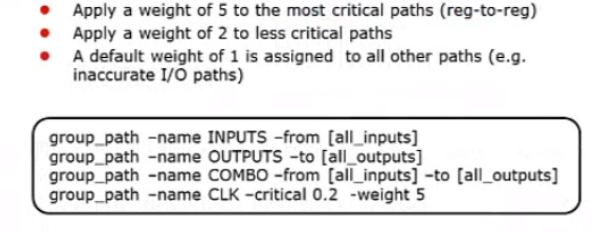
上图第四句对CLK组加强优化(weight=5),关键范围为0.2
4:自定义路径组与关键范围的区别
自定义路径组: 用户自定义路径组后,如果设计的总性能有改善,DC允许以牺牲一个路径组的路径时序(时序变差)为代价,而使另一个路径组的路径时序有改善。在设计中加入一个路径组可能会使时序最差的路径时序变得更差。
关键范围: 关键范围不允许因为改进次关键路径的时序而使同一个路径组的关键路径时序变得更差。如果设计中有多个路径组,我们只对其中的一个路径组设置了关键范围,而不是对整个设计中的所有路径组都设置了关键范围,DC只会并行地对几条路径优化,运行时间不会增加很多。
五:实战
1:打开DC
2:读入verilog代码检查等等
3:读入约束然后compile -map_effort high -area_effort high;最大compile,相当于compile ultra
**没有路径组约束时,
report_timing -delay_type max 检查最差路径
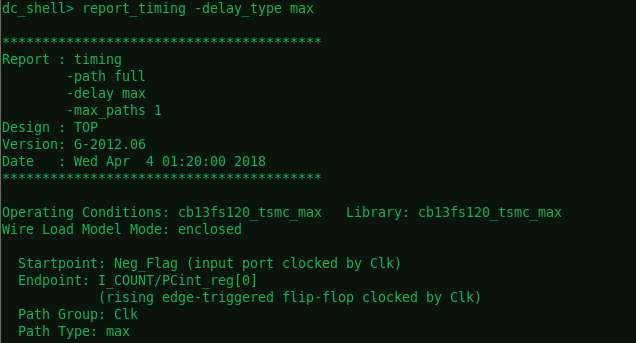
看到Path Group只有一条默认组Clk;report_path_group
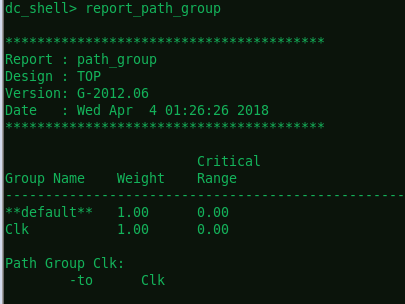
**加入路径组约束(简单加入)

再次source ./rtl/scripts/TOP.con
report_path_group会得到四条路径
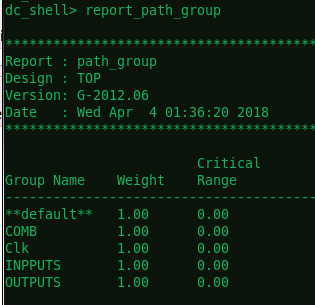
report_timing -delay_type max 检查最差路径
显示四条路径的各个最差路径。
下面链接里面有部分TCL约束实例
DC环境、设计规则和面积约束 - 腾讯云开发者社区-腾讯云 (tencent.com)
最后
以上就是火星上柠檬最近收集整理的关于DC学习综合与优化的全部内容,更多相关DC学习综合与优化内容请搜索靠谱客的其他文章。








发表评论 取消回复