这里写目录标题
- 一、工艺库
- 1.1工艺库声明
- 1.2工艺库K系数
- 1.3 线负载模型
- 1.4 工作条件定义
- 1.5 查找表延迟模型
- 1.6 单元定义
- 二、层次划分
- 2.1 寄存器吸收组合逻辑
- 2.2 寄存器输出划分边界
- 2.3 避免胶连逻辑
- 2.4 合适尺寸匹配速度
- 三、编码风格
- 3.1 锁存器与寄存器
- 3.2 多路选择器推断
- 3.3 if和case
- 3.4 仿真代码
- 3.5 for循环综合
- 3.6 算术运算综合
- 3.7其余可综合总结
DC逻辑综合是将RTL级代码转化为门级网表,此转化过程中受到哪些因素影响呢?分别是工艺库、层次划分、编码风格和编译指令。
一、工艺库
工艺库中包含了给综合待选的门级和连线单元,好的单元库是进行高水平ASIC设计的基础。绝大部分Synopsys 库的时序模型和布局布线的时序模型之间的存在着一对一的映射关系。对库格式以及延迟计算方法的基本理解是成功综合的关键。
设计者并不关心工艺库的全部细节,通常只需知道库中包含的名种单元以及单元的多种驱动强度即可。不过为了成功地优化设计,设计者就有必要了解DC采用的延时计算方法、线负载模型及单元描述等。因此,这里从应用的角度Synopsys 工艺库进行简单描述。
Synopsys 工艺库包括逻辑库和物理库。
物理库:包含单元的物理特征,如物理尺寸、层信息、单元方位等,这里仅讨论与综合相关的逻辑库。
逻辑库是扩展名为.lib的文本文件,通过 Synopsys 的Library Compiler 可以生成扩展名为.db的二进制文件,其内容包括单元面积、 引脚时序、 引脚类型、 功耗、 负载大小、 驱动能力 等与DC 工作相关的各类信息。
1.1工艺库声明
下面时一个工艺库的定义实例:
library( smic18_tt) { /*start of library*/
delay_model : table_lookup ;
in_place_swap_mode : match_footprint ;
time_unit : "1ns" ;
voltage_unit : "1V" ;
current_unit : "1uA" ;
pulling_resistance_unit : "1kohm" ;
leakage_power_unit : "1nW" ;
capacitive_load_unit ( 1,pf ) ;
nom_process : 1 ;
nom_voltage : 1.8 ;
nom_temperature : 25 ;
revision : 2.1 ;
date : "Thu Jul 24 17:21:41 CST 2003" ;
comment : "Copyright 2003 by Verisilicon Microelectonics (Shanghai) Co.,Ltd." ;
} /*end of library*/
库声明部分中关键字library后“( )”内指定了工艺库的名称,本示例采用的工艺库为 smic18_tt , 之后的**“{ }”内是工艺库的详细定义**。“{ }”内的第一部分定义了库的基本属性,如延迟模型、在位替换模式、时间/电压/电0流/电容/漏电功耗/上拉电阻等的单位、以及版本、日期等信息。
1.2工艺库K系数
K系数定义、缩放因子,提供了基于PVT(即工艺、电压温度)的偏差计算延迟值的修正方法。例如:
k_temp_hold_fall : 0.001498 ;
k_temp_hold_rise : 0.001107 ;
k_volt_hold_fall : -0.455566 ;
k_volt_hold_rise : -0.459735 ;
k_temp_setup_fall : 0.001498 ;
1.3 线负载模型
线负载模型 wire_load 用于在设计的布图前阶段估计互连线的延迟,包含了互连线长度和扇出对互连线电阻、电容和面积的影响等信息。库实例中的resistance、capacitance area 分别代表了单位长度互连线的电阻、电容和面积。fanout_Jength 指定了与扇出数目相关的互连线长度;对于超出fanout_length 指定的连线,则根据斜率slope通过对已有的fanout_length进行插值确定其长度。
工艺库中通常包括针对不同设计规模的线负载模型,即线负载模型依估计的 die 的大小确定,如 arca zero、reference_area_20000、referenee_area_100000等,默认情况下 DC 会根据设计规模选择稍微悲观的线负载模型,以为布图后阶段提供额外的时序裕度。
由于分层设计中可能使用不同的线负载模型,对于跨越层次的互连线,DC支持3种负载模型的选择模式:top、enclosed、segmented。
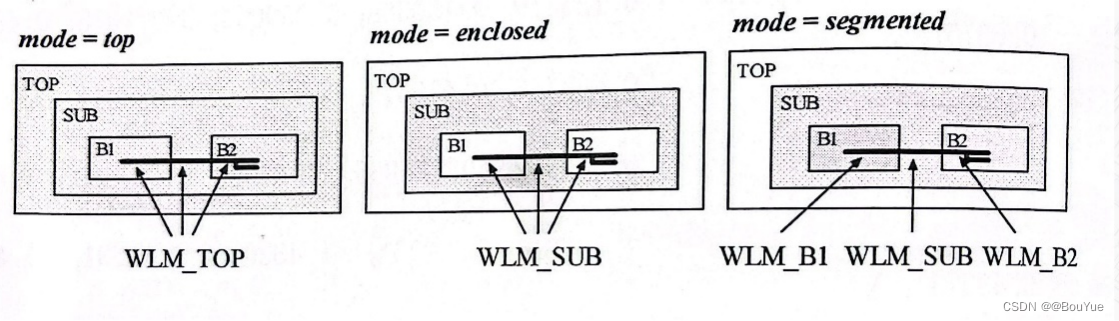 层模式(top):所有层次子模块的wire_load和top_level相同;
层模式(top):所有层次子模块的wire_load和top_level相同;
包含模式(enclosed):子模块互连线的wire_load和en_close它的最小模块相同;
分段模式(segmented):子模块间互连线的wire_ load 和enclose 该互连线模块相同。
以下是一个线负载模型示例:
wire_load ( "reference_area_1000000" ) {
resistance : 0.00038 ;
capacitance : 0.00025 ;
slope : 42.1286 ;
fanout_length ( 1,27.619 ) ;
fanout_length ( 2,56.6667 ) ;
……
fanout_length ( 19,710.476 ) ;
fanout_length ( 20,752.381 ) ;}
1.4 工作条件定义
PVT(即工艺、电压、温度)的变化都会对电路的性能产生影响,因此综合应该尽可能模拟电路实际情况。工作条件(operating condions)通常描达为 WORST、 TYPICAL、BEST等三种情况,通过改变工作条件覆盖工艺偏差的整个范围。
WORST工作条件用于最大化建立时间,BEST工作条件用于分析保持时间,由于WORST和BEST情况包括了 TYPICAL 情况,所以通常情况下在综合阶段可忽略TYPICAL的情况。以下是一个YTPICAL工作条件的示例:
operating_conditions ( typical ) {
process : 1 ;
voltage : 1.8 ;
temperature : 25 ;
1.5 查找表延迟模型
DC使用工艺库中提供的时序参数和环境属性进行延迟计算,而时序参数和环境属性与计算延迟时采用的延迟模型有关。常见的延迟模型有:CMOS通用延迟模型、CMOS 非线性延迟模型、可扩展多项式延迟模型、CMOS 分段线性延迟模型、延迟计算模块 (DCM)延迟模型。目前ASIC 业界采用的主流延迟模型为 CMOS 非线性延迟模型,即查找表延迟模型。上述工艺库采用的就是查找表模型,库声明的第一句“delay_ model:table_ lookup:”即己表明。
非线性延迟模型采用查找表和插值方法计算延时,对深亚微米设计可以提供足够精度的延时信息。延迟分析包括计算一个逻辑级,即从一个逻辑门的输入到下一个相邻逻辑门的输入之问的延时,通常划分为单元延时和互连延时,即Dtotal=Dcall + Dc。单元延时通常定义为从输入引脚电平的 50%到输出引脚电平的50%之间的延时,通常是揄出负载和输入转换时间的函数;互连延时指从驱动单元输出引脚电平转换到下一级逻辑门输入引脚电平变化所经历的时间,也称为time-of-flight delay。举例:
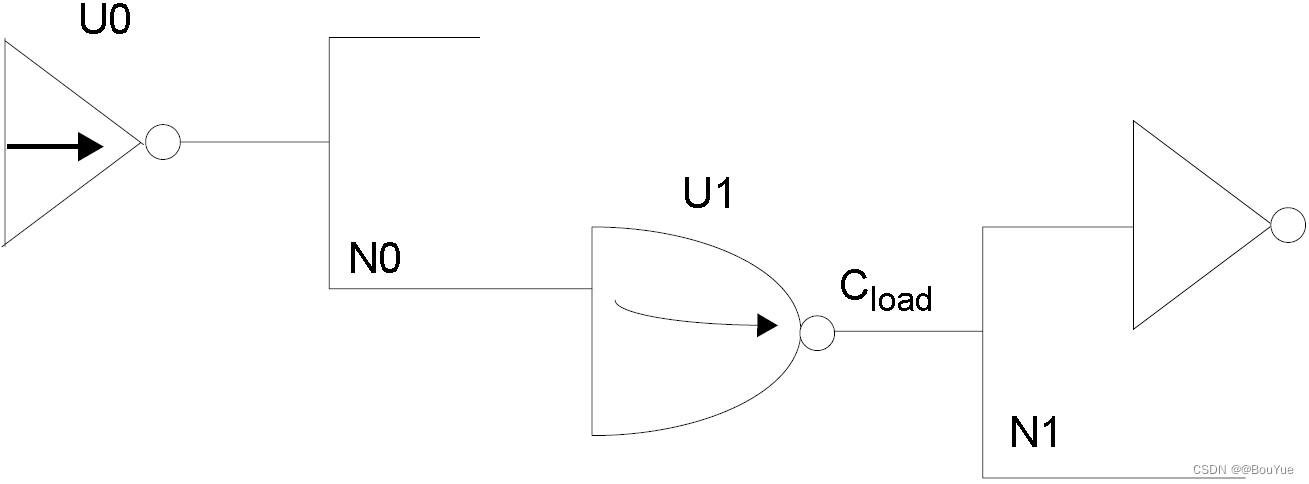
根据z=A+Bx+Cy+Dxy可计算四个系数A、B、C、D:
0.227 = A + B · 0.098 + C · 0.03 + D · 0.098 · 0.03
0.234 = A + B · 0.098 + C · 0.06 + D · 0.098 · 0.06
0.323 = A + B · 0.587 + C · 0.03 + D · 0.587 · 0.03
0.329 = A + B · 0.587 + C · 0.06 + D · 0.587 · 0.06
A=0.2006,B=0.1983,C=0.2399,D=0.0677,因此U1的单元延时为:
0.2006 + 0.1983 · 0.32 + 0.2399 · 0.05 + 0.0677 · 0.32 · 0.05 = 0.275。
以下是查找表延迟示例:
lu_table_template ( delay_template_6x6 ) { /* 查找表延迟模型
variable_1 : total_output_net_capacitance ;
variable_2 : input_net_transition ;
index_1 ( "1000.0, 1001.0, 1002.0, 1003.0, 1004.0, 1005.0" ) ;
index_2 ( "1000.0, 1001.0, 1002.0, 1003.0, 1004.0, 1005.0" ) ;
}
1.6 单元定义
工艺库中的标准单元通常包括基本单元,如门电路、触发器、选择器等;I/O单元,如输入端口、输出端口、 双向端口、各种配置的电源(内核、I/O或振荡器;宏单元,如不同规模的 SRAM、 ROM、振荡器等。
库单元的定义包括单元的功能、时序特性和面积、引脚等属性。单元属性因单元不同而有差别。例如,定义了单元的面积属性 area,若单元为PAD,则其面积属性为0.0,这是因为 PAD 不作为内部逻辑门使用;单元的cell_footprint,具有相同几何拓扑结构的单元其cell_footprint 属性相同,若in_place_swap_mode 属性为 match_footprint,那么单元只能有一个footprint,如果一个单元没有cell_ footprint属性,那么在位优化时不能被替换;引脚的数据流向、驱动能力以及时序信息等。
库单元的定义同时还包括一些设计规则检查 (DRC, Design Rule Check) 的属性。DRC 属性定义了库单元安全工作的条件,违反这些条件将对单元的正常工作产生严重影响。
max transition 属性通常用于输入引脚,用来定义任何转换时间大于负载引脚,max_ transition 的连线不能连接到该引脚;max capacitance 属性通常用于输出引脚,用来指定驱动单元的输出引脚不能和总电容大于等于该值的互连线相连。
若发生 DRC 违例,则需替换相应单元。这里需要注意的是,引脚的 capacitance属性和 max capacitance 属性是不同的,capacitance 属性只用于进行延时计算,而max capacitance 属性则用于设计规则检查。
二、层次划分
设计划分的方法分为HDL划分和DC划分,HDL划分是根据原则通过HDL编码对设计进行划分;DC中的划分是在DC通过专门的命令来改变HDL中的划分和层次结构。
HDL划分的原则有:
将相关的组合逻辑划分到一起;
消除胶连逻辑(glue logic);
模块的输出应使用FF或划分以FF为边界;
合理限制模块的大小;
分离用于同步多个时钟的模块;
划分顶层(core logic, pads, clocks, and JTAG)。
DC划分命令:group、ungroup,这个在后续的DC相关的TCL命令介绍。
2.1 寄存器吸收组合逻辑
把与目标寄存器相关的组合逻辑分到与目标寄存器相同的块中, 顺序优化可以将一些组合逻辑吸收到一个更复杂的触发器中。
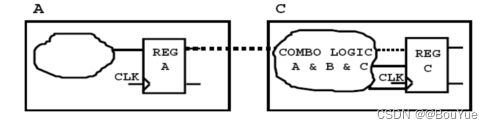
2.2 寄存器输出划分边界
可以尝试按照寄存器输出来设计层次结构边界, 简化了时序约束, 每个块的所有输入都以相同的相对延迟到达。
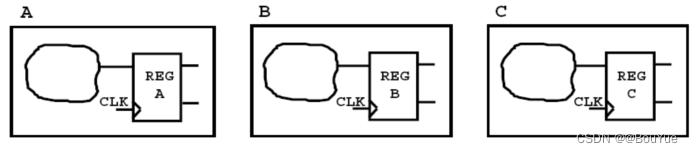
2.3 避免胶连逻辑
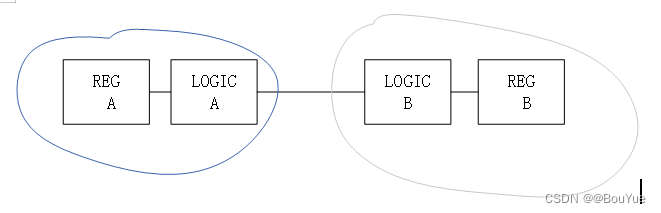
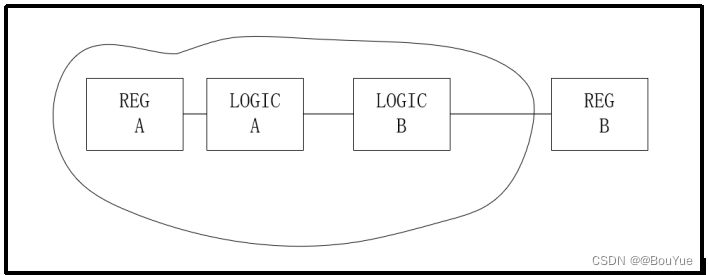
如上图,两个寄存器以组合逻辑连接,这样在顶层就会出现这样一种情况,两个子模块之间通过一块组合逻辑电路连接,这种划分情况会造成时序错乱,应该尽可能把组合逻辑放到一起,可以用其他逻辑对粘合逻辑进行优化,最终达到“顶层只有网”,如下图:
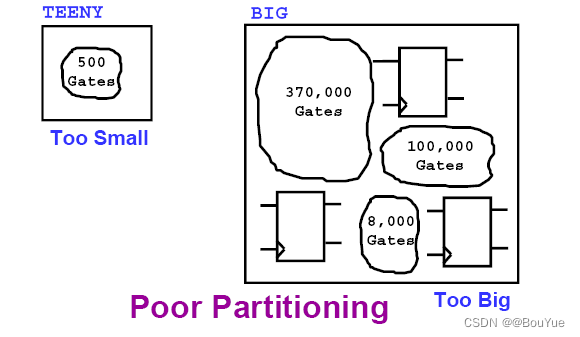
2.4 合适尺寸匹配速度
为了时序更快,应该使划分的每个模块有5000 - 150000个门,编译器没有固有的限制,主要依据 CPU和内存匹配模块大小。 在有足够的资源时,模块越大越好, 但有功率限制时,应该选择较小的尺寸。如果块太小,编译可能会被限制,可以人为优化, 如果块太大,编译运行时间可能会非常长。
三、编码风格
3.1 锁存器与寄存器
当组合逻辑的HDL代码条件分支语句(if-else/case)没有完全指定时,DC综合工具会推断出锁存器;
当时序逻辑的always块敏感列表中指定了一个边沿则推断出寄存器,且此时要带复位和置位信号。
3.2 多路选择器推断
多路选择器使用if-else-if或case,if-else-if综合为优先级编码器,而case可以设置有无优先级,case有两条语句来完成设置,分别为parallel_case和full_case。
首先是parallel_case:
case (CASE_SIGNAL)
begin
CASE1: A = B;
CASE2: A = C;
default: A = D;
end
endcase
在这个case语句中,条件是有优先级的,CASE1的优先级最高,CASE2次之,default最后。但实际中不同的case不会同时产生,那么综合器生成的优先级逻辑就是冗余的了。为了去除这些冗余逻辑,就用
case (CASE_SIGNL) // synopsys parallel_case
来告诉综合器,不需要产生优先级逻辑,而缩小了硬件的规模。但产生的副作用是,设计者要保证CASE1和CASE2不会同时发生,否则A会被赋予一个不确定的值。
然后是full_case:
case (CASE_SIGNAL[1:0])
begin
CASE1: A = B;
CASE2: A = C;
CASE3: A = D;
end
endcase
此例中case选项不完整且没有default的选项,综合器会产生一个latch,但现实中此电路有且只有这三种情况。这时候,使用
case (CASE_SIGNL) // synopsys full_case
来告诉综合器,所有的CASE已经覆盖,不需要自动产生latch。但产生的副作用是,设计者要保证只会有CASE1、CASE2和SASE3,不会有CASE4的出现,否则A会是一个不确定的值。
其实full_case和default分支的作用是一样的,在case语句中只要有full_case或者default就可以了。
3.3 if和case
这里给出了if和case两语法常见的一些情况:
1、如果条件是互斥的,那么就用case语句,这样综合的面积和时序都会更优一些。
2、如果条件不是互斥的,而是有优先级结构的,那么就用if elseif else…。
3、如果条件不是互斥而用了case,并且不加 //synopsys parallel_case,那么综合后的电路会有优先级的结构,可能不是最优的结构(相比if else而言)。
4、如果条件不是互斥加了//synopsys parallel_case,那么综合的时候工具会按照parallel的情况来进行优化,会导致rtl仿真和综合后仿真结果不一致。
5、如果条件互斥加或者不加//synopsys parallel_case,影响不大。
6、如果条件case是full的,加或者不加//synopsys full_case,没有什么影响。
7、如果条件case不是full的,加//synopsys full_case以后,那么综合的时候其它的cases就会被当成don’t cares,而仿真的时候却被当成latch来处理,会造成综合前后电路不一致。
8、如果条件case不是full的,而且没有加//synopsys full_case,那么RTL仿真和综合的时候都会引入latch,这是设计不允许的,必须保证不要出现这种情况。
只使用if语句推断锁存器和优先级编码器;只使用case语句推断多路选择器,且总是指定default分支。
3.4 仿真代码
由于设计文件中有的RTL代码只用于动态仿真,则需要使用以下语句告诉合工具不要综合下面代码translate_off&translate_on,示例:
`ifdefine MY_State
`define State_ID 16’h0aef
`else
`define State_ID 16’h0afe
`endif
//synopsys translate_off
`ifdefine MY_State
//synopsys translate_on
`define State_ID 16’h0aef
//synopsys translate_off
`else
`define State_ID 16’h0afe
`endif
//synopsys translate_on
3.5 for循环综合
在综合中,for循环在过程中先“展开”,再综合,即如下所示:
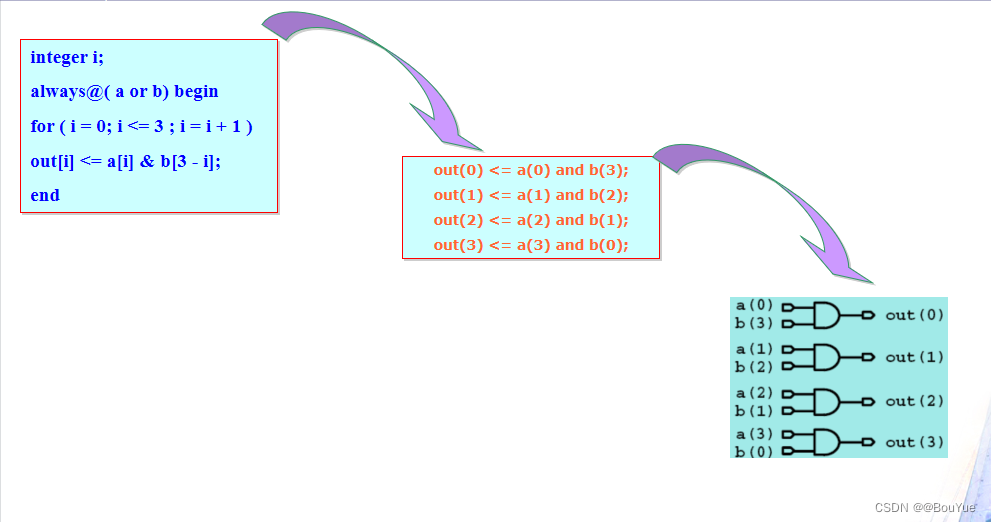
3.6 算术运算综合
算数运算综合如果只要求功能正确就有多种综合方案,但方案之间的差别就在延时上,如下图所示,对算数运算的综合优化就在于对输入信号重新排序,以达到延时最小。
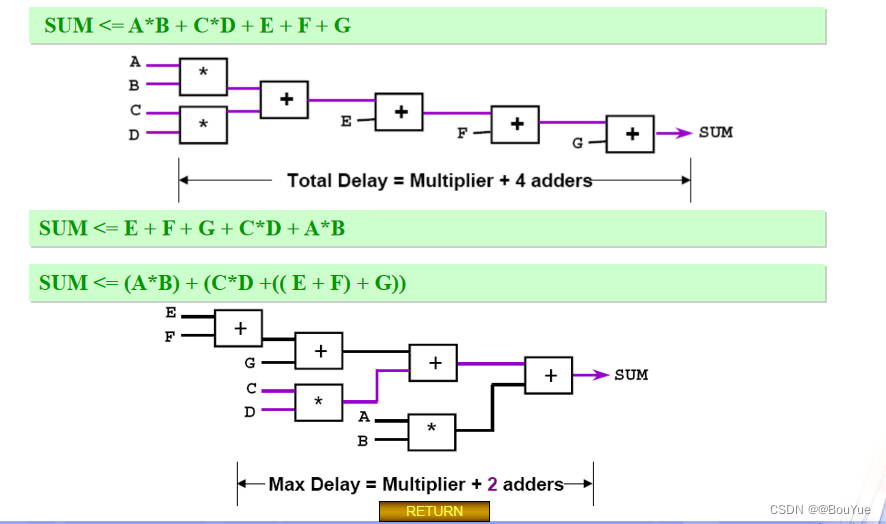
3.7其余可综合总结





本文介绍了影响DC综合的四大因素之三,分别是工艺库、层次划分、编码风格。接下来就是重头戏DC编译指令。下文介绍…
最后
以上就是陶醉心锁最近收集整理的关于EDA11--DC逻辑综合(二)逻辑推断一、工艺库二、层次划分三、编码风格的全部内容,更多相关EDA11--DC逻辑综合(二)逻辑推断一、工艺库二、层次划分三、编码风格内容请搜索靠谱客的其他文章。








发表评论 取消回复