-
2020-3-16
StarGAN v2: Diverse Image Synthesis for Multiple Domains
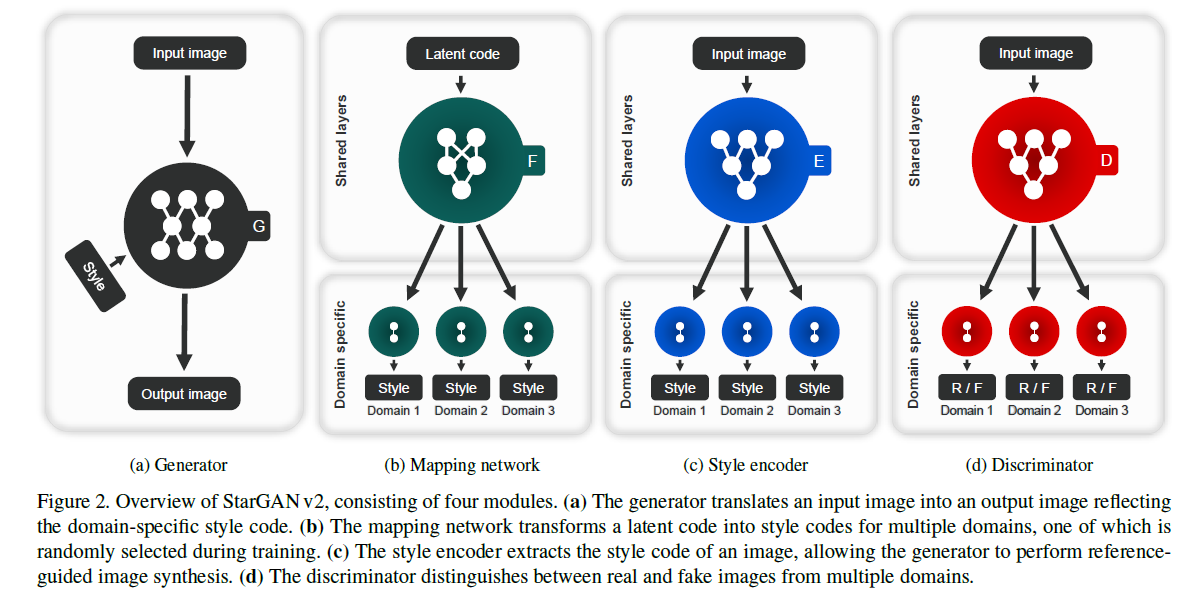
Mark 多域instan-level style transfer
(1)为了做多域,D没有用ACGAN,而是输出了多对real/fake,看是不是这一类的。很有创意的想法。(2)编码从两种情况来,一种是先验高斯分布,经过一个Fcn来,Fcn输出了很多编码,用于支持不同类。另一种是E输出了很多类的style。(3)G输入图片和一个风格编码,类别隐式嵌在风格编码中。风格编码会进行生成-编码重构。图像也会做二次重构。而且风格用AdaIN嵌入(4)为了让不同编码图片尽可能diverse,惩罚了两种编码生成后的距离。这个惩罚项没有最优解,所以衰减于前5W轮。很牛逼的想法。(5)开了个AFHQ数据集,包括dog,cat, wildlife
https://github.com/lzhbrian/image-to-image-papers instance-level style transfer

-
2020-3-15
Image-to-image translation via group-wise deep whitening-and-coloring transformation
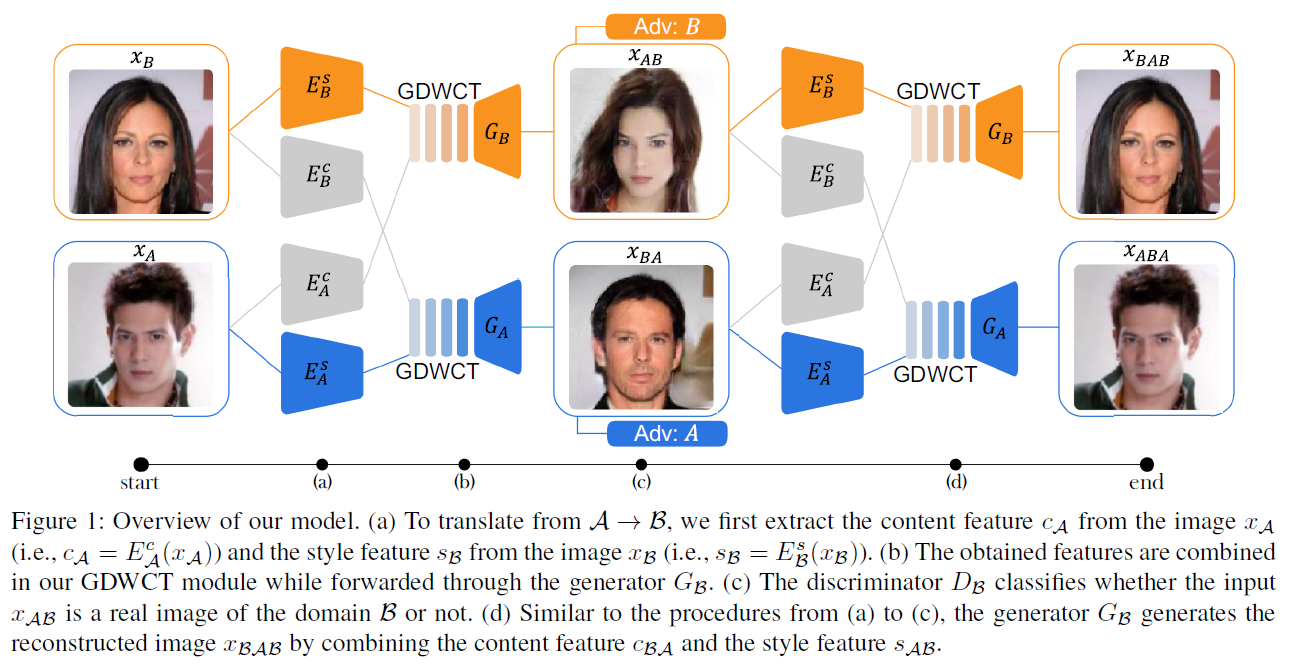
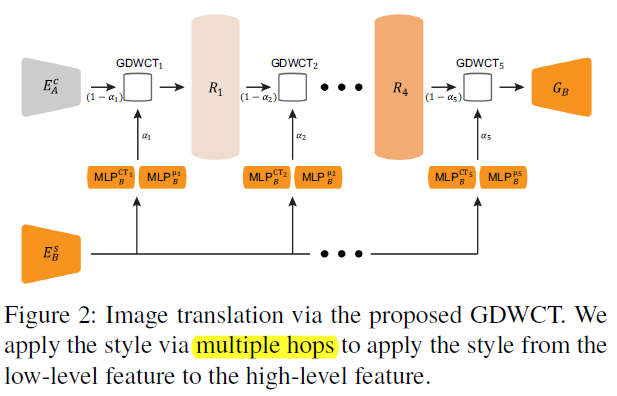
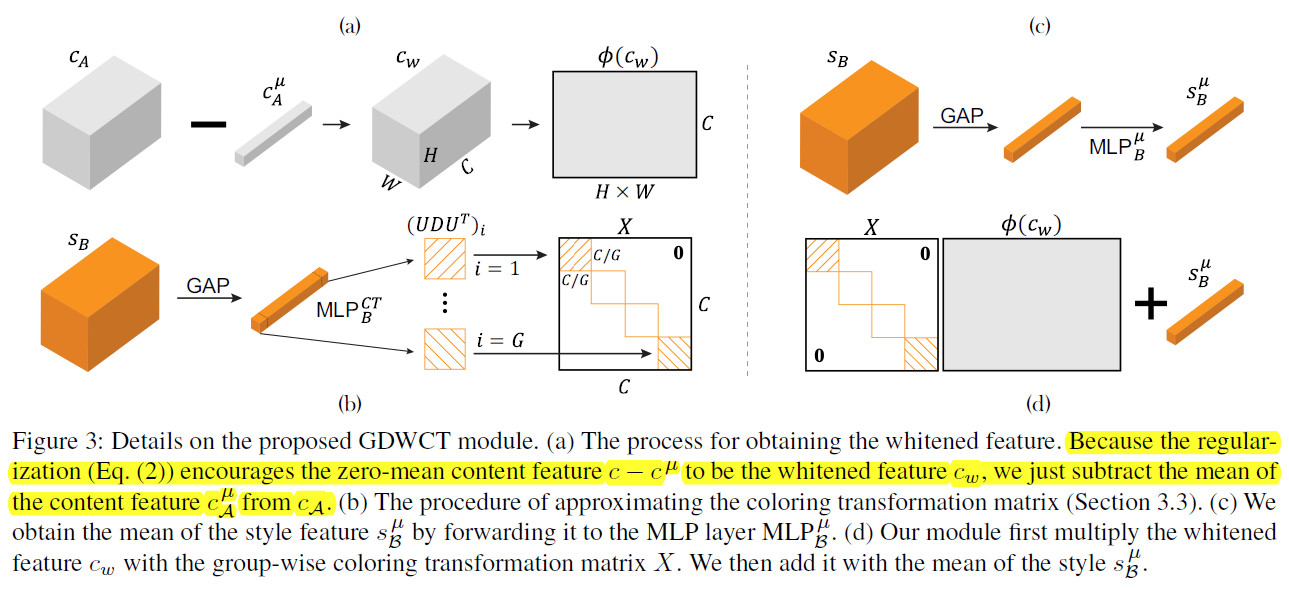
Mark GDWCT CVPR2019 instance-level strly transfer,和MUNIT、DRIT在一个任务上
两方面:(一)整体结构方面,四个encoder,两个decoder,两个D。交换两次,图像上一次重构、二次重构,风格编码和content编码也重构。(二)提出GDWCT,主要贡献。decoding之前,在网络结构上把style encoding 搞进到content encoding去。很硬核。WCT原理大概是先whitening,把content特征层进行channel维度归一,也即均值维度是channel数。再coloring,通过矩阵变换让特征层的协方差与一个style matrix一致,再加上style给的一个均值。由于这么搞参数是 C 2 C^2 C2,这个过程如果不再channle上进行,而把channel分解成多个group,再每个group上进行,那么参数量是 ( C / G ) 2 × G (C/G)^2 times G (C/G)2×G. 这就是DGWCT。另外,这个过程是通过一个0到1之间的系数,分多步(hop)完成的,每一步的style参数还不一样。强的一批。原文细节大概一页,值得看
https://github.com/lzhbrian/image-to-image-papers instance-level style transfer

-
2020-3-15
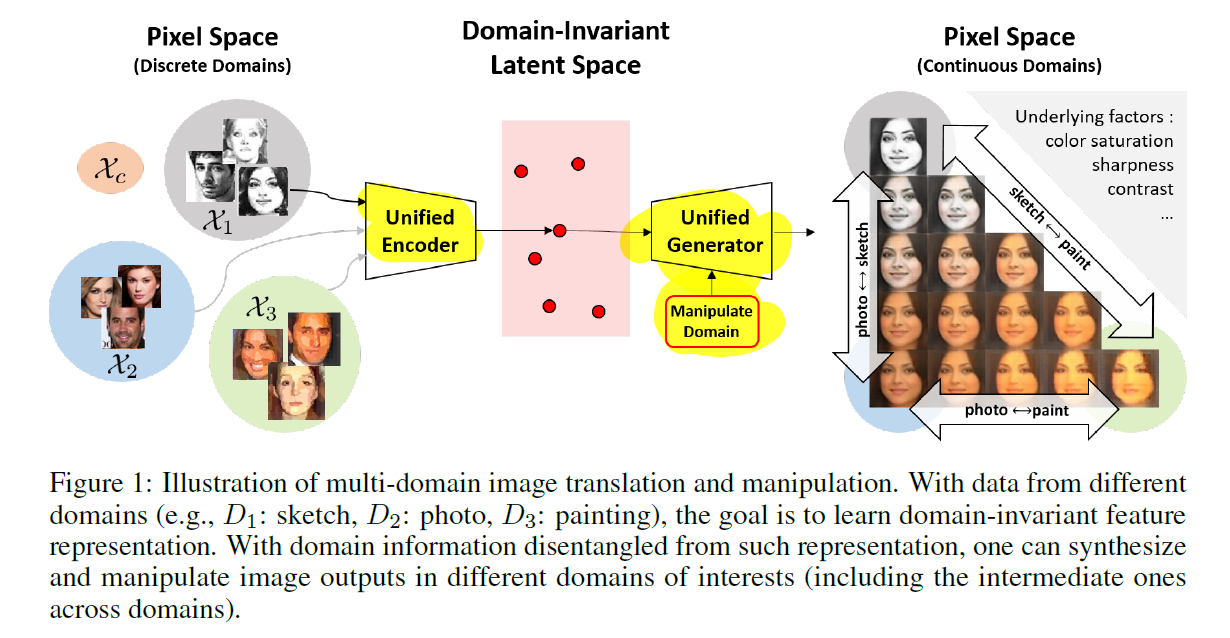
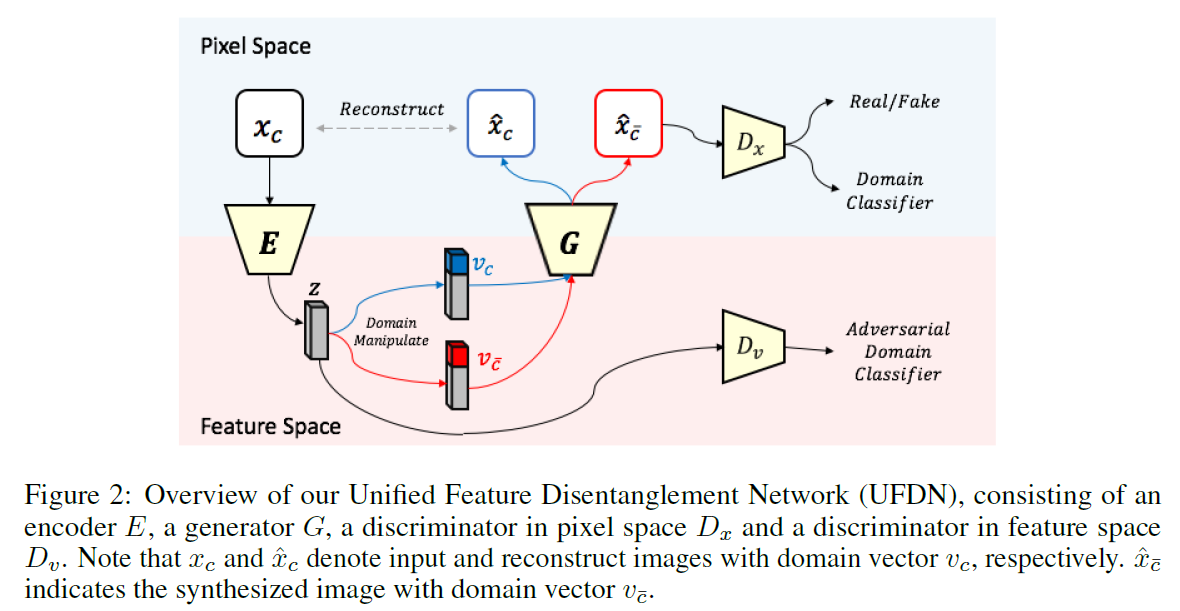
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation
NIPS2018 multi-domain 人脸 轮廓 图画,disentangle UFDN
把不同domain解到同一个隐空间,然后加上domain vector,进行generator。loss方面:(1)隐空间vae一套。(2)用一个 D v D_v Dv去根据隐编码E(x)辨识domain,encoder学着不让 D v D_v Dv分辨出来。有点像fadernetwork。(3)ACGAN.这里的 D c l s D_{cls} Dcls同时训练了生成图片,类似原始ACGAN中用info的部分。(ablation study说去掉(2),domain vector直接挂掉,有点奇怪,猜测可能是info的原因)。该方法也用于unsupervised domain adaptation(uda)
https://github.com/lzhbrian/image-to-image-papers Unsupervised multi-domain

-
2020-3-14
PairedCycleGAN: Asymmetric Style Transfer for Applying and Removing Makeup
CVPR2018 instance-level makeup
和GeoGAN有点像,添加有source,删除没source。交换两次实现对偶重构,保持风格。一个亮点是用判别器判断两张脸是否同样的style,为了造真实数据集,generate a synthetic ground-truth by warping the reference makeup face to match the detected facial landmarks in the sorcue fae x. (我不太懂这个是怎么做到的)。为了做512高分辨率,G只负责局部生成(眼睛、嘴唇、皮肤)。G没有用U-Net、STN,而使用了DilatedResNet,认为DRN utilizes the high-resolution feature mapes to preserve image details.
https://github.com/lzhbrian/image-to-image-papers Unsupervised Instance-level


-
2020-3-14
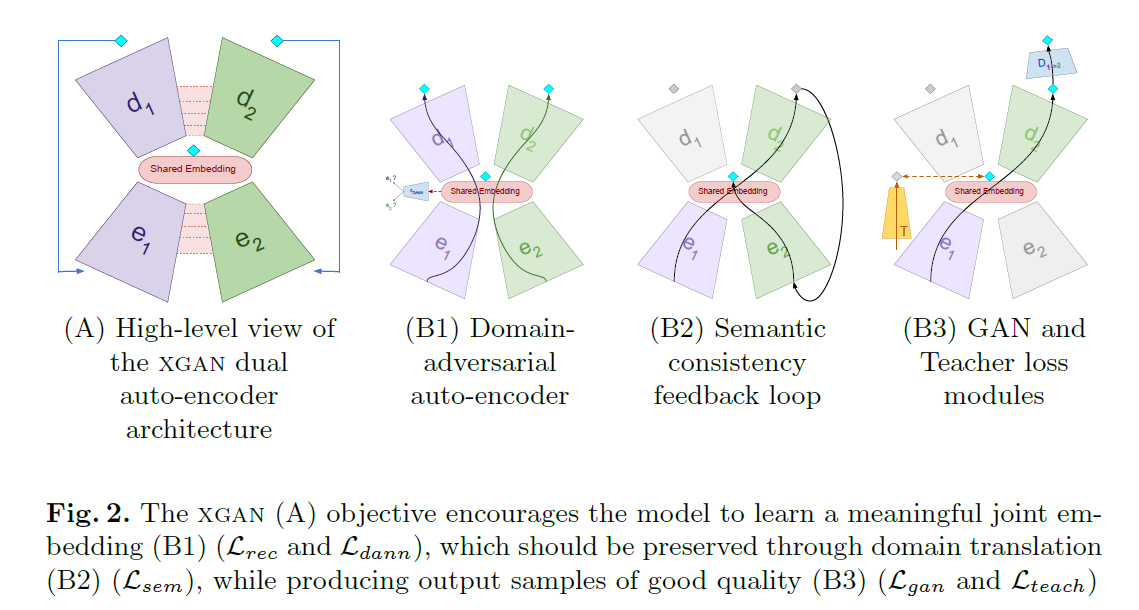
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
ICML2018 人脸到卡通,对标CycleGAN和UNIT
和UNIT有点像,两个Encoder,两个Decoder。把两个域都映射到同一个隐空间。loss有5个。(1)一次重构。(2)对抗训练,用于混淆隐编码来自哪个类。(3)为了保持不同域的语义内容一致,最小化 ∣ ∣ e 1 ( x ) − e 2 ( d 2 ( e 1 ( x ) ) ) ∣ ∣ ||e_1(x) - e_2(d_2(e_1(x)))|| ∣∣e1(x)−e2(d2(e1(x)))∣∣,这里没有直接从隐空间采样,而是从 e 1 ( x ) e_1(x) e1(x)来了,原文似乎也没有对隐变量给先验分布。(4)两个域两个判别器,对抗训练。(5)让人脸的隐变量解到一个先验知识上,这里先验知识用的是FaceNet的特征层。(*)不同域encoder的最后两层,decoder的前两层share了。(*)作者承认,loss(3)和(4)可以理论上代替(2),但是(2)在训练初始让不同域编码更一致。此外,提供了CartoonSet Dataset
https://github.com/lzhbrian/image-to-image-papers Unsupervised general

-
2020-3-14
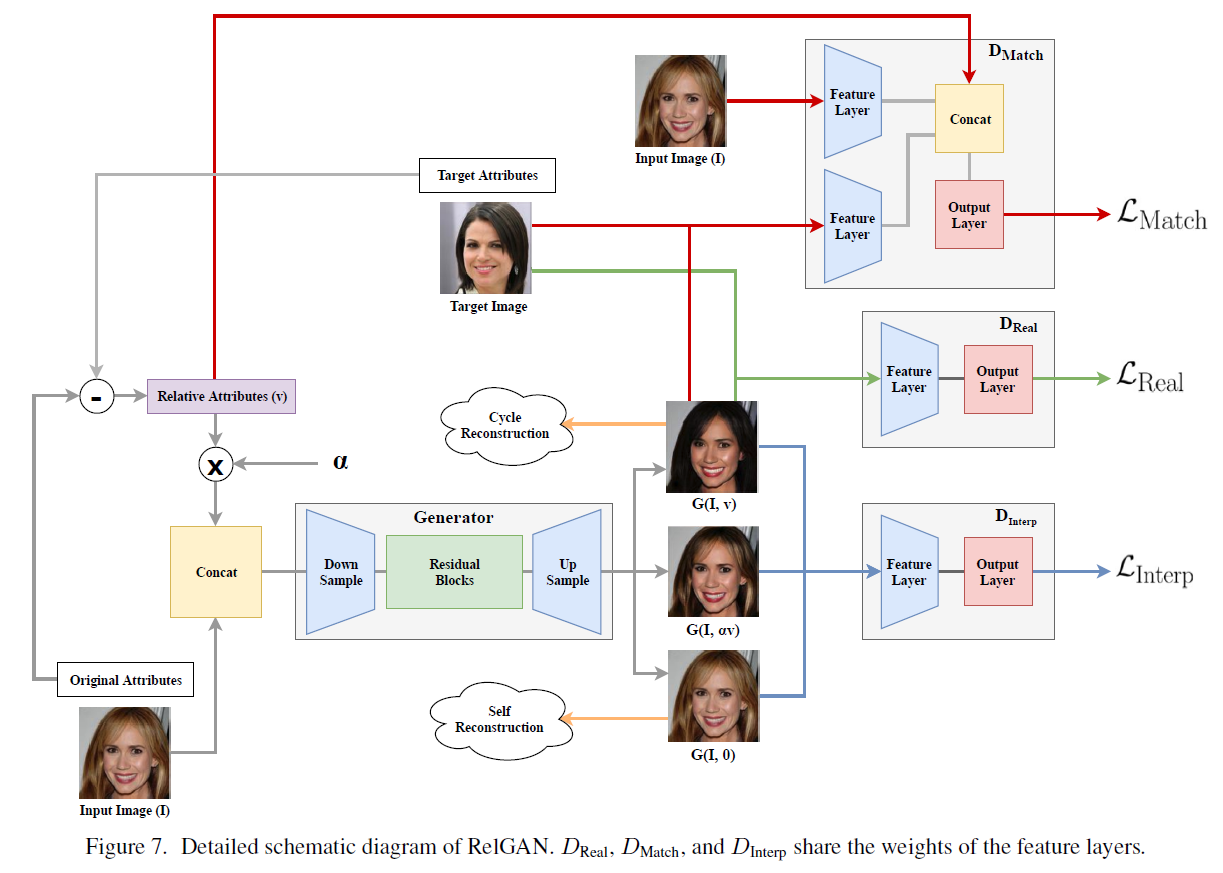
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
ICCV2019 多属性语义级人脸编辑。对标StarGAN和AttGAN
(1)类似STGAN的类别相减信号,没有用ACGAN属性分类,而是引入了一种 D M a t c h D_{Match} DMatch,判断 [ x , x ′ o r G ( x , v ) , v ] [x,x' or G(x,v), v] [x,x′orG(x,v),v]三元组是否是真实的,有想法,但问题是 x x x和 x ′ x' x′不是成对的,而 x x x和 G ( x , v ) G(x,v) G(x,v)是成对的,不会出问题吗?(2)为了支持程度interpolation,引入 D I n t e r p D_{Interp} DInterp预测程度 α ^ = m i n ( α , 1 − α ) hat alpha=min(alpha, 1-alpha) α^=min(α,1−α). D I n t e r p D_{Interp} DInterp希望把二值编辑置0,而中间编辑置 α ^ hat alpha α^, G G G学着把中间编辑判成0,很有亮点!最后引入1次和2次重构。实验超级充分。
https://github.com/lzhbrian/image-to-image-papers Unsupervised Multi Attribute




-
2020-3-13
Toward Learning a Unified Many-to-Many Mapping for Diverse Image Translation
PR2019 多域无监督,multi-modal InjectionGAN
和STD-GAN的想法很像啊,但是E没有和D去share,也没有分removing和adding两步。所以这个E提了很多全局的东西。定量实验做的很多。正态分布KL约束Latent。且Encoder重参数化有扰动
https://github.com/lzhbrian/image-to-image-papers Unsupervised Multi Attribute

-
2020-3-12
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
ACCV2018 多域无监督转换
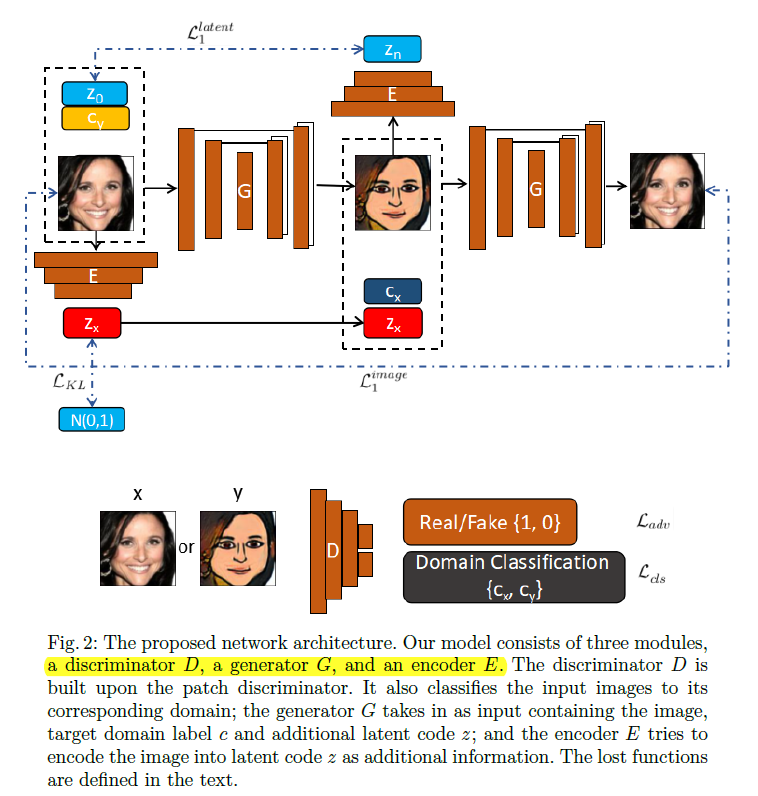
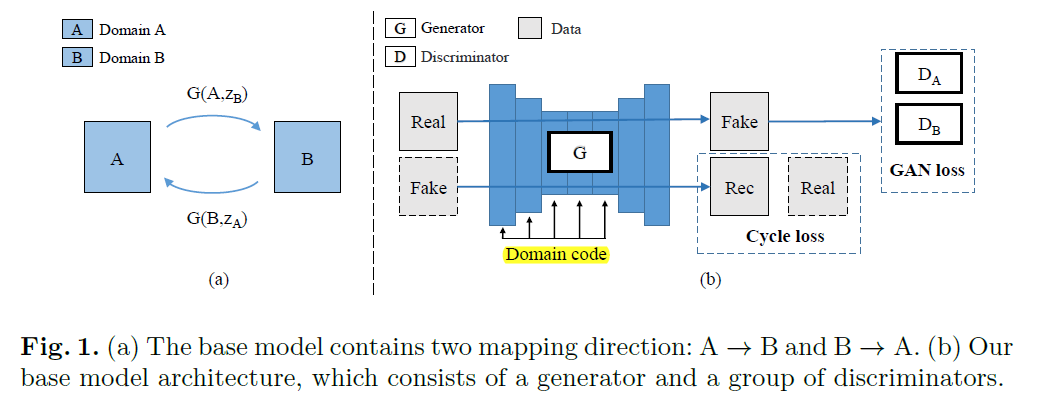
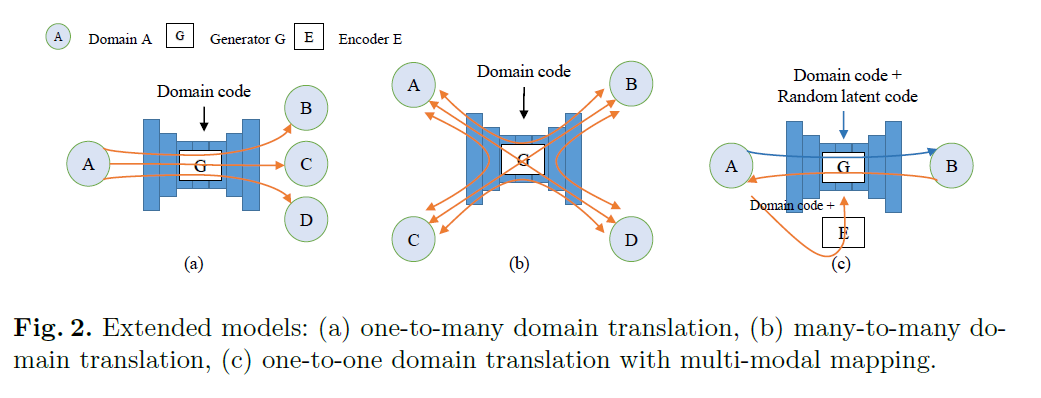
一个G,多个D。G和StarGAN类似,但是z是one-hot编码,(类似于一个属性的多种取值),而且没有直接concatnate,而使用了central biasing IN(CBIN)来影响x。D不分类,搞了多个。有二次重构。Many-to-many translation随机挑两个类互转。本文还做了one-to-one domain translation with multi-modal mapping. 类似VAE,引入隐变量c,比较神奇的是,用了VAE中的KL散度约束c高斯分布,而且用了c和E(G(x,c))的重构,这一点很有启发性.
https://github.com/lzhbrian/image-to-image-papers Unsupervised Multi Attribute

-
2020-3-12
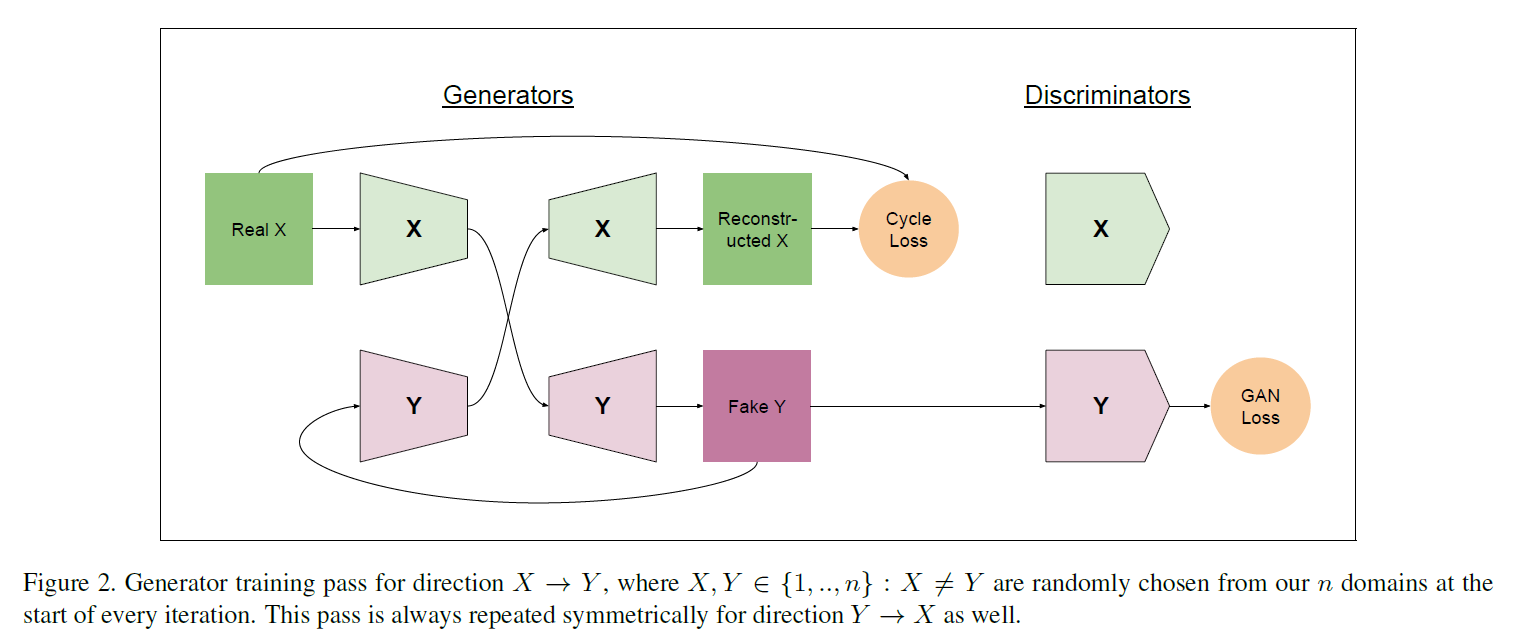
ComboGAN: Unrestrained Scalability for Image Domain Translation
CVPRW 2018 CycleGAN的多域扩展
把CycleGAN中的生成器拆成E和G两块。多个Encoder都编码到同一个隐空间z。多个Generator负责各自类别的生成。loss和CycleGAN保持一致。将模型数量从 O ( n 2 ) mathcal O(n^2) O(n2)降到 O ( n ) mathcal O(n) O(n)
https://github.com/lzhbrian/image-to-image-papers Unsupervised Multi Attribute

-
2019-9-22
Unsupervised Eyeglasses Removal in the Wild
arXiv1909 Mark Instance Level Editing眼镜的增删
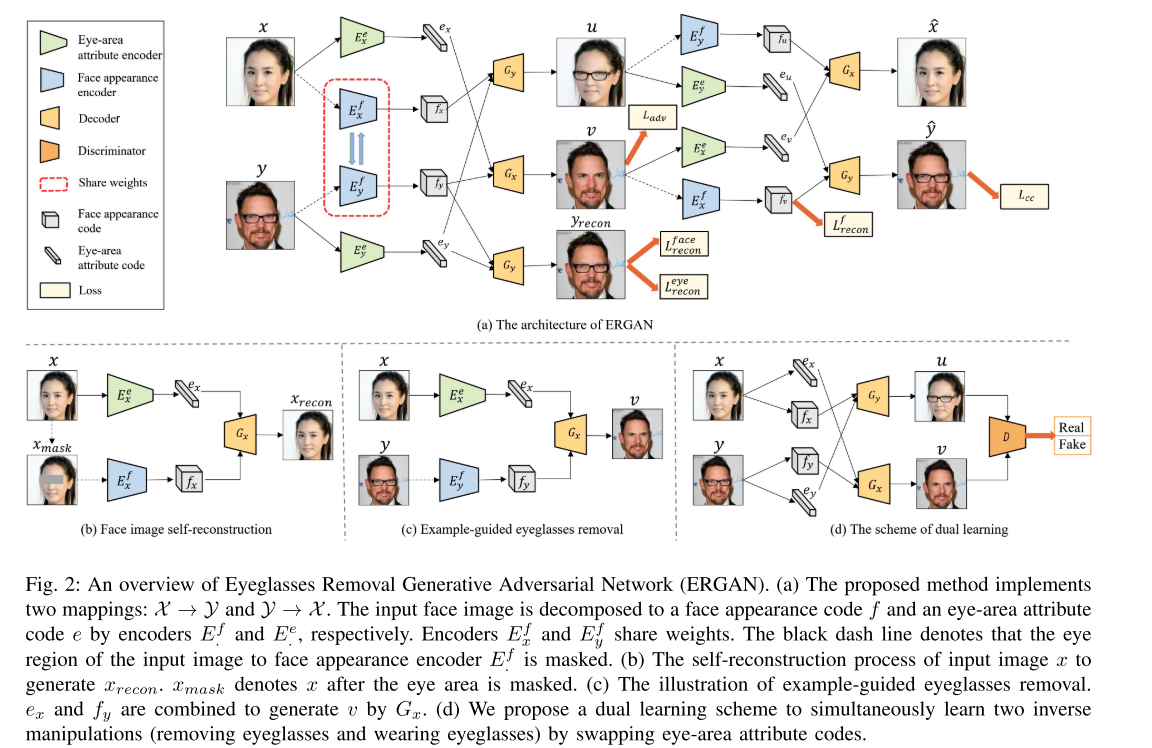
和之前Kim的那篇类似,将眼镜风格和身份解出来。创新点在于用一个矩形Mask盖住眼镜区域,然后去解身份,并希望能用两个向量复原整张原图。
特定风格,师兄推荐
-
2019-8-14
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation Cheng-Han
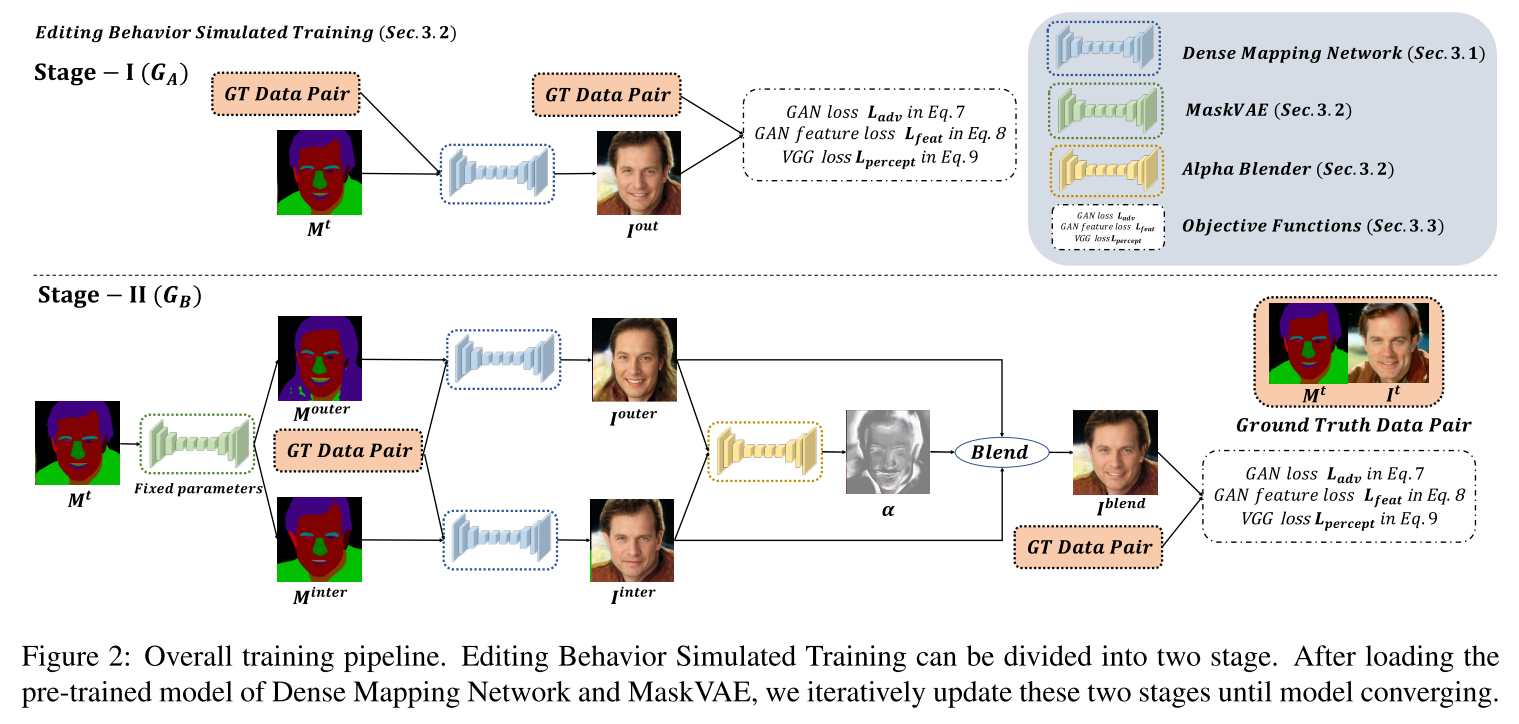
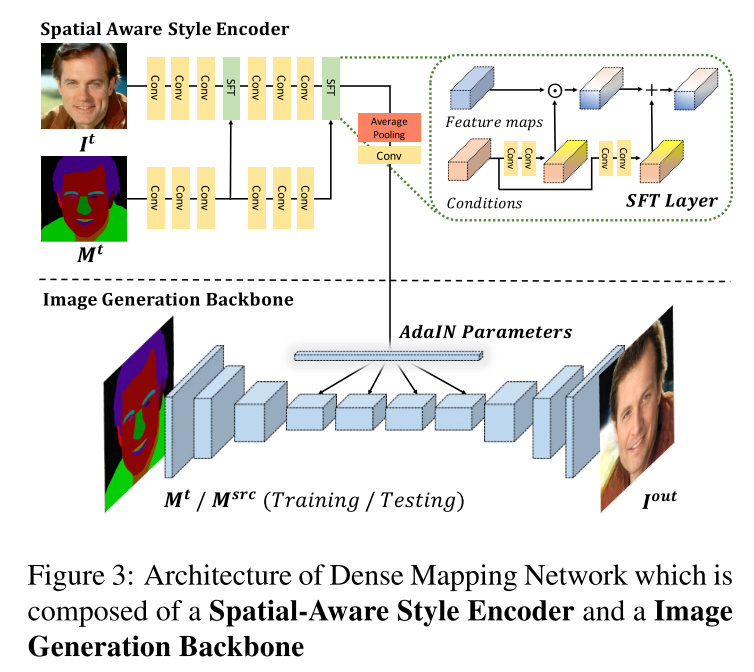
arXiv1907 Mark 提供CelebAHQ-Mask数据集,做Instance Level Editing。接收一张原图It、其mask Mt、另一张mask Msrc。改变It使其符合Msrc。Loss包括CGAN、Perceptual Loss D、Perceptual Loss VGG。Stage-I 进行重构训练,当该模型用于推断的训好后,Stage II利用VAE模拟人对mask的修改,得到两张M_outer和M_inter,利用Stage-I的网络生成两张图片I_outer和I_inter;并训练一个网络进行Blend来辅助生成网络的训练,GT为原图。Loss同上。牛逼啊!!!
特定风格

-
2019-5-28
Eye In-Painting with Exemplar Generative Adversarial Networks
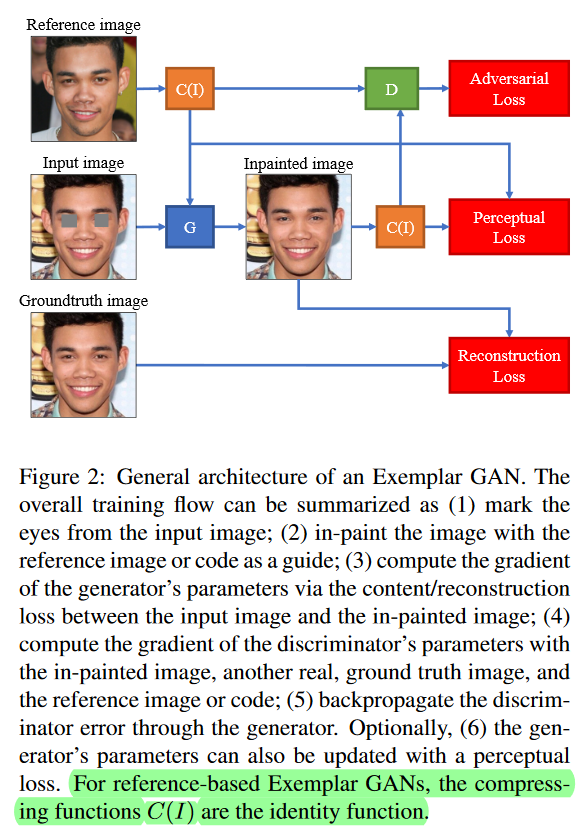
arXiv1712 略读。眼睛inpainting,有exampler。exampler解出风格编码,和mask之后的input image z一块生成结果,有groundtruth可以计算。真实图片的风格向量c与C(G(z,c))重构,G(z,c)与x重构。注意为了得到眼睛风格,C把单眼作为输入,输出128维,两个眼睛256维。
眼睛特定风格
-
2019-5-28
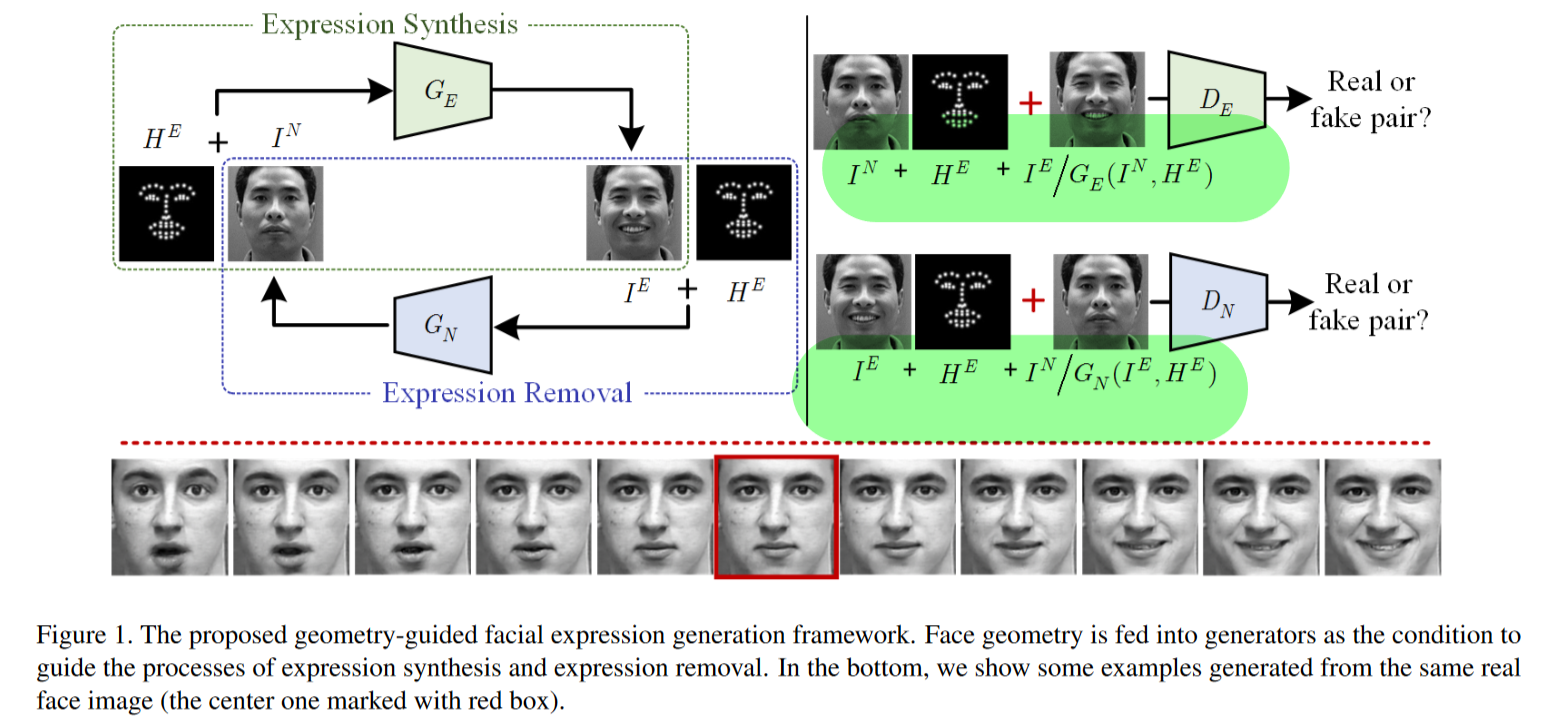
Geometry Guided Adversarial Facial Expression Synthesis
MM2018 示例级表情编辑 用脸部特征点指导表情变化,两个G,一个加表情,一个去表情。pair的数据,D分有表情和无表情两个,各自接收三张图,pair的一对图,和一张有表情的特征点图。用PCA对特征点对于自然表情的偏移进行降维编码表示,将降维后编码作为instance表情风格。貌似也可以直接操控特征点,改变脸部动作。
Instance level
-
2019-5-28
ST-GAN: Unsupervised Facial Image Semantic Transformation Using Generative Adversarial Networks
ACML2017 无监督属性编辑,InfoGAN原理。创新点:1、训练了E,用[z, c]的重构,用[z, c]生成的x’和重构x’'之间的perceptual loss。两项loss训练E。2、提出LST-GAN,用人给的局部Mask,得到x_local,送到D解c,希望InfoGAN能关注到局部属性上。
关注了一波一作

-
2019-5-28
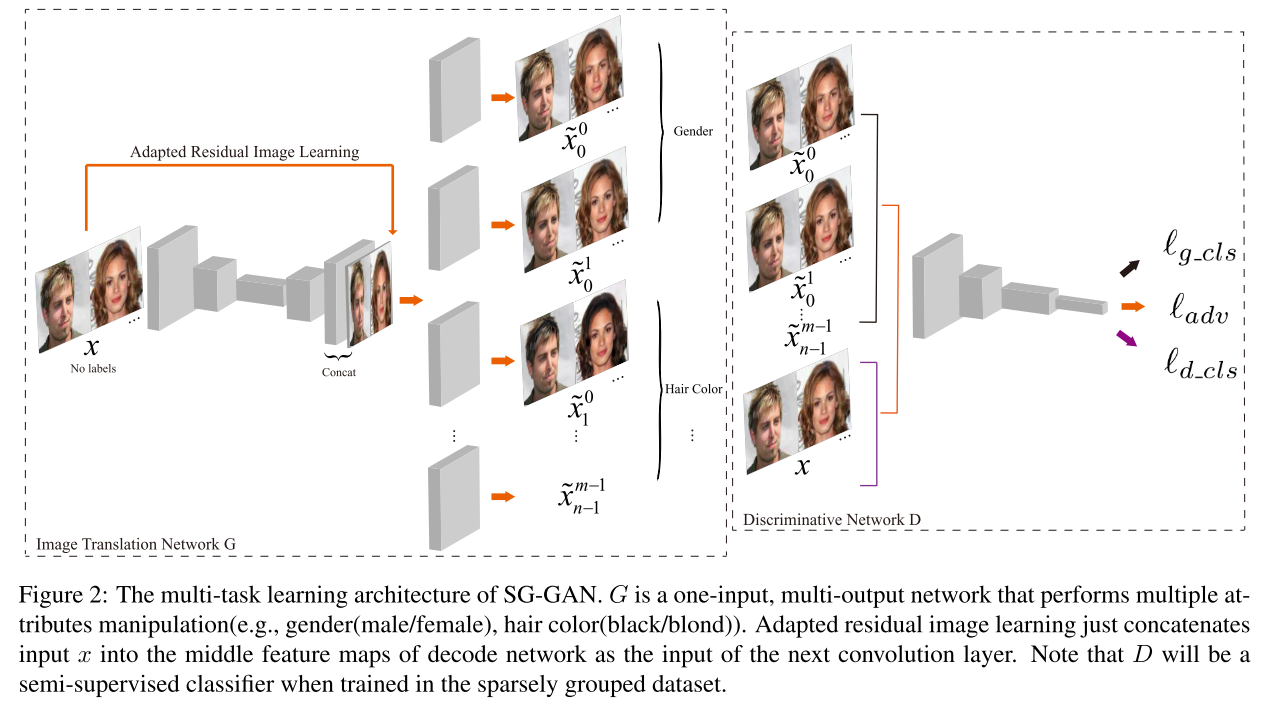
Sparsely Grouped Multi-task Generative Adversarial Networks for Facial Attribute Manipulation
arXiv1805 半监督人脸属性编辑。和StarGAN类似,相比StarGAN,dual rec用了x-x0-x1和x-x1. 估计是为了考虑x无label的情况。将无label的x送入生成器后,生成所有y对应的图片,以训练G条件编辑。 提出了Adapted Residual Image Learning,将Residual image没有直接相加,而是concat之后过conv。
很早看过一遍,人脸相关
-
2019-5-14
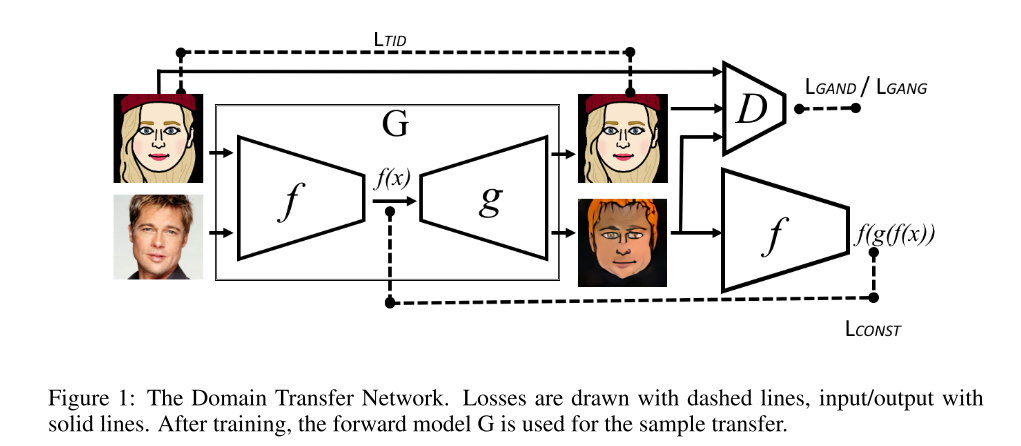
UNSUPERVISED CROSS-DOMAIN IMAGE GENERATION
ICLR2017 早期unpaired I2I G是一个target域的Autoencoder,把Source域的图片也直接送进来。对抗损失是三分类;D将target当作第3类,G(target)和G(source)分别当作第2类和第1类;G学习将G(target)和G(source)判为第3类. DTN
经典文章
-
2019-5-14
One-Sided Unsupervised Domain Mapping
NIPS2017 Unpaired I2I. 提出DistanceGAN。只从A域转换到B域;而不用反过来。Distance Constraints: 两张A域图片距离远,那么它们在B域的距离也应该远。还可以直接用一张图片对半切分,进行转换后的距离评价。
经典文章

-
2019-5-14
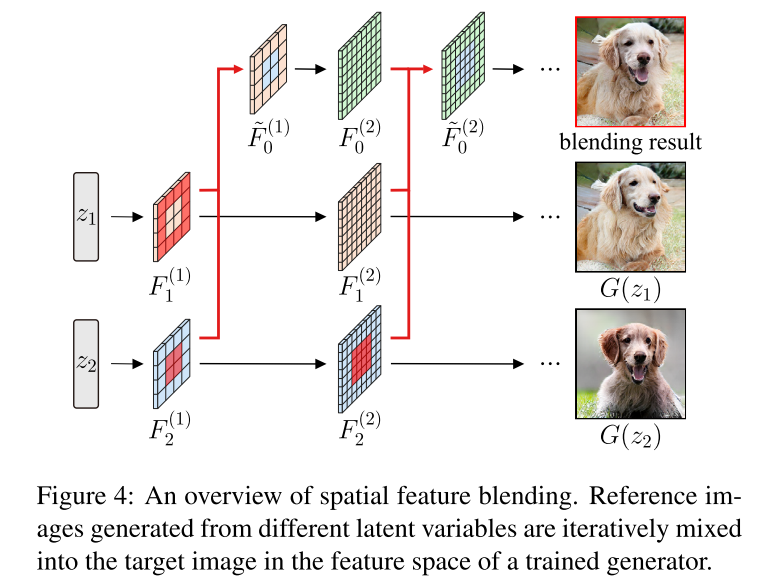
Spatially Controllable Image Synthesis with Internal Representation Collaging
arXiv1811 Mark 两张图片的融合,局部融合。在feature map上进行局部交换。还提出了sCBN(Spatial Conditional Batch Normalization As)。但在真实图片上做交换,貌似需要一个invert encoder。可能要补看一下。
来源忘了

-
2019-5-14
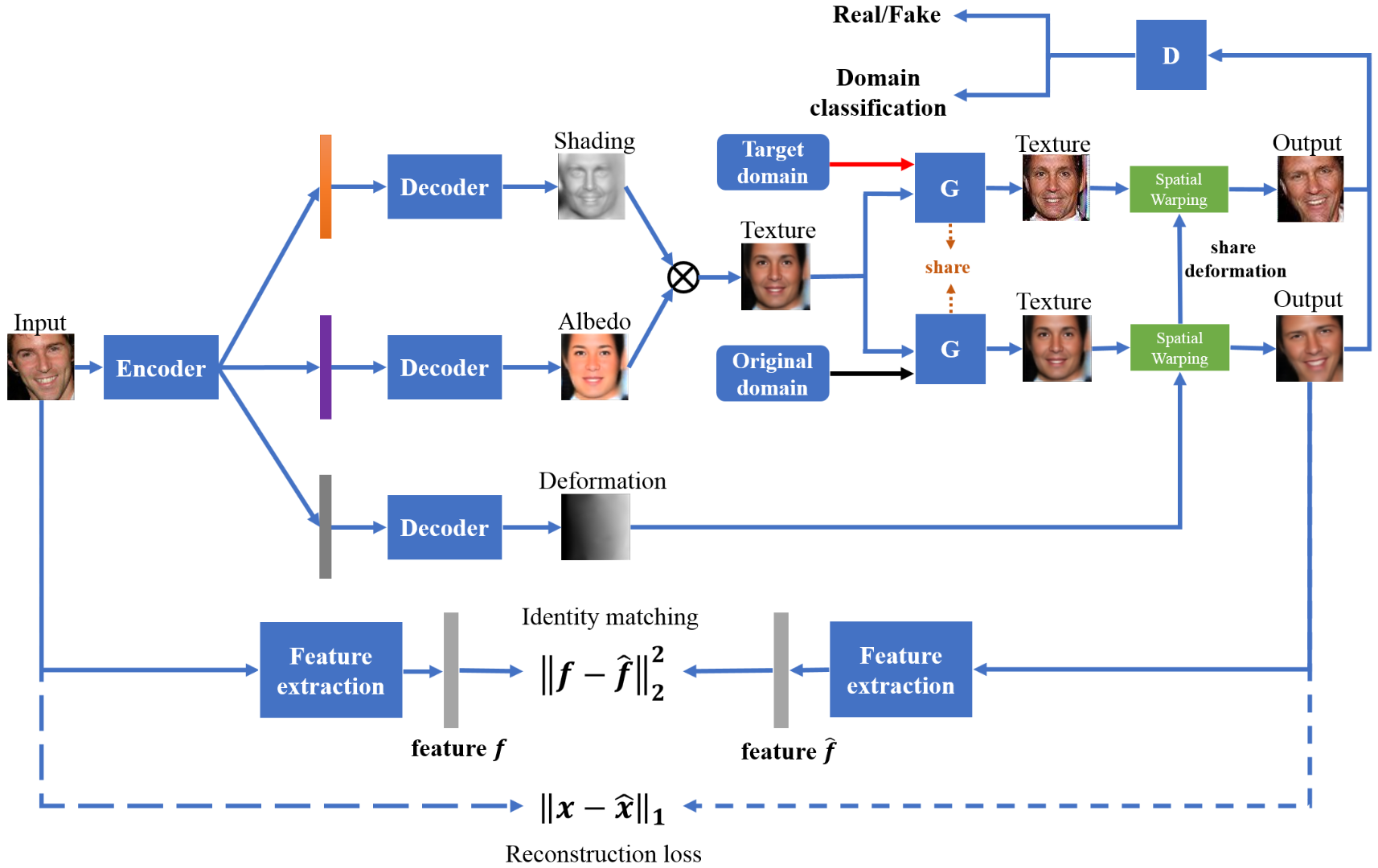
Texture Deformation Based Generative Adversarial Networks for Face
Editing
arXiv1812 略读。Facial Attribute Editing。将人脸分解为Shading、Albedo、Deformation。然后对Texutre做编辑(把Texture当作类似stargan的输入)。分阶段训练,第一阶段训Intrinsic Deforming Autoencoder (DAE);第二阶段类似训StarGAN。分辨率64
ELEGANT被引
-
2019-5-13
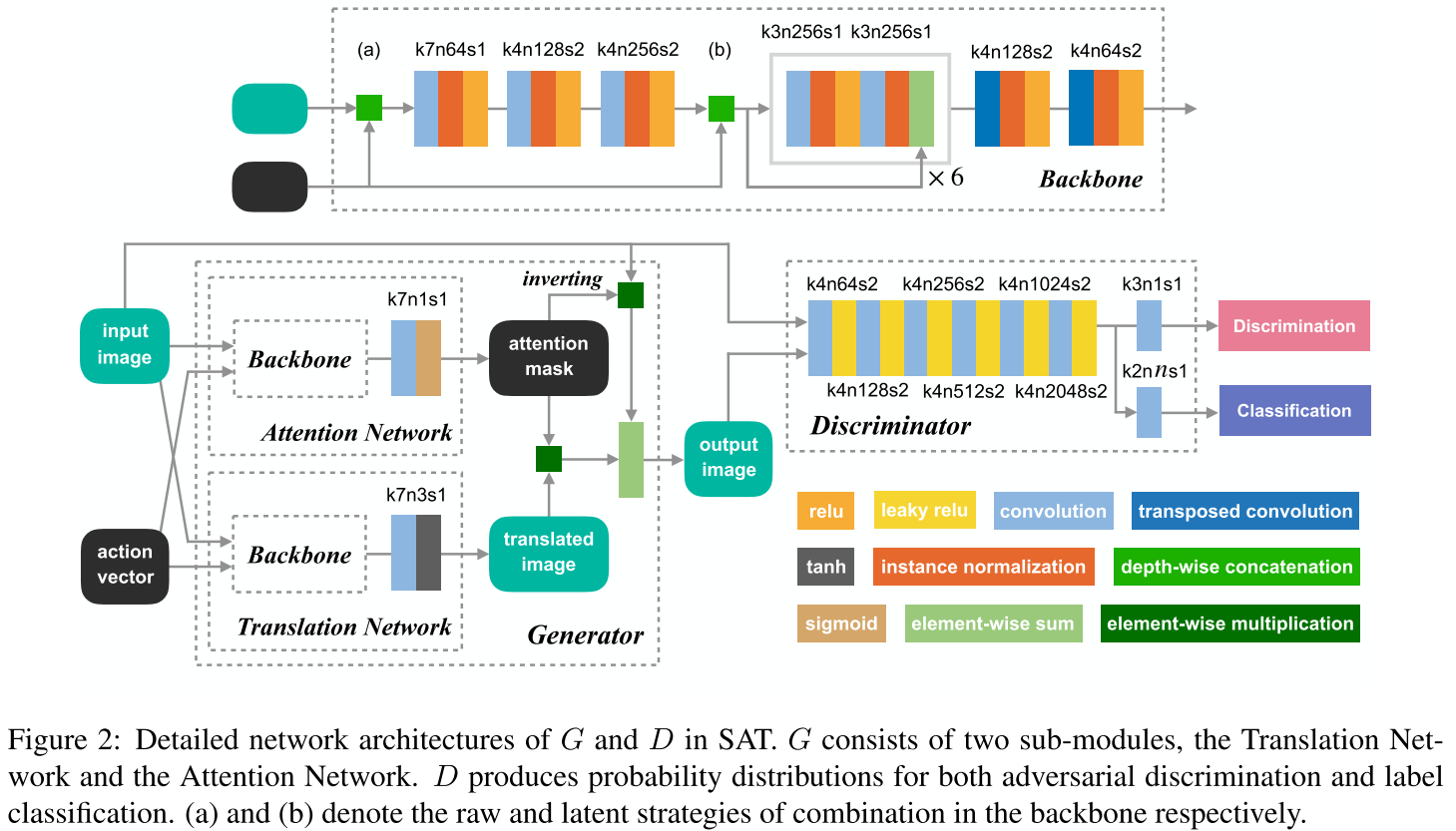
Show, Attend and Translate: Unpaired Multi-Domain Image-to-Image Translation with Visual Attention
arXiv1811 StarGAN+SaGAN,灌水文章;属性信号用了1-0和0-1;属性输入放到了residual开头。
来源忘了
-
2019-5-13
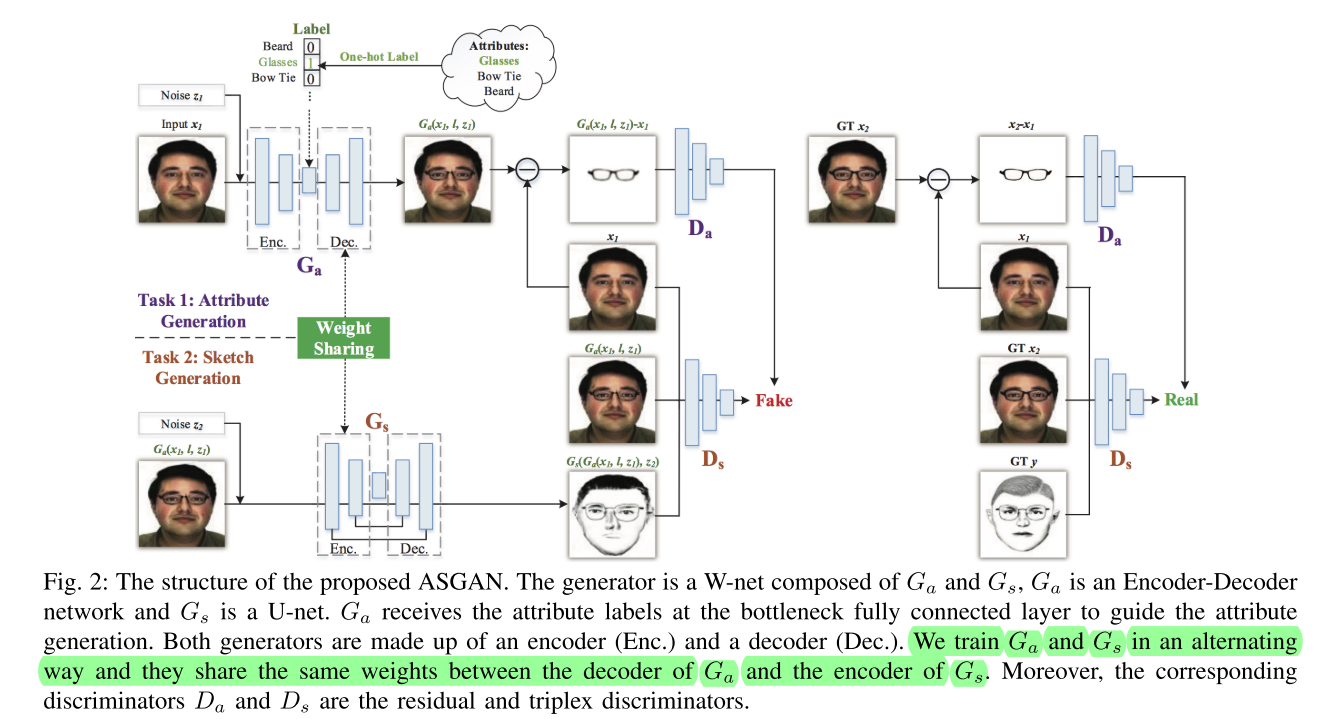
Attribute-Guided Sketch Generation
arXiv1901 略略读。给人脸加眼镜,然后再生成轮廓。(奇怪的任务)提出了W-Net;看不懂的weight-share
来源忘了
-
2019-5-13
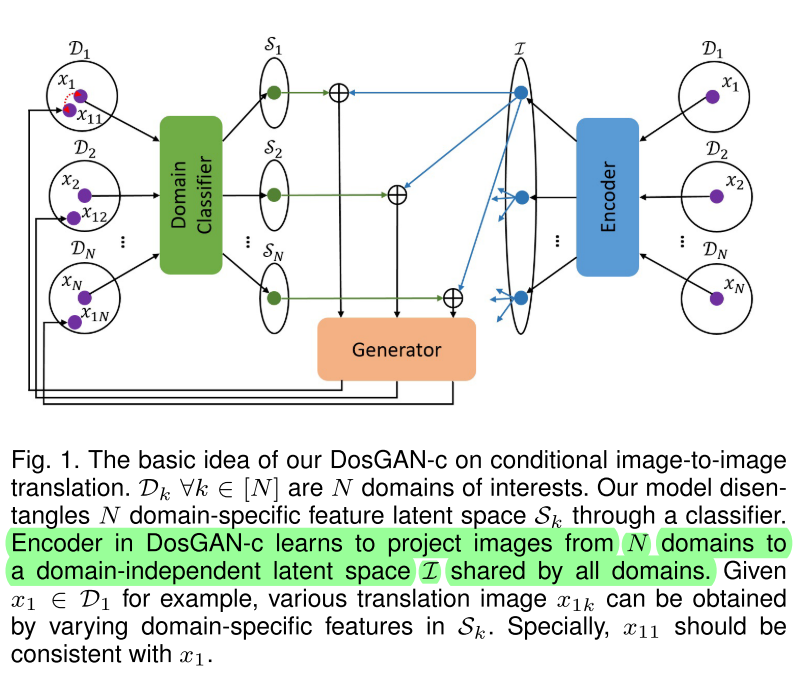
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
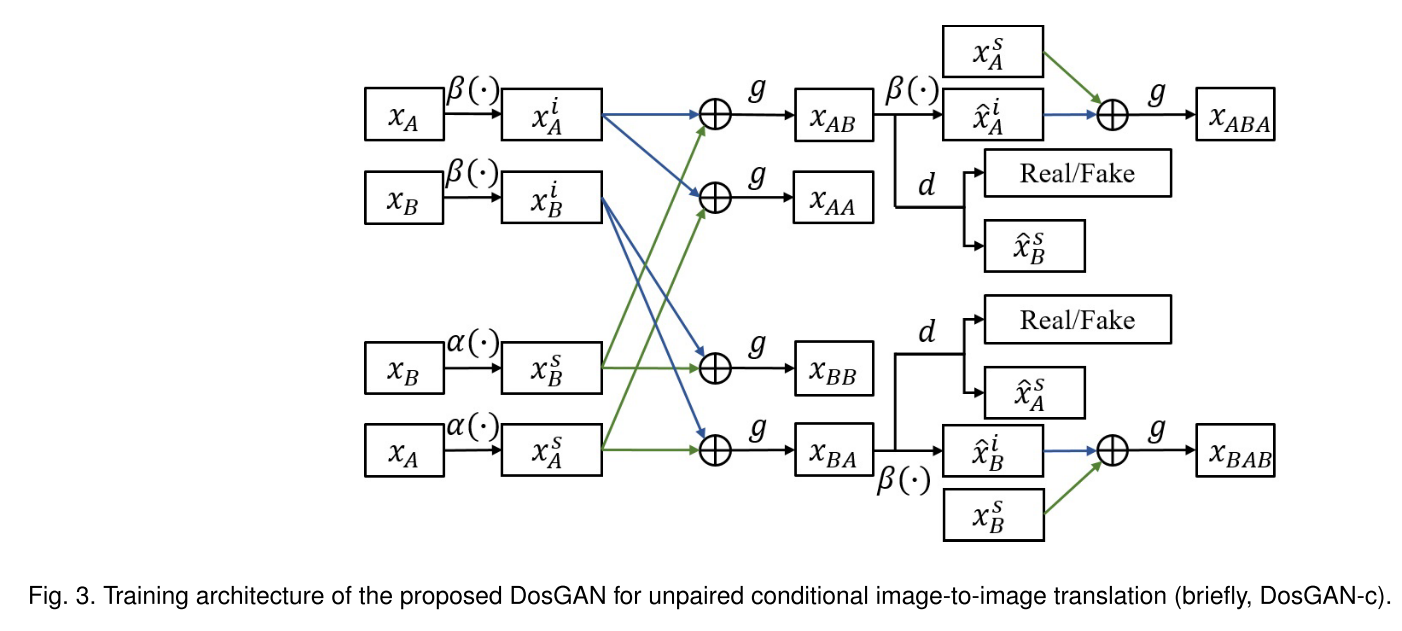
arXiv1902 略读提出DosGAN。Instance-level facial attribute editing。预训练一个Domain分类器,用分类器的倒数第二层作为风格编码。D的条件输出端没有用ACGAN,而是用D预测风格编码作为监督信号。感觉效果一般
来源忘了
-
2019-5-13
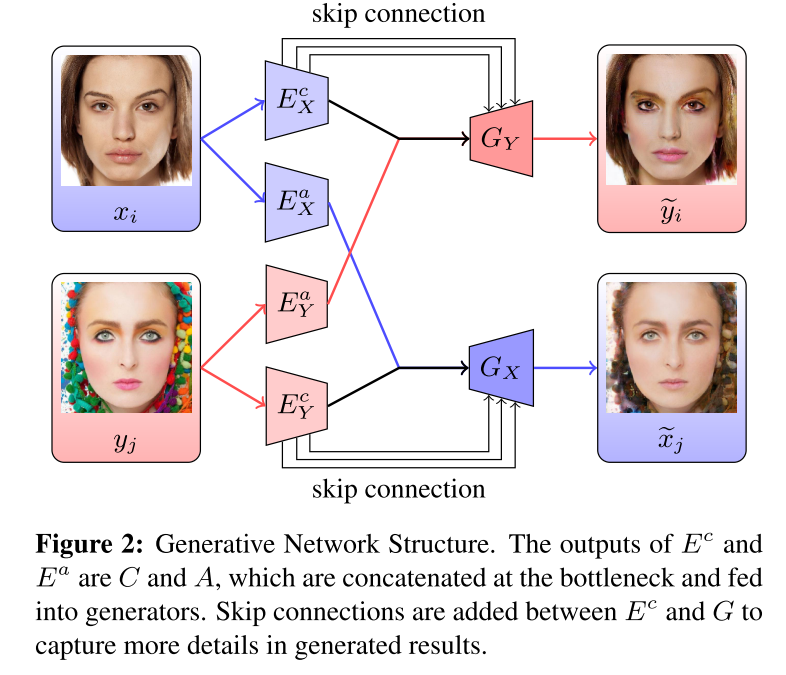
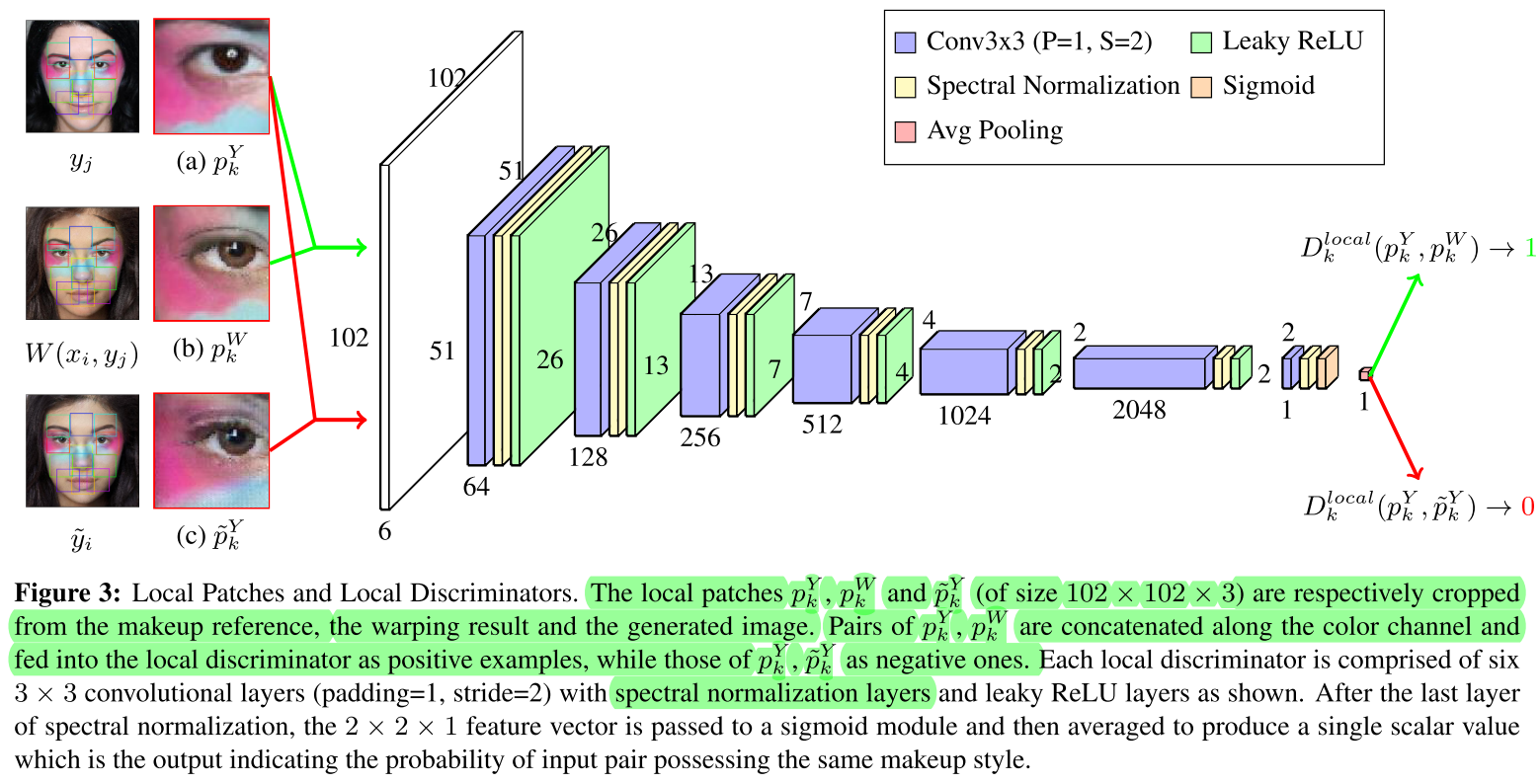
LADN: Local Adversarial Disentangling Network for Facial Makeup and De-Makeup
arXiv1904 略读 提出LADN。Exampler Makeup。content和style分离,用特征点选了几个局部进行Discriminator;用Laplacian Filter进行带权重的不平滑惩罚;并保持生成图片与Warp的伪Ground Truth在Laplacian feature map上一致。用到了SpectralNorm
来源忘了
-
2019-5-13
Homomorphic Latent Space Interpolation for Unpaired Image-to-image Translation
CVPR2019 强烈Mark。 Facelet的续作。可以实现instance level的编辑。也是在特征空间interpolation。作者说训练Encoder时VGG的knowledge guidance loss很有用。还有Homomorphic loss。
同作者找的

-
2019-5-13
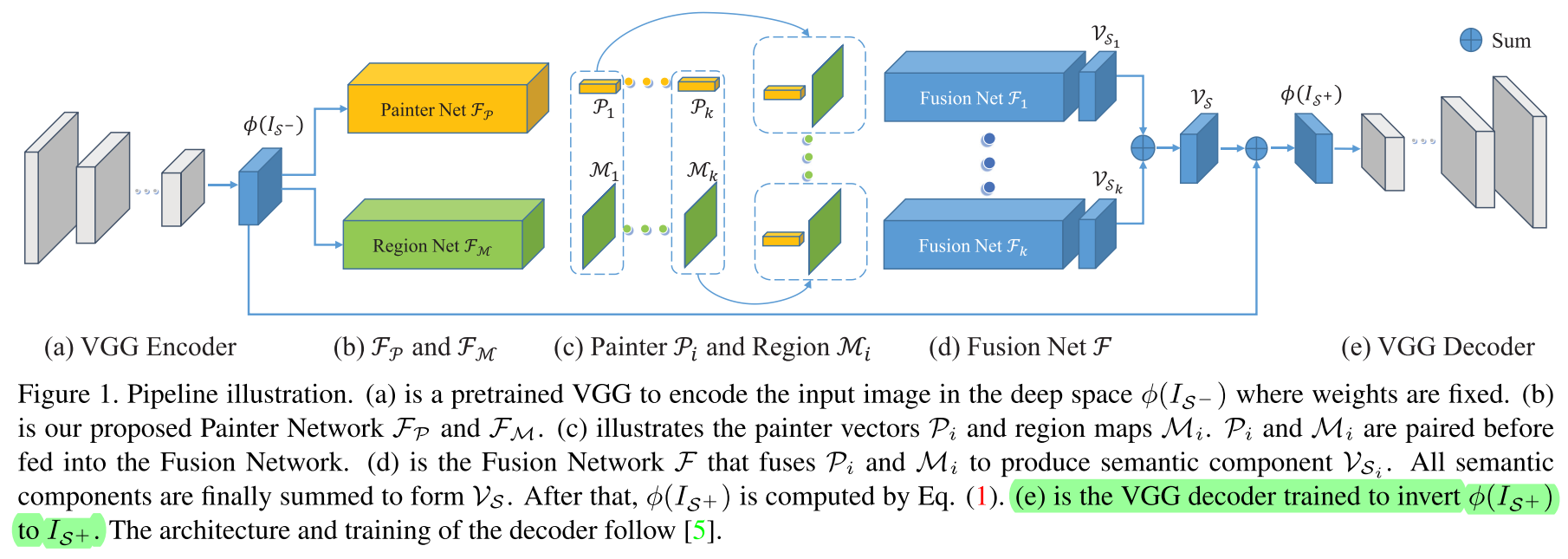
Semantic Component Decomposition for Face Attribute Manipulation
CVPR2019 Facelet的续作。提出SCNet。除了预测9个改变量V外,还预测了9个mask。最后由这些mask*Δ加起来得到最终的改变量。很有想法的文章。resolution448。
来源忘了
-
2019-5-12
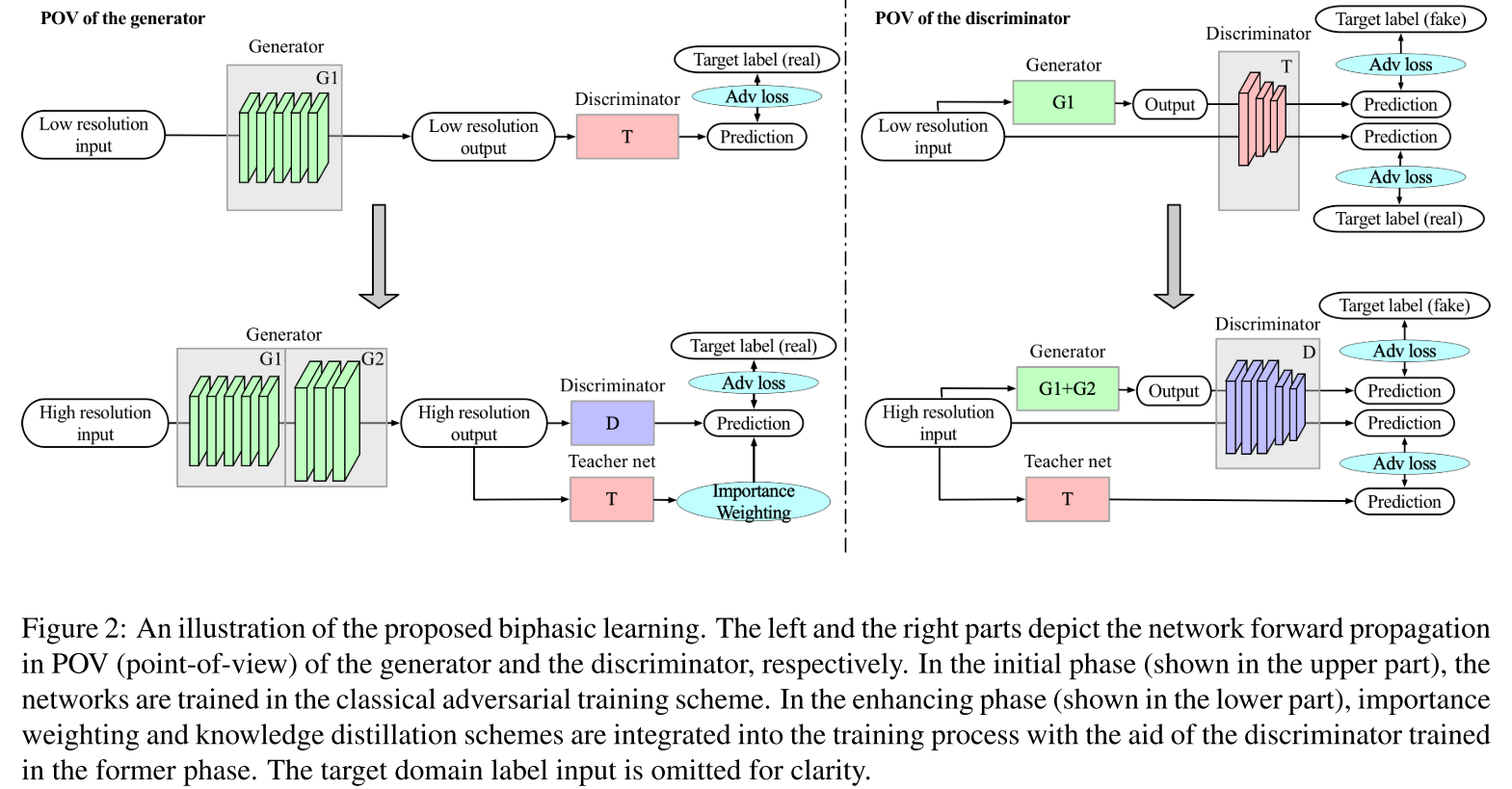
Biphasic Learning of GANs for High-Resolution Image-to-Image Translation
arXiv1904 略读,没有读实验部分。超分辨率编辑。先训低分辨率,teacher discriminator提供权重。LSGAN;ACGAN;Mutual perceptual information;训一个UV预测器,并进行类似ACGAN中分类器那样,保证生成图片的UV被预测的于原图一致。网络结构类似ACGAN,高分辨率时对网络结构进行增添。
He老师的文章
-
2019-5-12
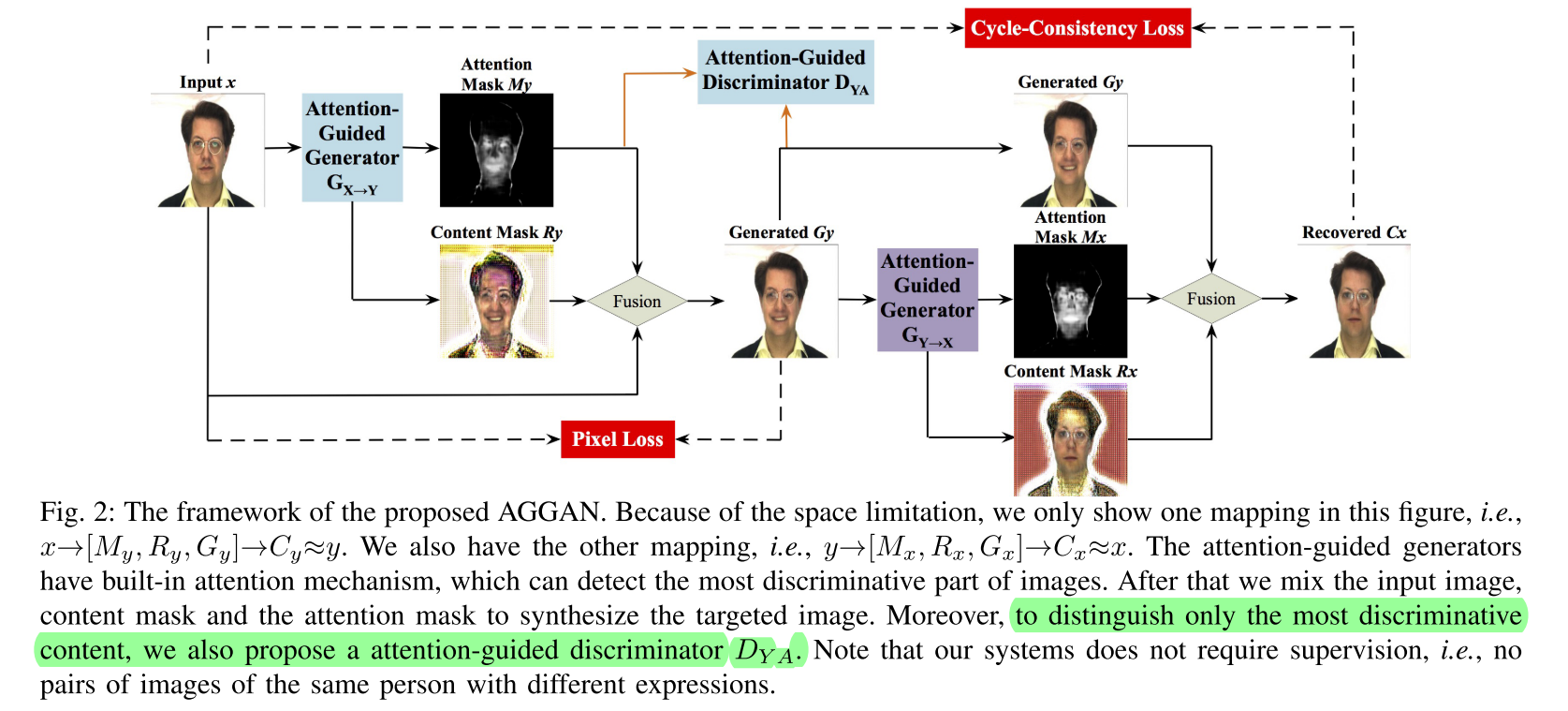
Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation
IJCNN2019 和SAGAN类似,提出AGGAN。multi attribute。在mask上引入total variance;为了限制编辑,约束了编辑后到原图的距离;比较奇怪的是在判别的时候引入了Attention-Guided Discriminator,问题是mask没有对应的ground truth啊,真实样本又没有正确的mask(原文第4页左栏)。看Ablation Study也不明显
来源忘了
-
2019-5-12
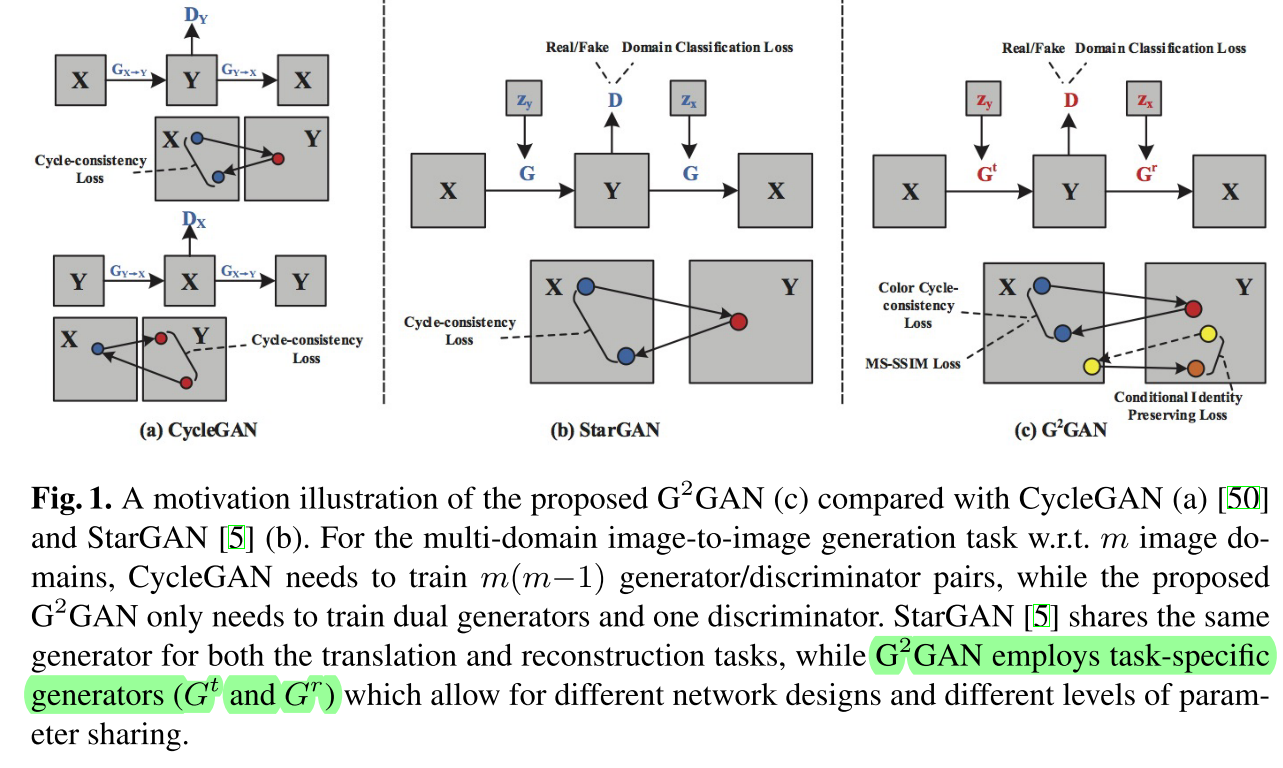
Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
ACCV2018 和StarGAN类似,提出 G 2 G A N G^2GAN G2GAN。有几点很奇怪:生成和rec用了两个不同的G;提出了color consistency loss,不知道和传统L1有啥区别。用SSIM惩罚dual rec。Conditional Id Preserving Loss其实就是id rec。
来源忘了
-
2019-5-12
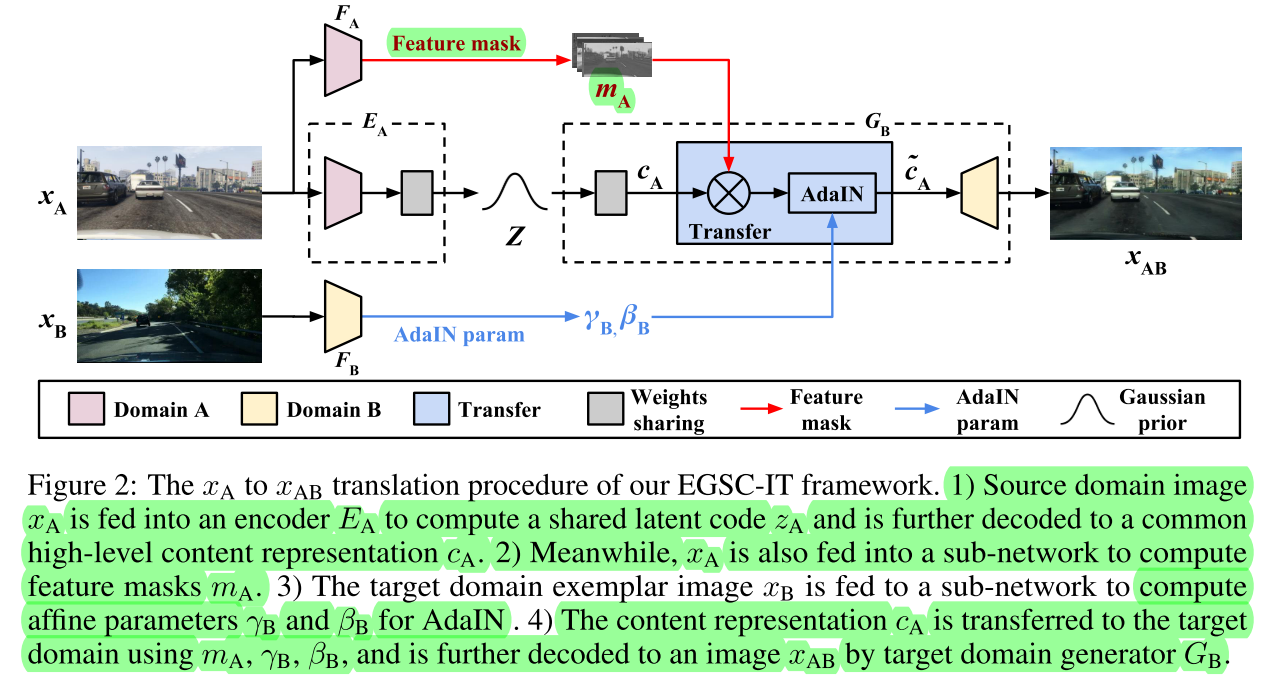
Exemplar Guided Unsupervised Image-to-Image Translation with Semantic Consistency
ICLR2019 Image Translation with style guider. 和MUNIT在一个任务下,Instance-level。 EGSC-IT (也简称EG-UNIT)
AdaIn+Attention. AdaIn+Attention。Feature Mask解出Spatial Attention。 x A x_A xA经过 E A E_A EA应该最终被解到一个先验分布上。(1) E A E_A EA和 G A G_A GA组成一对VAE约束,同时给上往另一个域转得GAN的约束。两个域对偶重构约束(应该是这样,看的比较含糊,看上去是一个UNIT)。(2)另外约束了转域时的perceptual loss和gram 矩阵,实现style transfer的约束。(3)mask和adain组到一块去了,比较神奇。
网站查到


-
2019-5-11
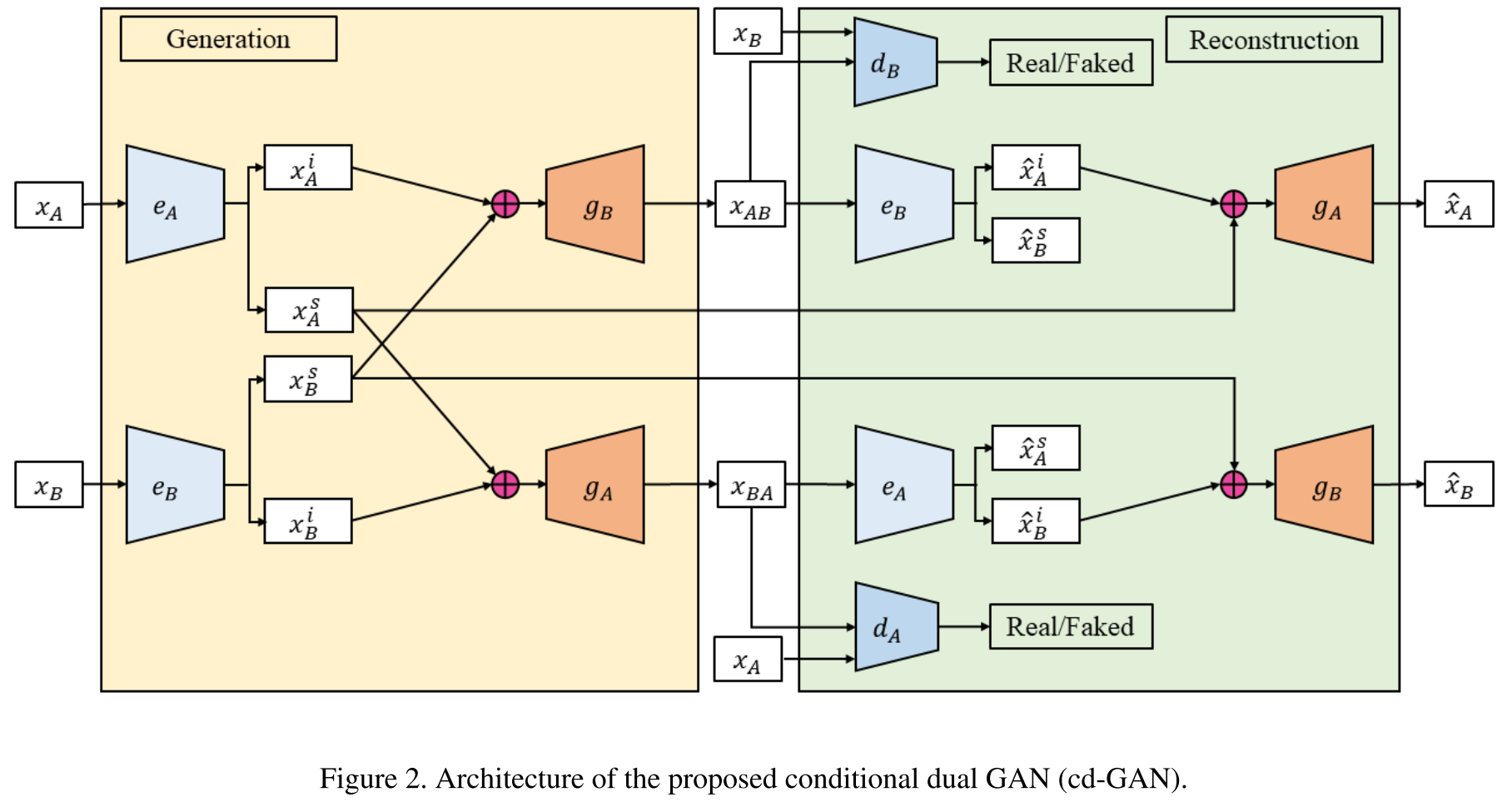
Conditional Image-to-Image Translation
CVPR2018 instance level editing. 提出cd-GAN,和Kim那篇非常像,但是两个域都做了交叉交换。而且independent vector和style vector都进行了重构。dual rec的时候用原图的independent vector进行重构,没有用第二次解出来的做交换。图像分辨率64.(这样做的问题是,会不会信息全部跑到i当中,s为一个定值;而且从实验结果看会改变背景)
来源忘了

-
2019-5-11
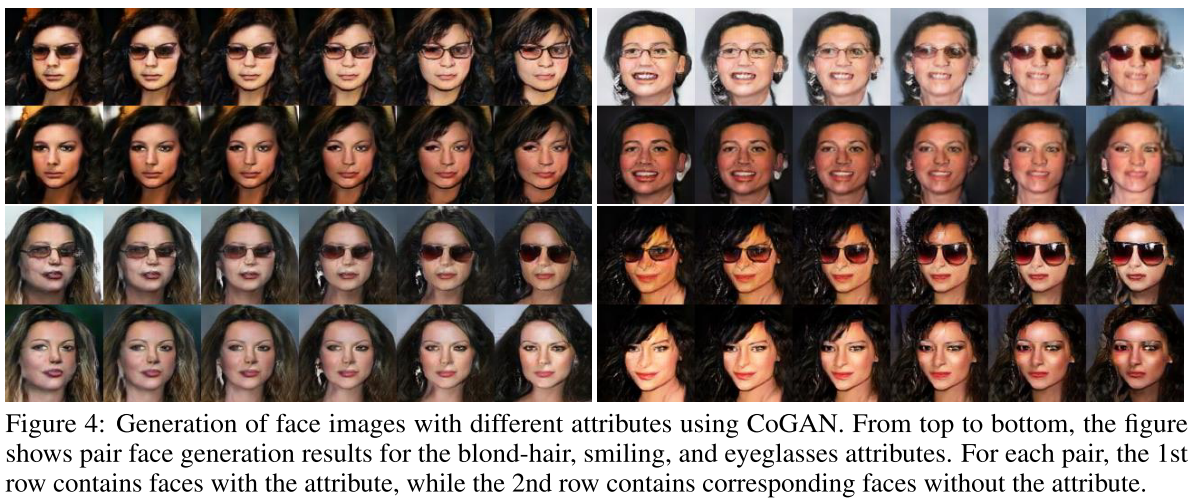
Coupled Generative Adversarial Networks
NIPS2016 multi modal生成。用一个的noise生成两个不同域的图片(例如一个戴眼镜的和一个不带眼镜的,其他一致)。共享G的前层参数和D的后层参数。D末引入一个分类softmax后也可以做domain adaptation。
经典文章

-
2019-5-11
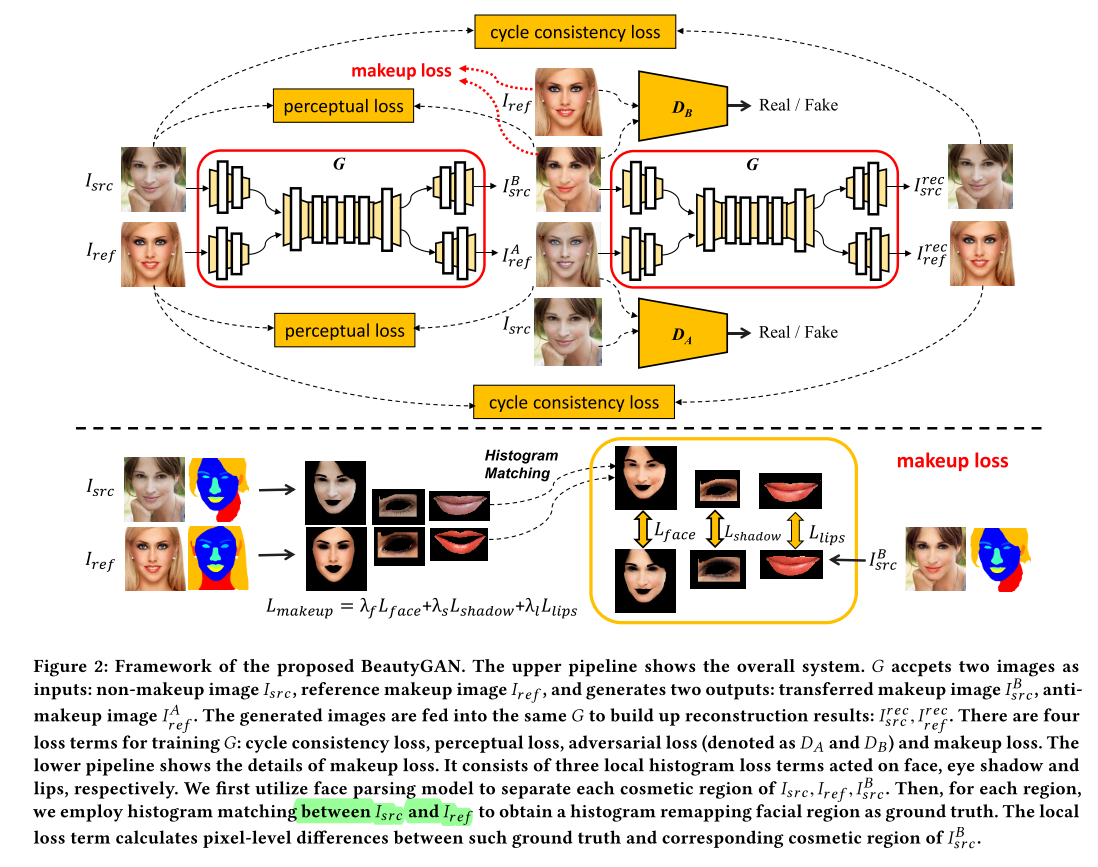
BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network
MM2018 Makeup 依据示例图片的lipstick, eye shadow, face进行指导。Perceptual Loss保持身份,Adversarial Loss保持真实,dual rec重构。用原图与ref图片进行局部histogram matching后的结果,作为风格特征的ground truth引入风格loss。
Learning to discover cross-domain relations with generative adversarial networks被引

-
2019-5-10
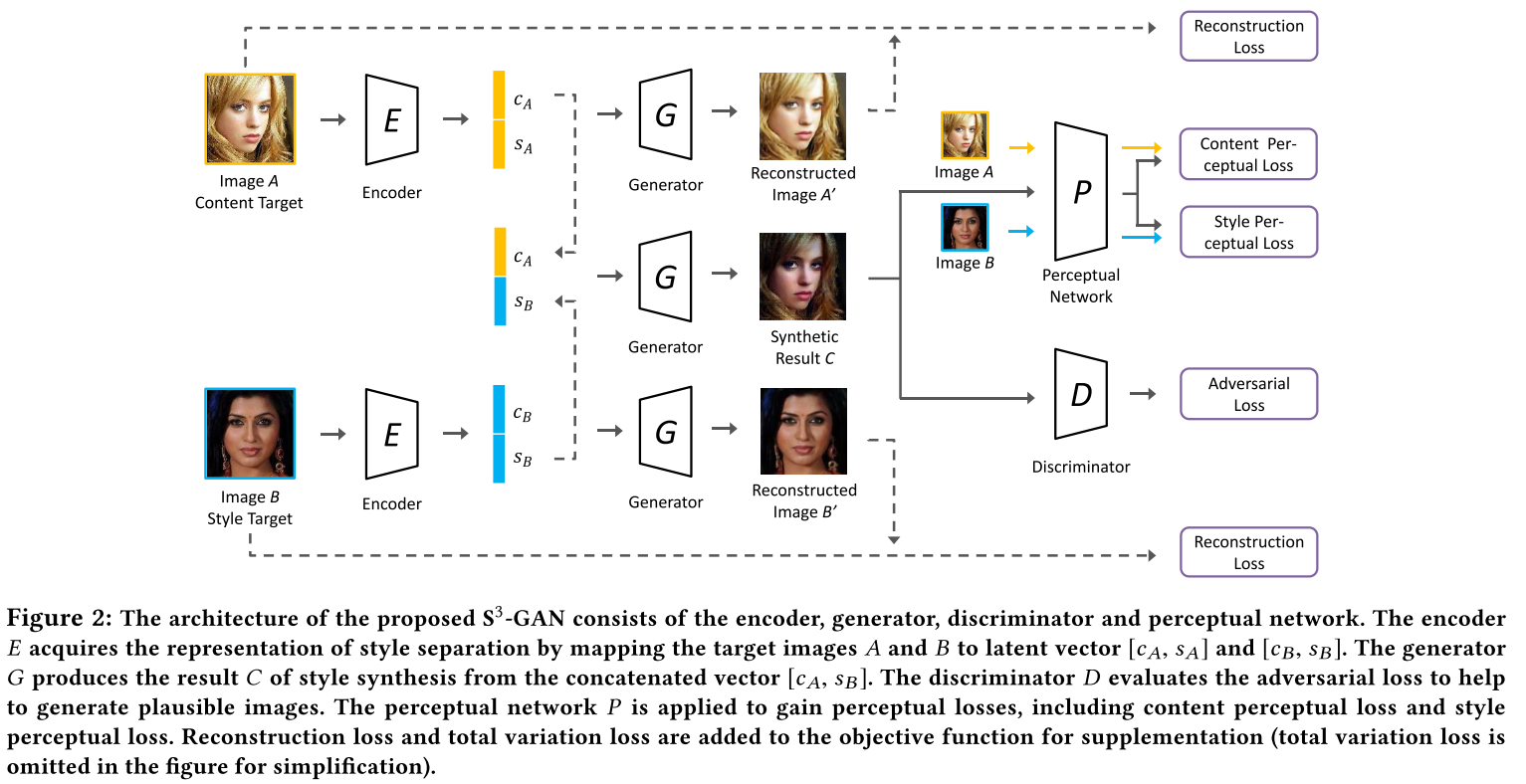
Style Separation and Synthesis via Generative Adversarial Networks
MM2018 Style和Content分离,属性无关。用Perceptual loss和Gram分别约束content和style。Encoder出half style vector和half content vector。Reconstruction+Adversarial+TotalVariance
GeneGAN被引
-
2019-5-07
A Closed Form Solution to Natural Image Matting
CVPR2008 (没看完和懂!!!)Mattin Laplacian分割,利用局部窗口线性最小二乘。依据一个小的guide区分前景背景。
Deep Photo Style Transfer和Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary用到。

-
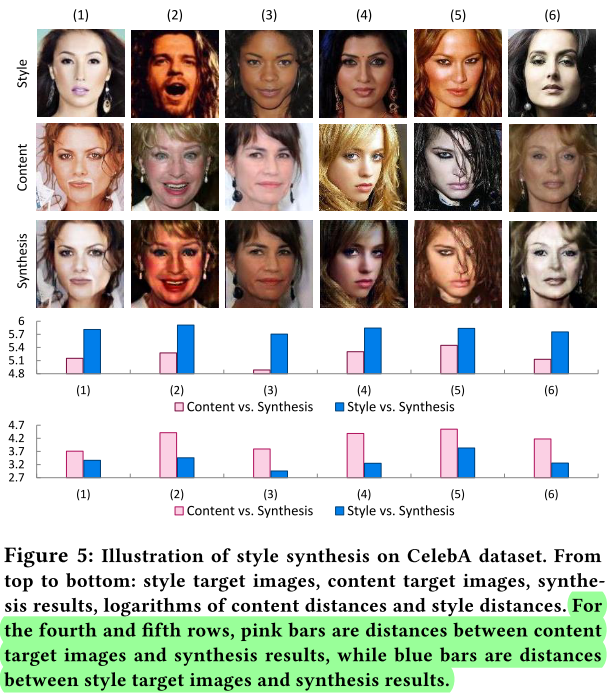
2019-5-05
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
arXiv1801 提出了LPIPS相似性评估指标,一种用2AFC(2 alternative forced choice)和JND(just noticeable difference)作为label的数据集训练的channel weighted的perceptual loss. 提出了一个新数据集。
BicycleGAN被引.
-
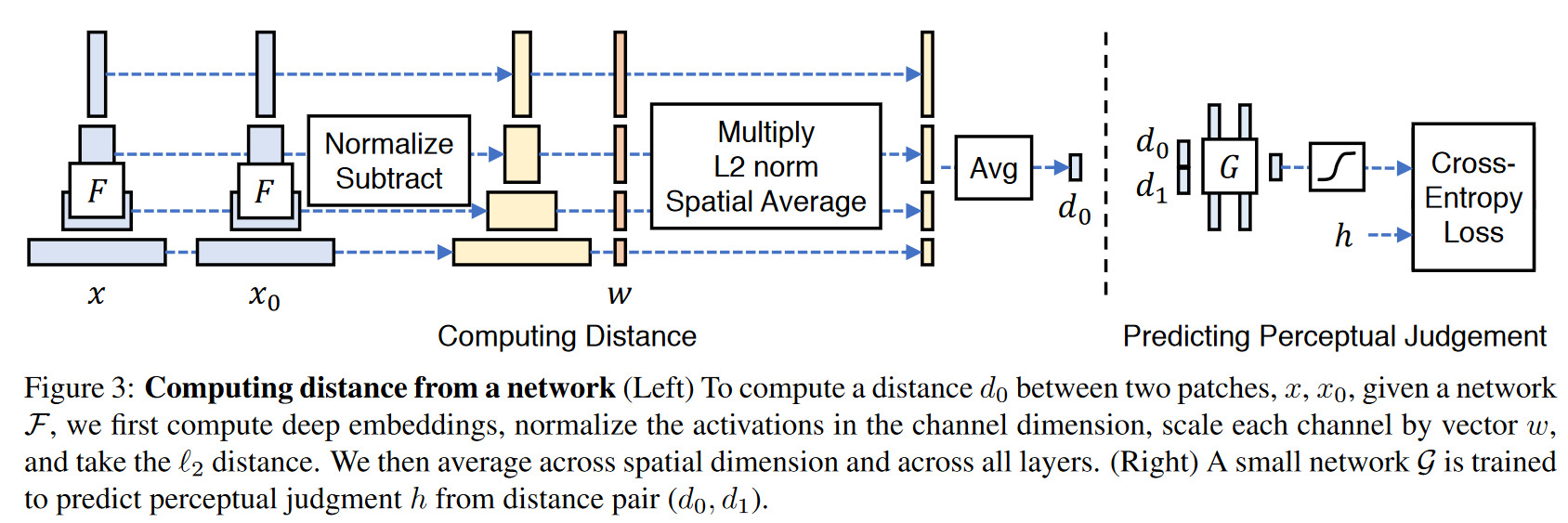
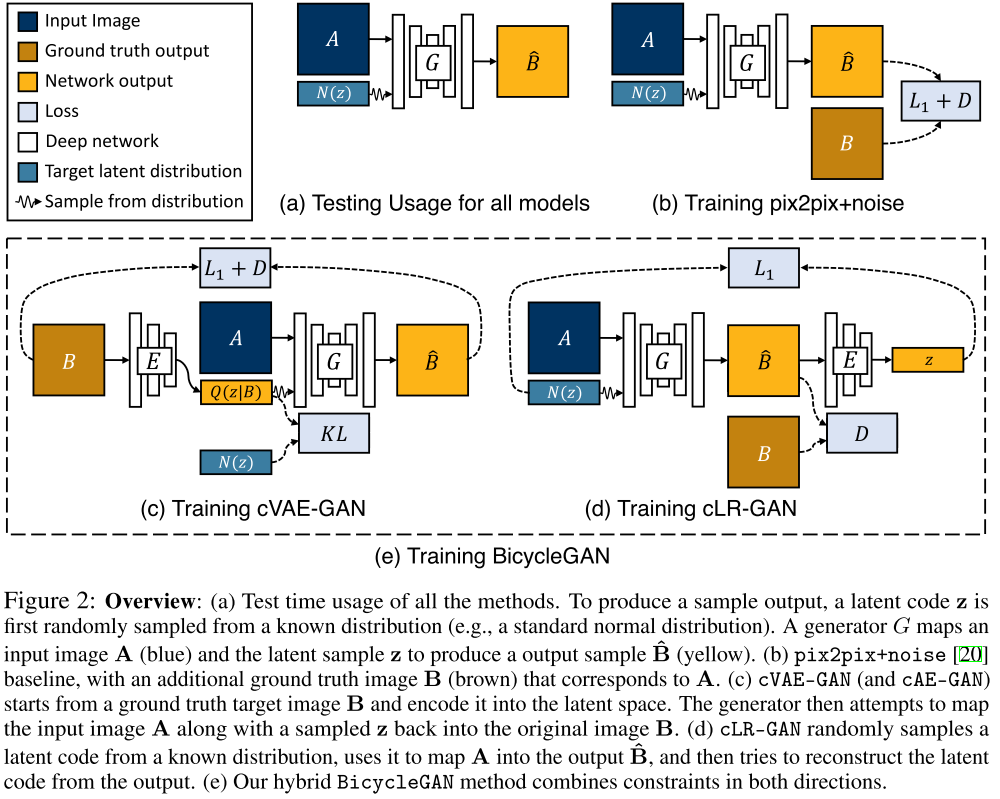
2019-5-03
Toward Multimodal Image-to-Image Translation
NIPS2017 BicycleGAN. paired translation. 一张A域图片转换成多张B域图片。结合VAE-GAN和InfoGAN。(VAE-GAN看上去像是两个对偶的感觉,能不能把VAE-GAN用在我的想法里?)
Attribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning被引,经典文章
-
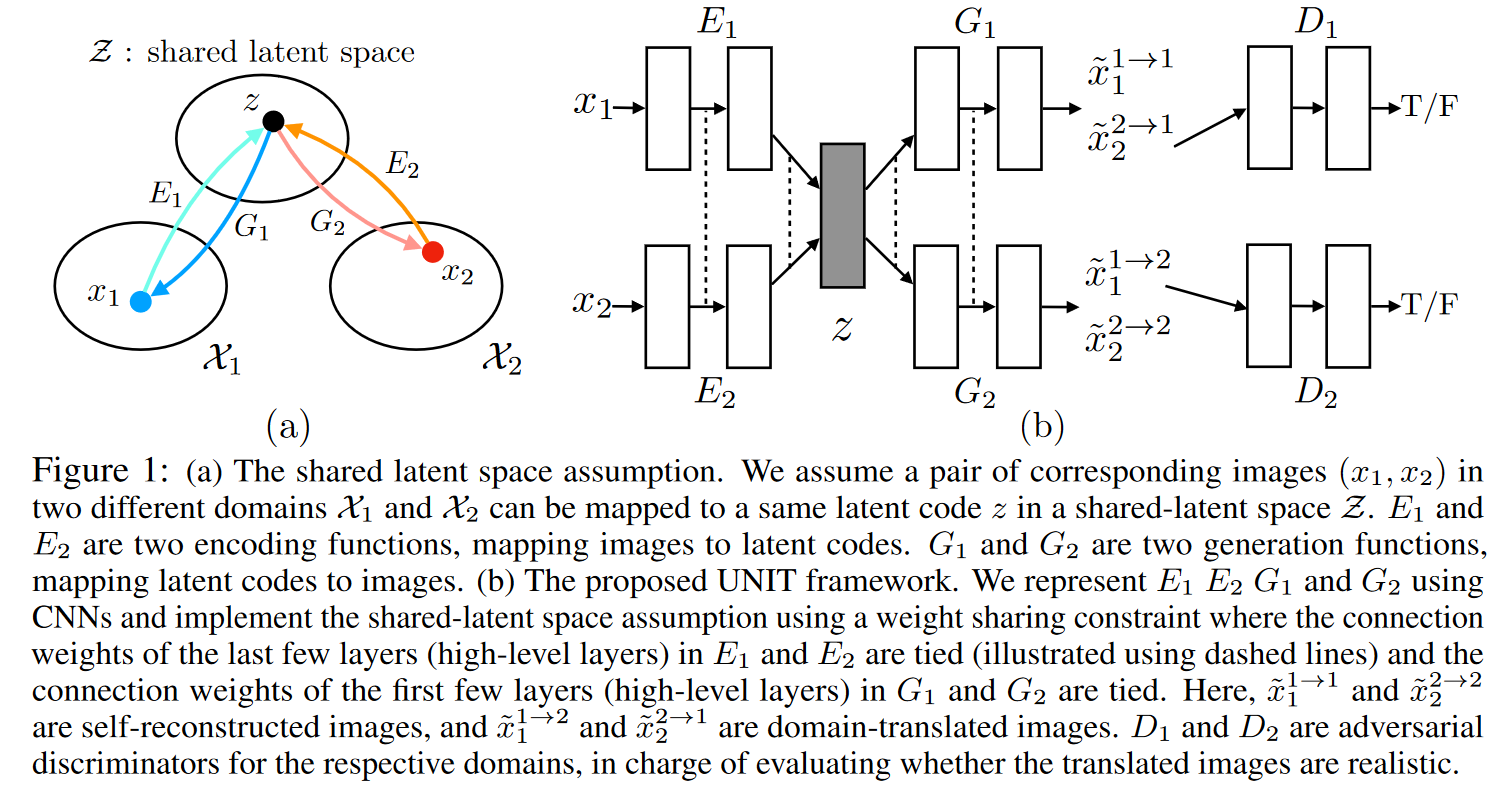
2019-5-02
Unsupervised Image-to-Image Translation Networks
NIPS2017 unpaired translation. 两个Encoder和两个Generator组成两套VAE,两个D和Generator组成GAN。映射到一个隐空间Z。Dual Reconstruction。两个E和G之间浅层参数共享。
MUNIT的前置
-
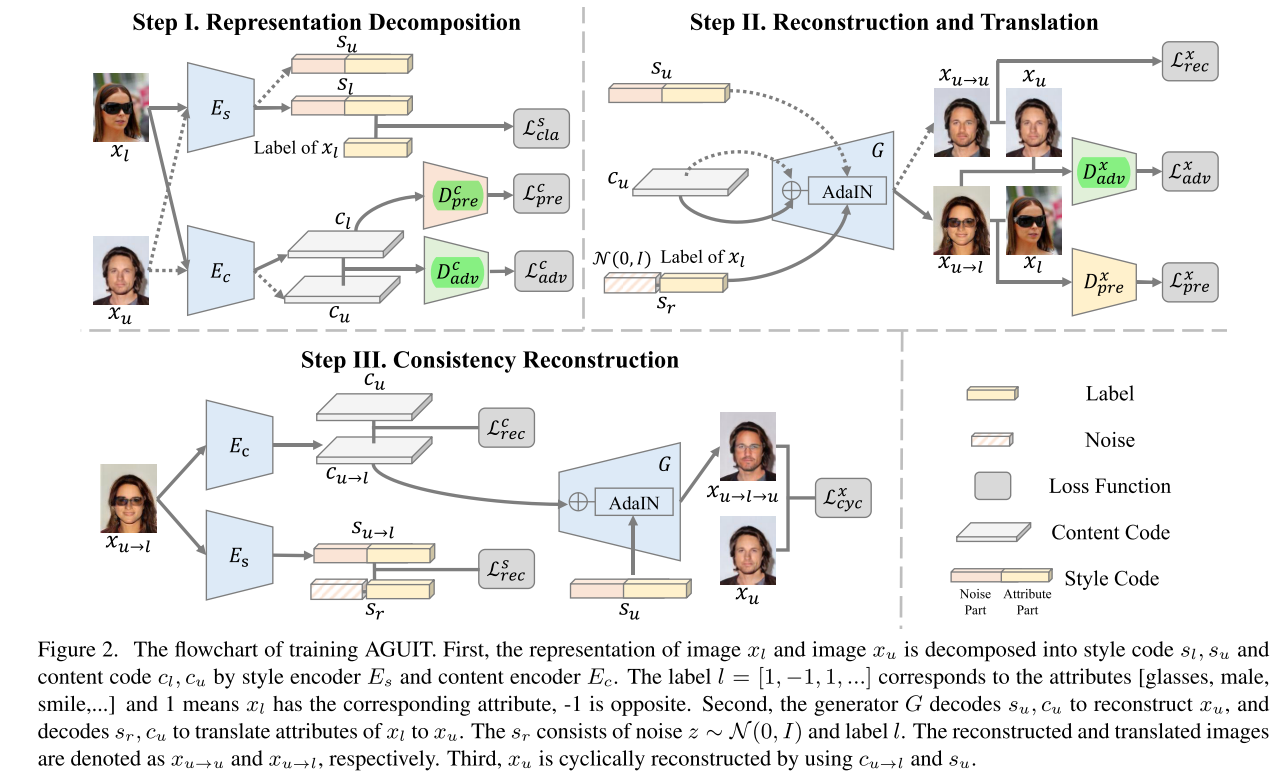
2019-5-02
Attribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning
arXiv1904 半监督人脸编辑;把unlabel的图片用于adv训练和原图进行生成。解绑content和style,content和style之间用FaderNetwork解绑;生成器使用AdaIn。(感觉这个方法贼绕)
He师兄推荐
-
2019-4-25
Deep Photo Style Transfer
CVPR2017 realistic style transfer,经典文章。在Gatys的基础上,引入Matting Laplacian正则使得输入到输出的transformation在局部颜色空间映射(需要细看Matting Laplacian原文);用Mask之后的原图和风格图算Gram Loss,使得对应语义内容进行风格迁移。
STGAN中Matting Laplacian内容被引

-
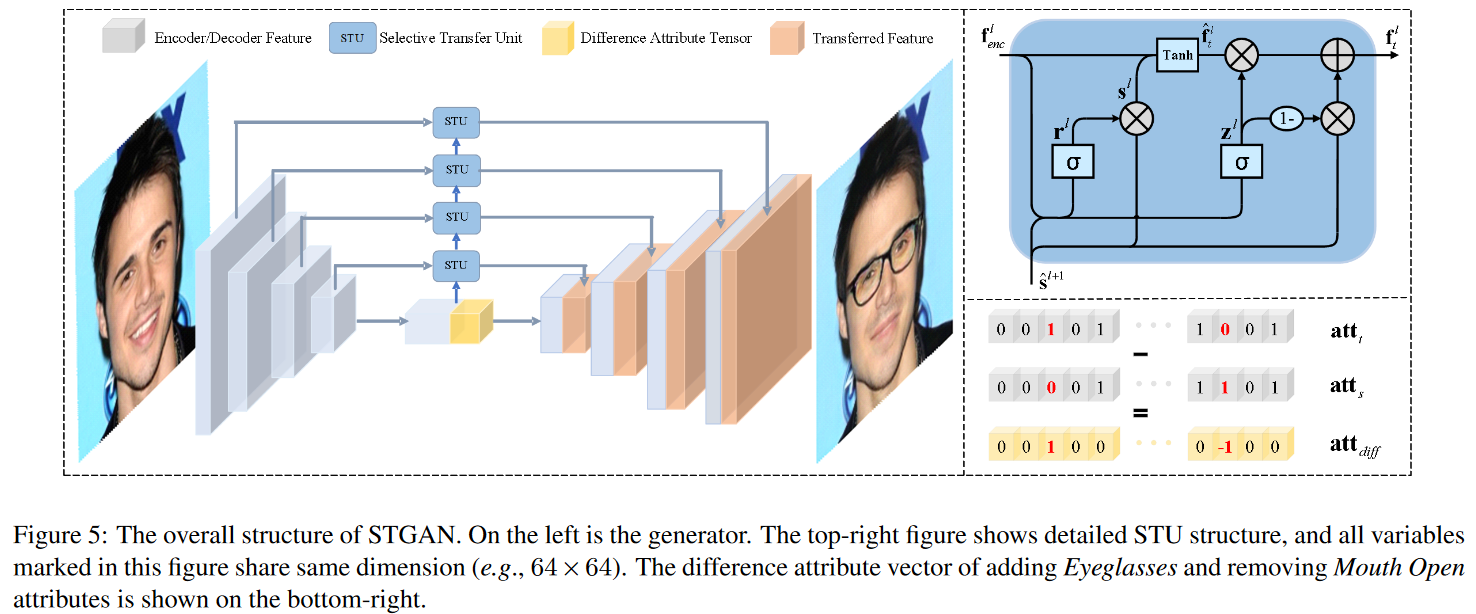
2019-4-23
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
CVPR2019 Multi semantic level facial attribute editing. 在u-net中利用gru改进后的STU单元,实现可控skip connect。结构类似attgan。bald效果好。
AttGAN He师兄推荐
-
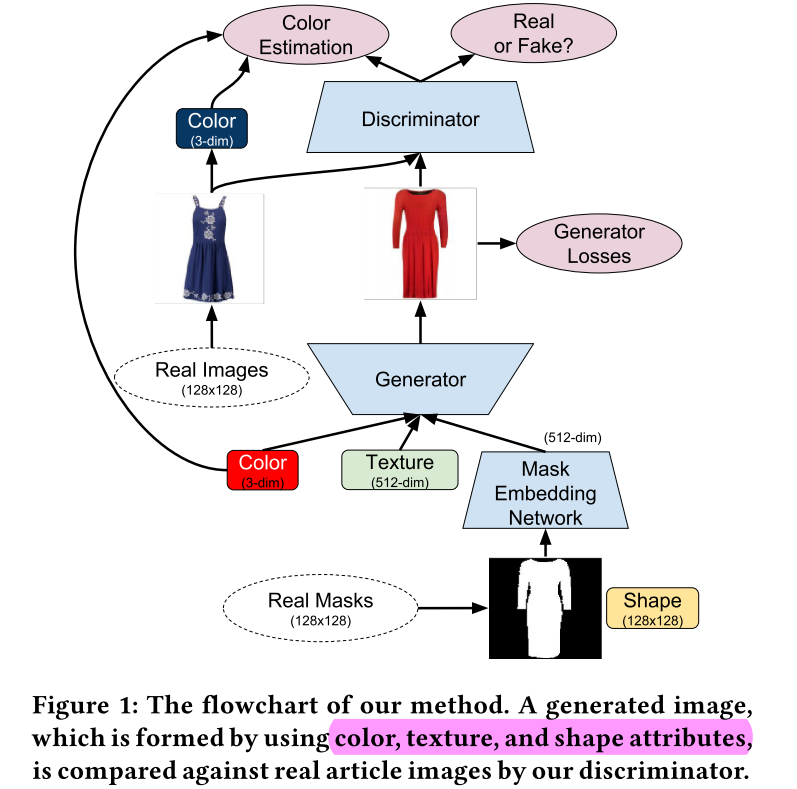
2019-4-22
Disentangling Multiple Conditional Inputs in GANs
KDD2018 workshop 服装生成,解绑颜色、形状、纹理。这里纹理为手工Matting Laplacian特征
DNA-GAN被引
-
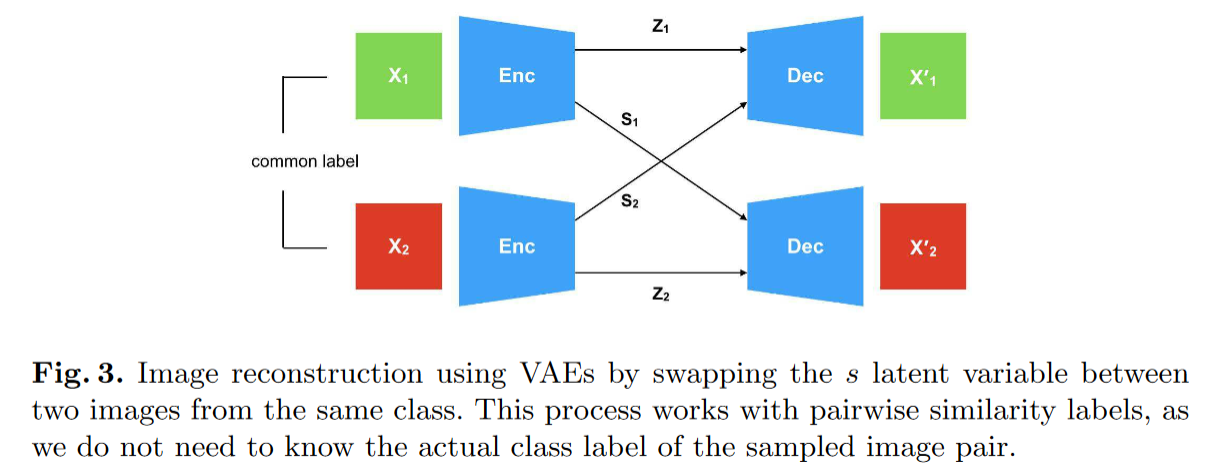
2019-4-19
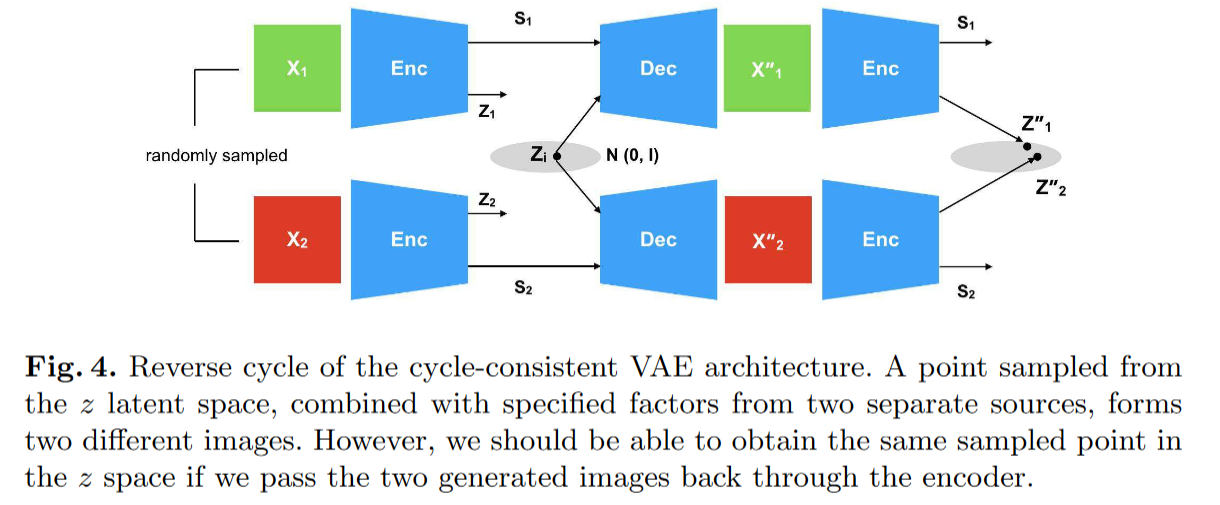
Disentangling Factors of Variation with Cycle-Consistent Variational Auto-Encoders
ECCV2018 学习解绑VAE,x和z都有cycle,将生成的同类别变量s进行交换,保持原图。不明白为什么不直接优化同类别两个s之间的距离,以及这样会不会信息全部跑到z中去?
DNA-GAN被引
-
2019-4-18
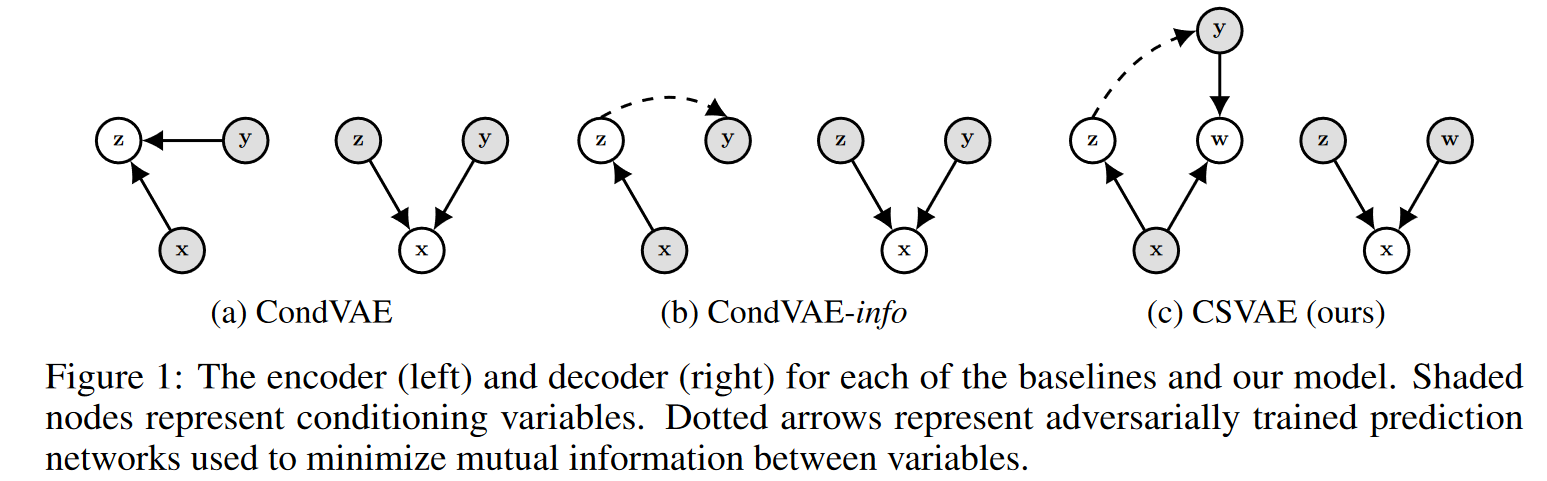
Learning Latent Subspaces inVariational Autoencoders
NIPS2018 形式化非常漂亮。用类似VAE的变分推断方式优化x、y出现的概率。可以用于生成多风格。(有的形式化没看懂,要是有代码就好了)
ELEGANT的被引

-
2019-4-16
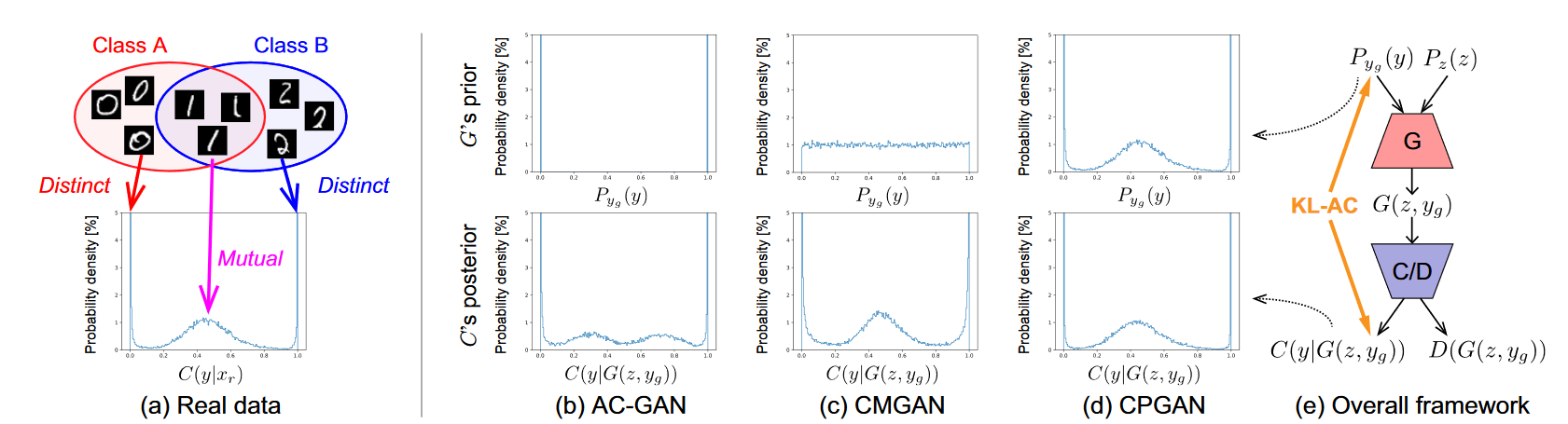
Class-Distinct and Class-Mutual Image Generation with GANs
arXiv1811 提出新问题,穿插于类别标签中的真实类,如何进行生成。改进ACGAN的输入采样方式,利用ACGAN求输入、输出(y的给定数据集标签下的后验)之间的KL散度优化生成器的生成分布。
dtlc-gan的近期自引
-
2019-4-15
Spectral Normalization for Generative Adversarial Networks
ICLR2018 WGAN-GP的改进 深入层中,对层的参数矩阵求最大特征值,找最大的梯度可能进行惩罚 原文指出该方法易于实现 (没太看懂,太偏理论)
Label-Noise Robust Generative Adversarial Networks一文中发现该方法 -
2019-4-15
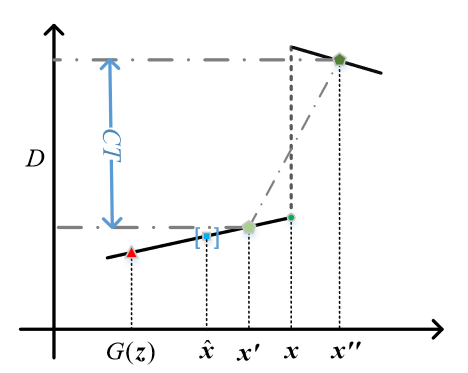
Improving the improved training of Wasserstein GANs: A consistencyterm and its dual effect
ICLR2018 CTGAN WGAN-GP的改进 探测真实样本附近的两点斜率
Label-Noise Robust Generative Adversarial Networks一文中发现该方法
-
2019-4-12
Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN、
ACPR2017 漫画上色 U-net存在问题,容易短路 所以用两个decoder进行指导
结构图画的漂亮、内容有趣

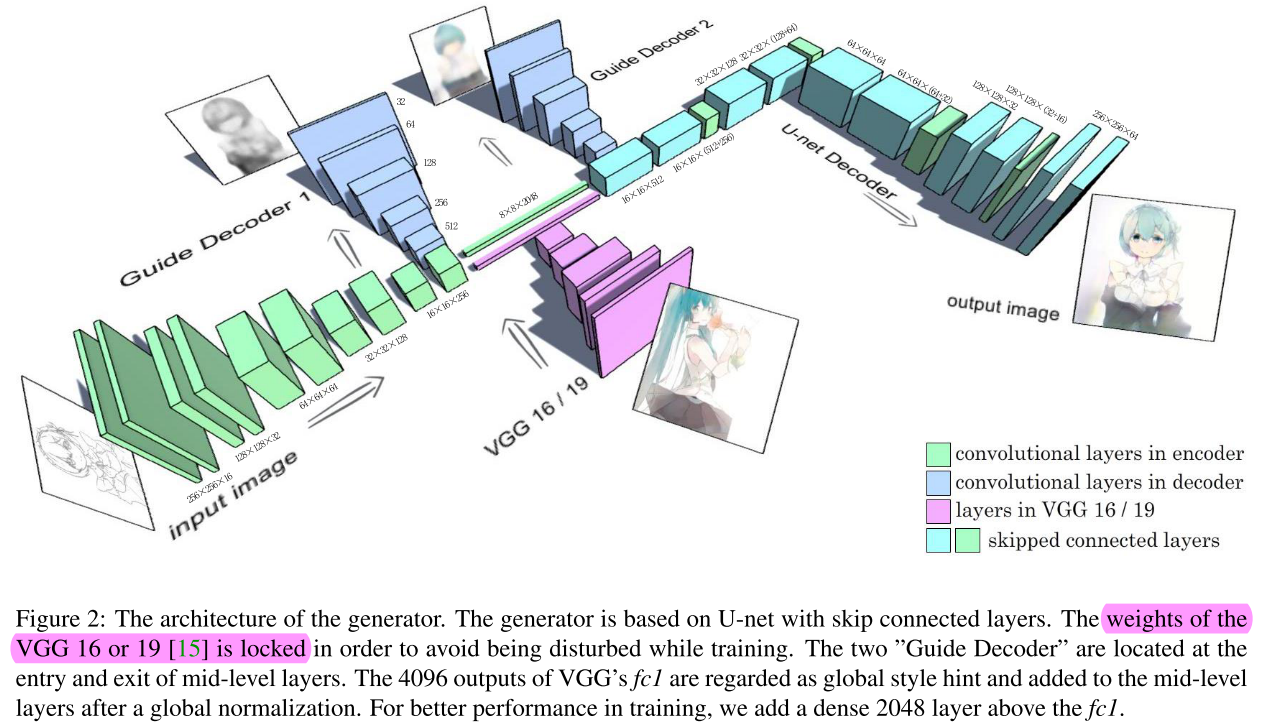
-
2019-4-12
Label-Noise Robust Generative Adversarial Networks
arXiv1811 类别标记有误的条件生成 cGAN和AC-GAN连接类别转移矩阵
dtlc-gan的近期自引
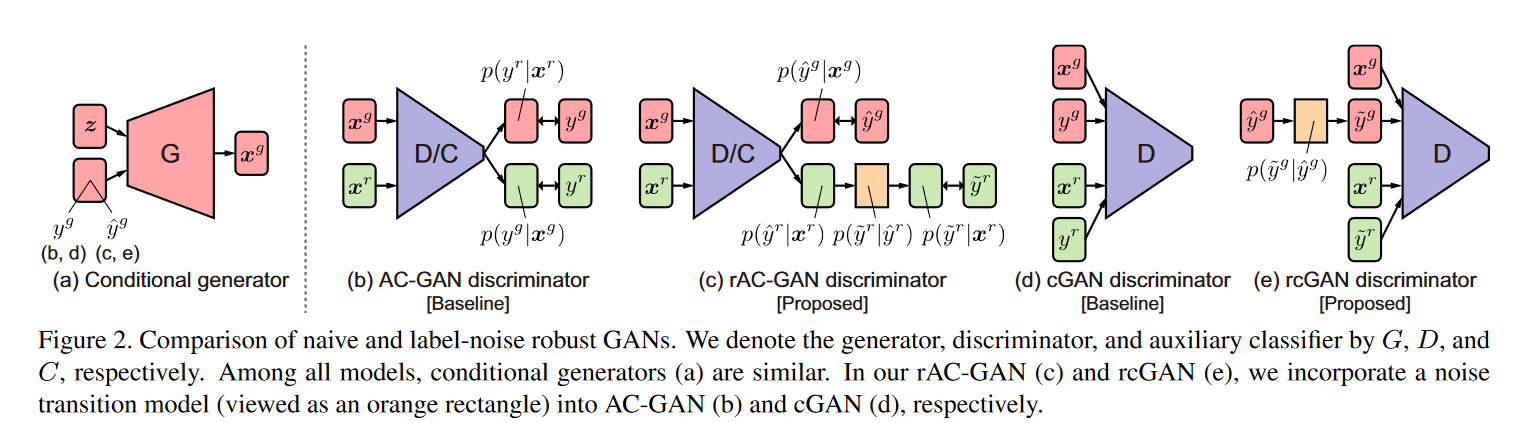
-
2019-4-11
Learning compositional visual concepts with mutual consistency
CVPR 2018 cycle-gan的扩展
CFGAN的被引
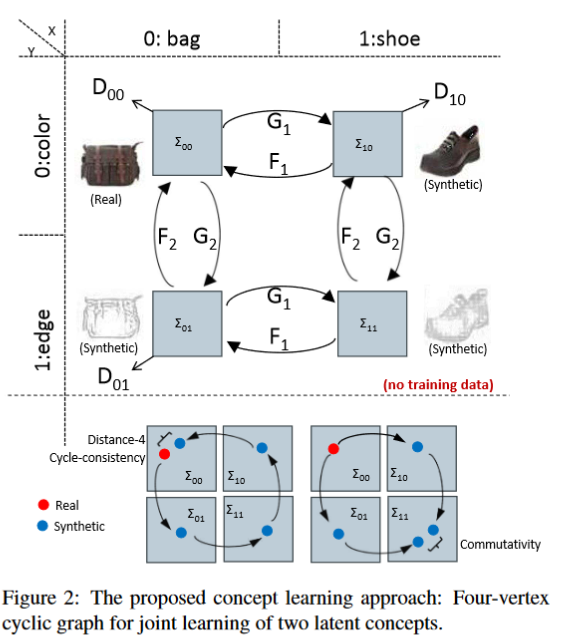
-
2019-4-10
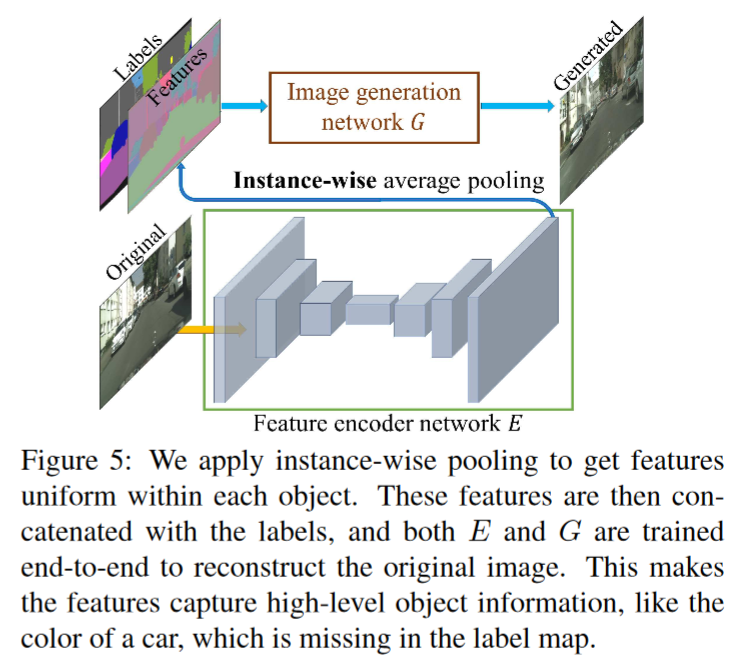
High-resolution image synthesis and semantic manipulation with conditional gans
CVPR 2018 层级结构 高分辨率图像生成 能修改其中instance的风格
CFGAN的被引
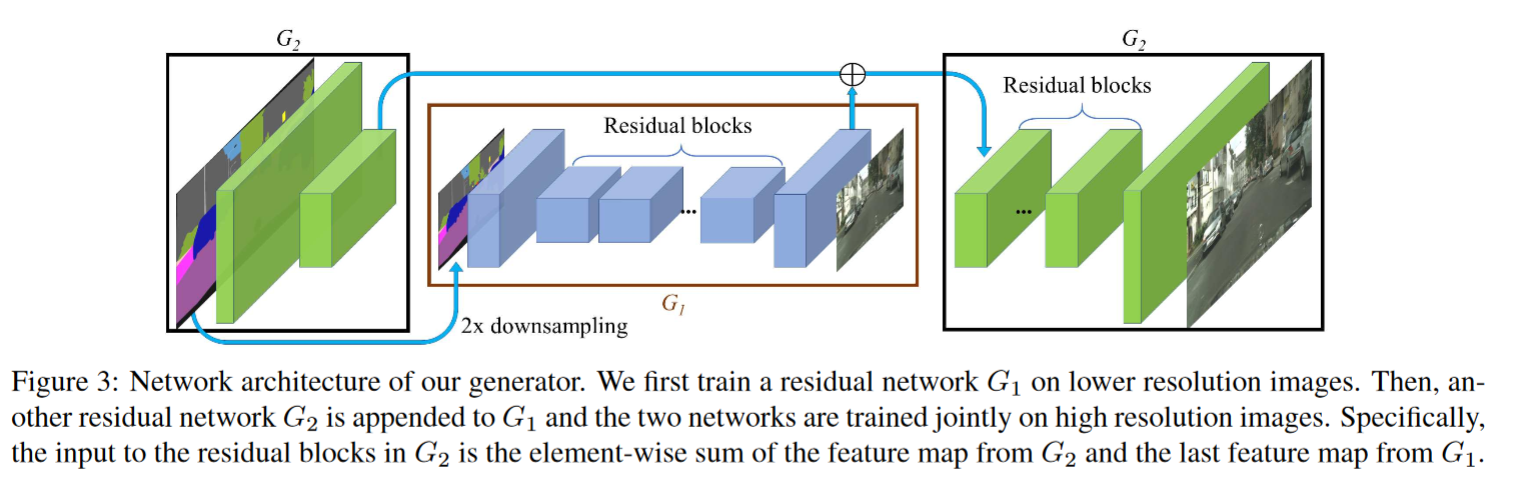
最后
以上就是文艺大炮最近收集整理的关于论文阅读记录 1-50篇 20190410-20200316的全部内容,更多相关论文阅读记录内容请搜索靠谱客的其他文章。








发表评论 取消回复