基本概念
攻击方法分类标准:
假正性攻击(false positive)与伪负性攻击(false negative)
- 假正性攻击:原本是错误的但被被攻击模型识别为正例的攻击(eg: 一张人类不可识别的图像,被DNN以高置信度分类为某一类);
- 伪负性攻击:原本应该被正常识别但被被攻击模型识别错误的攻击(eg: 原本能够被正确的样本,在遭到对抗攻击后,被攻击模型无法对其正确分类)。ps: 我现在做的遇到的大部分攻击算法都是伪负性攻击算法。
白盒攻击(white box)与黑盒攻击(black box):
- 被攻击模型的模型参数可以被获取的被称为白盒攻击;
- 模型参数不可见的被称为黑盒攻击。
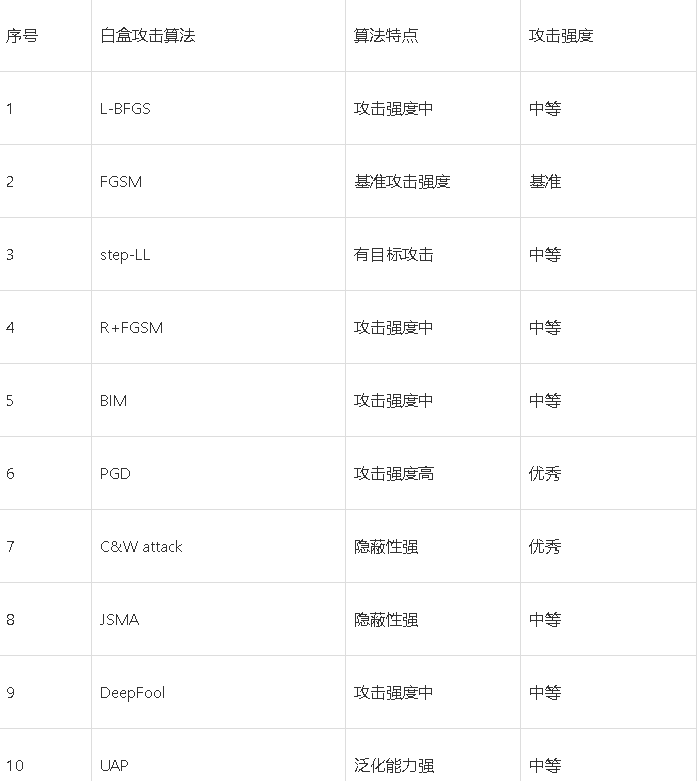
有目标攻击(target attack)和无目标攻击(non-target attack):
- 有目标攻击:期望对抗样本被定向误识别为某一特定类别;
- 无目标攻击:仅仅希望对抗样本不能被识别的而没有指定目标类别。
单步攻击(One-time attack)和迭代攻击(Iteration attack):
- 最典型的就是之前实现过过的FGSM([2])
- I-FGSM([3])
个体攻击(Individual attack)和普适性攻击(Universal attack):
- 个体攻击向每个样本添加不同的扰动,大多数攻击方法都属于个体攻击(典型算法可见[4],[5]);
- 普适性攻击训练一个整个数据集通用的扰动。
优化扰动(optimized perturbation)和约束扰动(constrained perturbation):
- 优化扰动表示扰动大小作为优化过程中的优化目标(典型算法算法可参考[6]),C&W攻击(白盒攻击)算法是一种基于迭代优化的低扰动对抗样本生成算法。该算法设计了一个损失函数,它在对抗样本中有较小的值,但在原始样本中有较大的值,因此通过最小化该损失函数即可搜寻到对抗样本;
- 约束扰动表示所添加扰动仅需满足约束即可。
数据集和被攻击模型:
- 目前该领域最常用的数据集为MNIST, CIFAR 和ImageNet;
- 最常用的被攻击模型为LeNet, VGG, AlexNet,GoogLeNet, CaffeNet, and ResNet等
优化算法(Zeroth-Order Optimization)
该算法是一个典型的黑盒攻击算法,它采用对称伤差来估测海森矩阵和梯度,不需要获取目标模型的梯度信息
模型输入:需要input+每一个类别的概率
模型的训练:
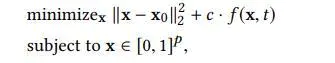
损失函数如上,左边保证对抗样本与真实input的相似,右边保证对抗样本能导致目标模型出错,具体如下:
-
目标
- 有目标攻击:
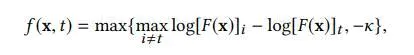
- 无目标攻击
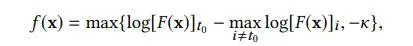
- 有目标攻击:
-
DNN model,如果目标model的数据集类似mnist,图片较小,就不会使用到attack-space hierarchical attack importance sampling
- attack-space :计算梯度时的坐标选取范围变小 (299x299x3->32x32x3)
- hierarchical attack:与上面的相反,小范围的坐标选取可能会没 有效果(32x32x3->64x64x3)
- importance sampling:有时经过了attack-space,坐标范围还是非 常的大,此时就需要根据坐标的重要性进行 选取(一般认为,图片中间位置的像素较边 角的重要)
-
随机选取一个坐标
-
估计梯度, h h h非常小, e i ei ei是一个只有i-th元素等于1的偏置向量。第二个只在牛顿法中才会使用。
- loss function (一阶和二阶)
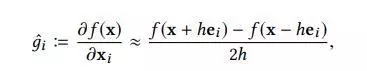
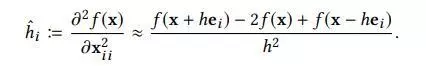
- loss function (一阶和二阶)
-
获得了上面的近似梯度后,利用一阶或二阶方法(如下红框内的adam方法和newton method)来获取best梯度
- ZO Adam

- ZO Adam
https://zhuanlan.zhihu.com/p/57733228
参考文献
[1] Yuan, Xiaoyong, et al. "Adversarial examples: Attacks and defenses for deep learning."IEEE transactions on neural networks and learning systems(2019).
[2] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
[3] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199.
[4] Moosavi Dezfooli S M, Fawzi A, Frossard P. Deepfool: a simple and accurate method to fool deep neural networks//Proceedings of 2016 IEEE Conference on Comput
[5]Moosavi-Dezfooli, S. M., Fawzi, A., Fawzi, O., & Frossard, P. (2017). Universal adversarial perturbations.arXiv preprint.er Vision and Pattern Recognition (CVPR). 2016 (EPFL-CONF-218057).
[6] Carlini, Nicholas, and David Wagner. “Towards evaluating the robustness of neural networks.” Security and Privacy (SP), 2017 IEEE Symposium on. IEEE, 2017.
[7] A. Rozsa, E. M. Rudd, and T. E. Boult, “Adversarial diversity and hard positive generation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) Workshops, Jun. 2016, pp. 25–32.
最后
以上就是能干眼睛最近收集整理的关于white/black-box attack(黑盒白盒攻击基础)基本概念优化算法(Zeroth-Order Optimization)的全部内容,更多相关white/black-box内容请搜索靠谱客的其他文章。








发表评论 取消回复