目录
摘要:
1.Introduction
2. Related Work
2.1. Generative Adversarial Networks
2.2. Neural Style Transfer
2.2.1 Algorithmic Chinese Painting Generation
3. Gap in Research and Problem Formulation
4. Proposed Method
4.1. Dataset
4.2. Sketch-And-Paint GAN
4.2.1 Stage I: SketchGAN
4.2.2 Stage II: PaintGAN
5. Experiments
5.2. Baselines
5.3. Visual Quality Comparisons
5.3.1 SketchGAN and PaintGAN Output
5.3.2 Baseline Comparisons
5.3.3 Human Study: Visual Turing Tests
5.4. Nearest Neighbor Test
5.5. Latent Interpolations(潜在插入)
6. Future Work
7. Conclusion
8. Acknowledgments(感谢)
摘要:
目前基于gan的艺术生成方法由于依赖于条件输入而产生非原创的作品。在此,我们提出了“素描-绘画GAN”(SAPGAN),这是中国山水画的第一个不需要条件输入就能从头到尾生成的模型。SAPGAN由两个GAN组成:SketchGAN用于生成边缘地图,PaintGAN用于随后的边缘到绘画的翻译。我们的模型是在一个新的中国传统山水画数据集上训练的,此前从未用于生成研究。
1.Introduction
Generative Adversarial Networks (GAN) have been popularly applied for artistic tasks such as turning photographs into paintings, or creating paintings in the style of modern(现代) art. However, there are two critically(严重) underdeveloped(欠发达) areas in art generation research that we hope to address(解决).
First, most GAN research focuses on Western art but overlooks(忽视) East Asian art, which is rich in both historical and cultural significance(历史和文化意义). For this reason, in this paper we focus on traditional Chinese landscape paintings, which are stylistically(风格上) distinctive from(与...不同) and just as aesthetically(审美上) meaningful as Western art.
Second, popular GAN-based art generation methods such as style transfer rely too heavily on conditional inputs,e.g. photographs or pre-prepared sketches. There are several downsides(缺点) to this. A model dependant upon conditional input is restricted(限制) in the number of images it may generate(本应该生成的), since each of its generated images is built upon a single, human-fed input. If instead the model is not reliant on conditional input, it may generate an infinite amount of paintings seeded from latent space. Furthermore, these traditional style transfer methods can only produce derivative(衍生物)artworks that are stylistic copies of conditional input. In end-to-end art creation, however, the model can generate not only the style but also the content of its artworks.
In the context of this paper, the limited research dedicated to(专注于)Chinese art has not strayed from(偏离)conventional style transfer methods. To our knowledge, no one has developed a GAN able to generate high-quality Chinese paintings from end to end.
Here we introduce a new GAN framework for Chinese landscape painting generation that mimics(模仿)the creative process of human artists. How do painters determine(确定) their painting’s composition and structure? They sketch(素描/草图) first, then paint. Similarly, our 2-stage framework, Sketch-and Paint GAN (SAPGAN), consists of two stages.
- The first stage GAN is trained on edge maps from Chinese landscape paintings to produce original landscape “sketches,”
- and the second-stage GAN is a conditional GAN trained on edge painting pairs to “paint” in low-level details.
The final outputs of our model are Chinese landscape paintings which:
1) originate from(产生于) latent space rather than from conditional human input,
2) are high-resolution, at 512x512 pixels,
3) possess definitive edges and compositional qualities(具有明确的边缘和构图品质) reflecting(反映了) those of true Chinese landscape paintings.
In summary, the contributions of our research are as follows:
• We propose Sketch-and-Paint GAN, the first end-to end framework capable(有能力) of producing high-quality Chinese paintings with intelligible(可理解的/清晰地), edge-defined(边缘分明的) landscapes.
• We introduce a new dataset of 2,192 high-quality traditional Chinese landscape paintings which are exclusively(唯一的) curated from art museum(博物馆) collections. These valuable paintings are in large part untouched by generative research and are released for public usage at https://github.com/alicex2020/Chinese-Landscape Painting-Dataset.
• We present experiments from a 242-person Visual Turing Test study. Results show that our model’s artworks are perceived(认为) as human-created over half the time.
2. Related Work
2.1. Generative Adversarial Networks
The Generative Adversarial Network (GAN) consists of two models—a discriminator network D and a generator model G—which are pitted against each other(分庭抗礼) in a minimax two-player game. The discriminator’s objective is to accurately predict if an input image is real or fake; the generator’s objective is to fool the discriminator by producing fake images that can pass off as real. The resulting loss function is:![]() (1)
(1)
where x is taken from the real images denoted(表示) pdata, and z is a latent vector from some probability distribution by the generator G.
Since its inception(开始/开端), the GAN has been widely undertaken as a dominant(占优势的/主导的)research interest for generative tasks such as video frame(框架/帧) predictions, 3D modeling, image captioning, and text-to-image synthesis. Improvements(改进了)to GAN distinguish between(区分) fine and coarse(粗糙的) image representations to create high-resolution, photorealistic images. Many GAN architectures are framed with an emphasis(强调) on a multi-stage(多级的), multi-generator, or multi-discriminator network distinguishing between low and high-level refinement(改进/细化).
2.2. Neural Style Transfer
Style transfer refers to the mapping of a style from one image to another by preserving(保留) the content of a source image, while (同时)learning lower-level stylistic elements to match(匹配) a destination(目标) style. A conditional GAN-based model called Pix2Pix performs image-to-image translation on paired data and has been popularly used for edge-to-photo image translation . NVIDIA’s state-of-the-art Pix2PixHD introduced photorealistic image translation operating at up to 1024x1024 pixel resolution.
2.2.1 Algorithmic Chinese Painting Generation
Neural style transfer has been the basis for most published research regarding Chinese painting generation. Chinese painting generation has been attempted using sketch-to paint translation. For instance, a CycleGAN model was trained on unpaired data to generate Chinese landscape painting from user sketches. Other research has obtained edge maps of Chinese paintings using holistically nested edge detection (HED/整体嵌套边缘检测), then trained a GAN-based model to create Chinese paintings from user-provided simple sketches. Photo-to-painting translation has also been researched for Chinese painting generation. Photo-to-Chinese ink washpainting(水墨画) translation(翻译) has been achieved using void, brush(画笔/刷子) stroke(划), and ink wash constraints on a GAN-based architecture. CycleGAN has been used to map landscape painting styles onto photos of natural scenery. A mask aware GAN was introduced to translate portrait(肖像) photography into Chinese portraits in different styles such as ink drawn and traditional realistic paintings. However, none of these studies have created Chinese paintings without an initial conditional input like a photo or edge map.
3. Gap in Research and Problem Formulation
Can a computer originate art? Current methods of art generation fail to achieve true machine originality(创意), in part due to a lack of research regarding(关于) unsupervised art generation. Past research regarding Chinese painting generation rely on image-to-image translation. Furthermore(此外), the most popular GAN-based art tools and research are focused on stylizing existing images by using style transfer-based generative models.
Our research presents an effective model that moves away from the need for supervised input in the generative stages. Our model, SAPGAN, achieves this by disentangling(分开) content generation from style generation into two distinct(不同) networks. To our knowledge, the most similar GAN architecture to ours is the Style and Structure Generative Adversarial Network (S2 -GAN) consisting of two GANs: a Structure GAN to generate the surface normal maps of indoor scenes and Style-GAN to encode the scene’s low-level details. Similar methods have also been used in pose-estimation(估计) studies generating skeletal(骨骼) structures as well as mapping final appearances onto those structures.
However, there are several gaps(缺口/裂缝) in research that we address.
First, to our knowledge, this style and structure generating approach has never been applied to art generation.
Second, we significantly optimize S2 -GAN’s framework with comparisons(比较) between combinations(组合) of state-of the-art(最先进的) GANs such as Pix2PixHD, RaLSGAN, and StyleGAN2, which have each individually(单独的) allowed for high quality, photo-realistic image synthesis. We report a “meta” state-of-the-art model capable(有能力) of generating human-quality paintings at high resolution, and outperforms(胜过) current state-of-the-art models.
Third, we show that generating minimal structures in the form of HED edge maps is sufficient(足够的) to produce realistic images. Unlike S2 -GAN (which relies on the time-intensive(密集) data collection of the XBox Kinect Sensor) or pose estimation GANs (which are specifically tailored(定制) for pose and sequential(连续的) image generation), our data processing(处理) and models are likely generalizable(归纳为) to any dataset encodable via HED edge detection.
4. Proposed Method
4.1. Dataset
We find current datasets of Chinese paintings ill-suited(不合适) for our purposes for several reasons:
1) many are predominantly(主要) scraped from(提取) Google or Baidu image search engines(引擎), which often present irrelevant results;
2) none are exclusive(独有的) to the traditional Chinese landscape paintings;
3) the image quality and quantity are lacking. In the interest of promoting more research in this field, we build a new dataset of high-quality traditional Chinese landscape paintings.
Collection. Traditional Chinese landscape paintings are collected from open-access museum galleries: the Smithsonian Freer Gallery, Metropolitan Museum of Art, Princeton University Art Museum, and Harvard University Art Museum.
Cleaning. We manually(手动的)filter out non-landscape(非风景) artworks, and hand-crop large chunks of calligraphy(书法) or silk(丝绸) borders out of the paintings.
Cropping and Resizing(剪辑、重新组织大小). Paintings are first oriented vertically(垂直定向的) and resized by width to 512 pixels while maintaining aspect ratios(各自的比例). A painting with a low height-to-width ratio means that the image is almost square(正方形) and only a center crop of 512x512 is needed. Paintings with a height-to width ratio greater than 1.5 are cropped into vertical, nonoverlapping 512x512 chunks. Finally, all cropped portions(部分) of reoriented(调整) paintings are rotated back to their original horizontal(水平) orientation.
Edge Maps. HED performs edge detection using a deep learning model which consists of fully convolutional neural networks, allowing it to learn hierarchical(分层的)representations of an image by aggregating(聚合) edge maps of coarse-to-fine features. HED is chosen over Canny(精细的) edge detection due to HED’s ability to clearly outline(勾勒) higher-level shapes while still preserving some low-level detail. We find from our experiments that Canny often misses important high-level edges as well as produces disconnected low-level edges. Thus, 512x512 HED edge maps are generated and concatenated with(连接) dataset images in preparation for training.
4.2. Sketch-And-Paint GAN
We propose a framework for Chinese landscape painting generation which decomposes(分解) the process into content then style generation.
Our stage-I GAN, which we term(学期/把...叫做) “SketchGAN,” generates high-resolution edge maps from a vector sampled from latent space.
stage-II GAN, “PaintGAN,” is dedicated(专注于) to image-to-image translation and receives the stage-I-generated sketches as input. A full model schema(架构/模式) is diagrammed (用图解法表示)in Figure 3. Within this framework, we test different combinations(组合) of existing architectures. For SketchGAN, we train RaLSGAN and StyleGAN2 on HED edge maps. For PaintGAN, we train Pix2Pix, Pix2PixHD, and SPADE on edge-painting pairs and test these trained models on edges obtained from either RaLSGAN or StyleGAN2.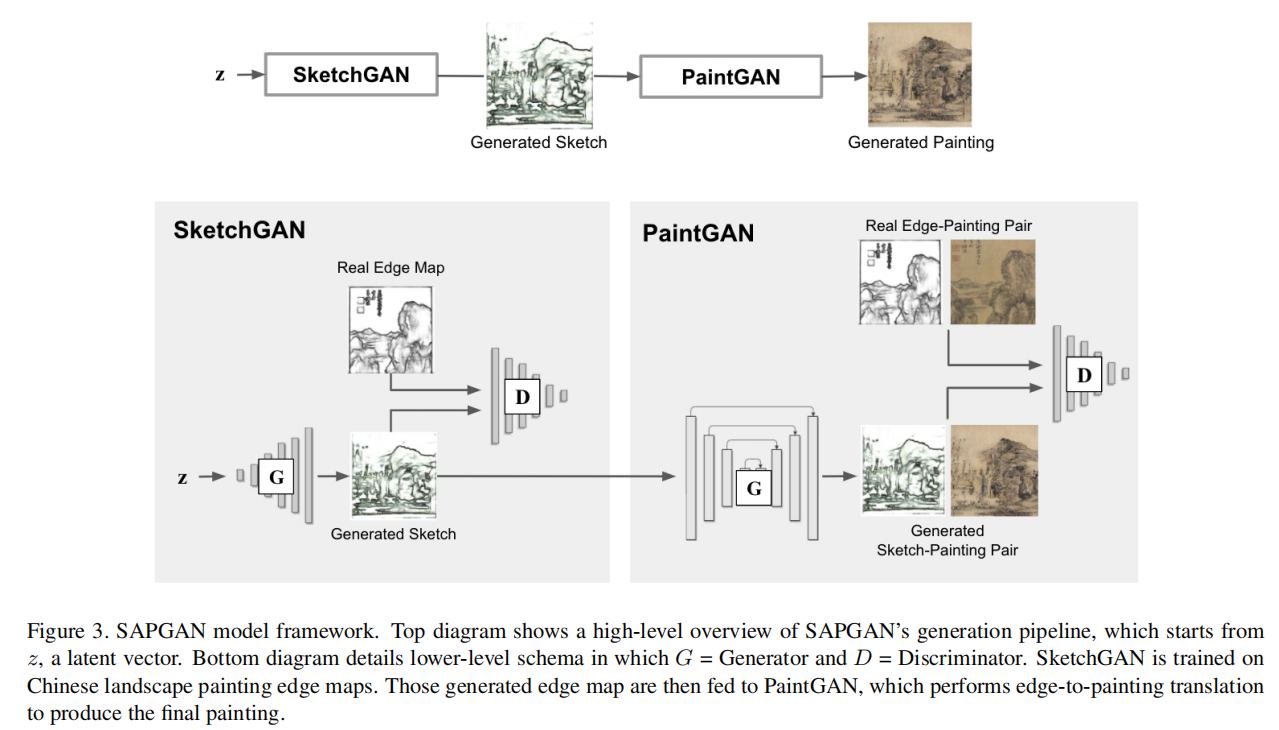
4.2.1 Stage I: SketchGAN
We test two models to generate HED-like edges, which serve as “sketches.” SketchGAN candidates are chosen due to their ability to unconditionally synthesize high-resolution images: RaLSGAN. in introduced a relativistic GAN for high-quality image synthesis and stable training. We adopt their Relativistic Average Least Squares GAN (RaLSGAN) and use a PACGAN discriminator, architecture following.
StyleGAN2. a state-of-the-art model for unconditional image synthesis, generating images from latent vectors. We choose StyleGAN2 over its predecessors(而不是它的前身), StyleGAN and ProGAN, because of its improved image quality and removal of visual artifacts(伪影) arising from progressive growing(不断增长). To our knowledge, StyleGAN2 has never been researched for Chinese painting generation.
4.2.2 Stage II: PaintGAN
PaintGAN is a conditional GAN trained with HED edges and real paintings. The following image-to-image translation models are our PaintGAN candidates.
Pix2Pix. Like the original implementation, we use a Unet generator and PACGAN discriminator. The main change we make to the original architecture is to account for a generation of higher-resolution, 512x512 images by adding an additional downsampling and upsampling layer to the generator and discriminator.
Pix2PixHD. Pix2PixHD is a state-of-the-art conditional GAN for high-resolution, photorealistic synthesis. Pix2PixHD is composed of a coarse-to-fine generator consisting of a global and local enhancer network, and a multiscale(多尺度的) discriminator operating at three different resolutions.
SPADE. SPADE is the current state-of-the-art model for image-to-image translation. Building upon Pix2PixHD, SPADE reduces the “washing-away” effect of the information encoded by the semantic(语义) map, reintroducing the input map in a spatially-adaptive layer.
5. Experiments
To optimize the SAPGAN framework, we test combinations(组合) of GANs for SketchGAN and PaintGAN. In Section 5.3, we assess the visual quality of individual and joint(联合) outputs from these models. In Section 5.3.3, we report findings from a user study.
5.1. Training Details Training of the two GANs occurs in parallel(并行): SketchGAN on edge maps generated from our dataset, and PaintGAN on edge-painting pairings. The outputs of SketchGAN are then loaded into the trained PaintGAN model.
SketchGAN. RaLSGAN: The model is trained for 400 epochs. Adam optimizer is used with betas = 0.9 and 0.999, weight decay(衰减) = 0, and learning rate = 0.002.
StyleGAN2: We use mirror augmentation(增强), training from scratch for 2100 kimgs, with truncation psi of 0.5.
PaintGAN. Pix2Pix: Pix2Pix is trained for 400 epochs with a batch size of 1. Adam optimizer with learning rate = 0.0002 and beta = 0.05 is use for U-net generator.
Pix2PixHD: Pix2PixHD is trained for 200 epochs with a global generator, batch size = 1, and number of generator filters = 64.
SPADE: SPADE is trained for 225 epochs with batch size of 4, load size of 512x512, and 64 filters in the generator’s first convolutional layer.
5.2. Baselines
DCGAN. We find that DCGAN generates only 512x512 static noise due to vanishing(消失) gradients. No DCGAN outputs are shown for comparison(比较), but it is an implied low baseline.
RaLSGAN. RaLSGAN is trained on all landscape paintings from our dataset with same configurations as listed above.
StyleGAN2. StyleGAN2 is trained on all landscape paintings with the same configurations as listed above.
5.3. Visual Quality Comparisons
5.3.1 SketchGAN and PaintGAN Output
We first examine(检查) the training results of SketchGAN and PaintGAN separately.
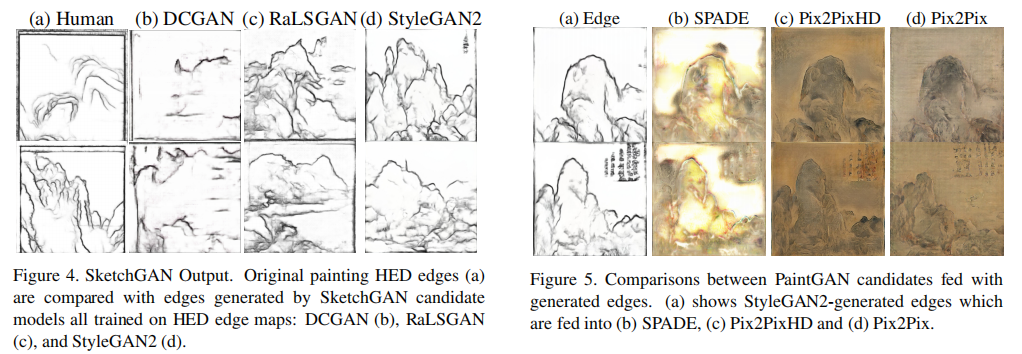
SketchGAN. DCGAN, RaLSGAN, and StyleGAN2 are tested for their ability to synthesize realistic edges. Figure 4 shows sample outputs from these models when trained on HED edge maps. DCGAN edges show little semblance(外表) of landscape definition. Meanwhile, StyleGAN and RaLSGAN outputs are clear and high-quality. Their sketches outline high-level shapes of mountains, as well as low-level details such as rocks(岩石) in the terrain(地形).
PaintGAN. PaintGAN candidates SPADE, Pix2PixHD, and Pix2Pix are shown in Figure 5. StyleGAN2-generated sketches are used as conditional input to a) SPADE, b) Pix2PixHD, and c) Pix2Pix (Figure 5). Noticeably, SPADE outputs’ colors show evidence of over-fitting; the colors are oversaturated(过饱和), yellow, and unlike those of normal landscape paintings (Figure 5b). In Pix2PixHD, there are also visual artifacts, seen from the halo-like coloring around the edges of the mountains (Figure 5c). Pix2Pix performs the best, with fewer visual artifacts and more varied coloring. PaintGAN candidates do poorly at the granular(颗粒) level needed to“fill in” Chinese calligraphy, producing the blurry(模糊的) characters (Figure 5, bottom row). However, within the scope of this research, we focus on generating landscapes rather than Chinese calligraphy, which merits its own paper.
5.3.2 Baseline Comparisons
Both baseline models underperform(表现不佳)in comparison to our SAPGAN models. Baseline RaLSGAN paintings show splotches(污点/斑点) of color rather than any meaningful representation of a landscape, and baseline StyleGAN2 paintings show distorted(歪曲的), unintelligible landscapes (Figure 6). Meanwhile, SAPGAN paintings are superior to baseline GAN paintings in regards to realism and artistic composition. The SAPGAN configuration, RaLSGAN edges + Pix2Pix (for brevity(简洁的), the word “edges” is henceforth(从此以后)omitted(忽略)when referencing SAPGAN models), would sometimes even separate foreground objects from background, painting distant mountains with lighter (浅)colors to establish a fading(褪色/衰退) perspective (视角)(Figure 6e, bottom image). RaLSGAN+Pix2Pix also learned to paint mountainous terrains (地形)faded in mist(薄雾) and use negative space to represent rivers and lakes (Figure 6e, top image). The structural composition and well-defined depiction(刻画)of landscapes mimic characteristics of traditional Chinese landscape paintings, adding to the paintings’ realism.
5.3.3 Human Study: Visual Turing Tests
We recruit(招募) 242 participants to take a Visual Turing Test. Participants are asked to judge if a painting is human or computer-created, then rate its aesthetic(美的) qualities. Among the test-takers, 29 are native Chinese speakers and the rest are native English speakers. The tests consist of 18 paintings each, split evenly between human paintings, paintings from the baseline model RaLSGAN, and paintings from SAPGAN (RaLSGAN+Pix2Pix).
For each painting, participants are asked three questions:
Q1: Was this painting created by a human or computer? (Human, Computer)
Q2: How certain were you about your answer?
(Scale of 1-10)
Q3: The painting was: Aesthetically pleasing, Artfully-composed, Clear, Creative. (Each statement has choices: Disagree, Somewhat disagree, Somewhat agree, Agree)
The Student’s two-tailed t-test is used for statistical analysis, with p < 0.05 denoting statistical signifificance.
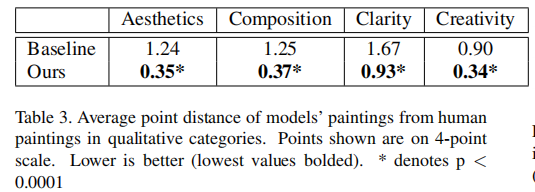
Results. Among the 242 participants, paintings from our model where mistaken as human-produced over half the time. Table 2 compares the frequency that SAPGAN versus baseline paintings were mistaken for human. While SAPGAN paintings passed off as human art with a 55% frequency, the baseline RaLSGAN paintings did so only 11% of the time (p < 0.0001). Furthermore, as Table 3 shows, our model was rated consistently higher than baseline in all of the artistic categories: “aesthetically pleasing,” “artfully-composed,” “clear,” and “creativity” (all comparisons p < 0.0001). However, in these qualitative categories, both the baseline and SAPGAN models were rated consistently lower than human artwork. The category that SAPGAN had the highest point difference from human paintings was the “Clear” category. Interestingly, though lacking in realism, baseline paintings performed best (relative to their other categories) in “Creativity”—most likely due to the abstract nature of the paintings which deviated typical landscape paintings. We also compared results of the native Chinese- versus English-speaking participants to see if cultural exposure would allow Chinese participants to judge the paintings correctly. However, the Chinese-speaking test-takers scored 49.2% on average, signifificantly lower than the English-speaking test-takers, who scored 73.5% on average (p < 0.0001). Chinese speakers also mistook SAPGAN paintings for human 70% of the time, compared with the overall 55%. Evidently, regardless of familiarity with Chinese culture, the participants had trouble distinguishing the sources of the paintings, indicating the realism of SAPGAN-generated paintings.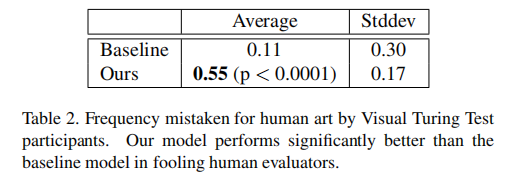
5.4. Nearest Neighbor Test
The Nearest Neighbor Test is used to judge a model’s ability to deviate(偏离) from its training dataset. To find a query’s closest neighbors, we compute pixel-wise L2 distances from the query image to each image in our dataset. Results show that baselines, especially StyleGAN2, produce output that is visually similar to training data. Meanwhile, paintings produced by our models creatively stray from the original paintings (Figure 8). Thus, unlike baseline models, SAPGAN does not memorize its training set and is robust to over-fitting, even on a small dataset.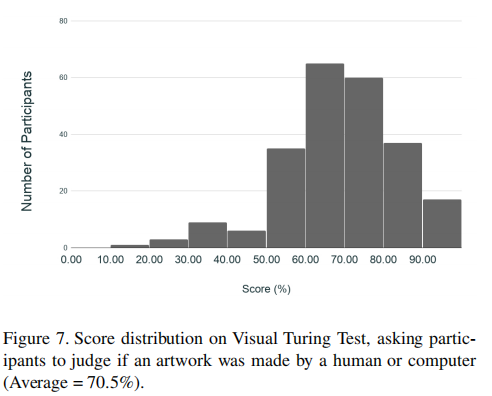

5.5. Latent Interpolations(潜在插入)
Latent walks are shown to judge the quality of interpolations by SAPGAN (Figure 9). With SketchGAN (StyleGAN2), we first generate six frames of sketch interpolations from two random seeds, then feed them into PaintGAN (Pix2Pix) to generate interpolated paintings. Results show that our model can generate paintings with intelligible landscape structures at every step, most likely due to the high quality of StyleGAN2’s latent space interpolations as reported in.
6. Future Work
Future work may substitute(代替) different GANs for SketchGAN and PaintGAN, allowing for more functionality such as multimodal generation(多模态生成) of different painting styles. Combinations GANs that are capable of adding brush strokes or calligraphy onto the generated paintings may also increase appearances of authenticity (能够在生成的画作上添加毛笔或书法的组合可能也可以增加外观的真实性). Importantly, apart from (除了)being trained on a Chinese landscape painting dataset, our proposed(提出的)model is not specifically(特定的) tailored (专门制作)to Chinese paintings and may be generalized to other artistic styles which also emphasize edge definition. Future work may test this claim(未来的研究可能验证这一说法).
7. Conclusion
We propose the first model that creates high-quality Chinese landscape paintings from scratch(从无到有). Our proposed framework, Sketch-And-Paint GAN (SAPGAN), splits the generation process into sketch generation to create level structures, and paint generation via image-to-image translation. Visual quality assessments find that paintings from the RaLSGAN+Pix2Pix and StyleGAN2+Pix2Pix configurations for SAPGAN are more edge-defined and realistic in comparison to baseline paintings, which fail to evoke intelligible structures. SAPGAN is trained on a new dataset of exclusively museum-curated, high-quality traditional Chinese landscape paintings. Among 242 human evaluators, SAPGAN paintings are mistaken for human art over half of the time (55% frequency), significantly higher than that of paintings from baseline models. SAPGAN is also robust(健壮的) to over-fitting compared with baseline GANs, suggesting that it can creatively deviate(偏离) from its training images. Our work supports the possibility that a machine may originate artworks.
8. Acknowledgments(感谢)
We thank Professor Brian Kernighan, the author’s senior thesis advisor, for his guidance and mentorship throughout the course of this research. We also thank Princeton Research Computing for computing resources, and the Princeton University Computer Science Department for funding.
最后
以上就是单纯草丛最近收集整理的关于使用生成对抗网络进行端到端中国山水画创作(SAPGAN)摘要:1.Introduction2. Related Work3. Gap in Research and Problem Formulation4. Proposed Method5. Experiments5.3. Visual Quality Comparisons6. Future Work7. Conclusion8. Acknowledgments(感谢)的全部内容,更多相关使用生成对抗网络进行端到端中国山水画创作(SAPGAN)摘要:1.Introduction2.内容请搜索靠谱客的其他文章。








发表评论 取消回复