- the address of paper
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
这篇论文是CVPR2018的一篇文章,其论文的研究方向是GAN网络的图像多域迁移转换。

论文地址:https://arxiv.org/pdf/1711.09020.pdf
代码地址:https://github.com/yunjey/stargan
- the introduction of paper
starGAN这篇论文,我觉得是一篇很有代表性的论文,类似之前的GAN网络模型,比如pix2pix,cycleGAN,这些是生成对抗网络方向,十分具有代表性的网络模型,但是有一个模型的弊端,就是只能one to one。所谓one to one的模型,比如进行黄色头发到蓝色头发的转换,但是如果我们同时需要黄色的头发进行蓝色颜色的转换,并且还需要进行表情的迁移转换,这个时候怎么办?是不是就要重新换一个模型大大增加了成本,starGAN就是实现了这种多对多的图像迁移转换。 - the related work of paper
GAN网络模型分为生成器和判别器两部分,starGAN中生成器的网络模型结构组成:在生成器的网络层数种类包括下采样层,残差块,以及转置卷积层

判别器网络结构:判别器均是由卷积层所组成的,使用的激活函数为relu。
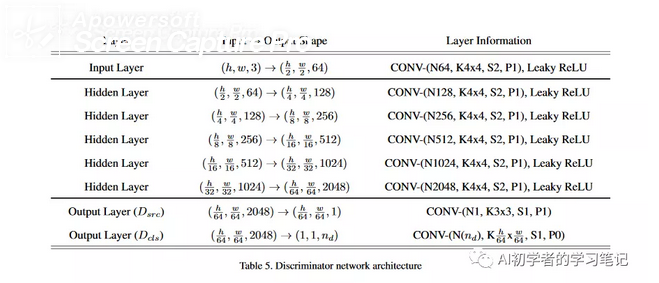
如果使用pix2pix这样的模型,进行k个种类之间的转换,则需要k(k-1)个模型进行生成,starGAN引入了mask vector的概念,使得让判别器在识别生成器生成的图片时,不仅识别生成图片的真假,还要识别生成图片的种类,也就是生成的图片是完成了哪一个方面的迁移,并且识别图片的真假。一直使用一个生成器G。如下图中的b,使用一个G进行1-5之间的转换,因为模型的形状很像一个五角星,因此称模型为starGAN。
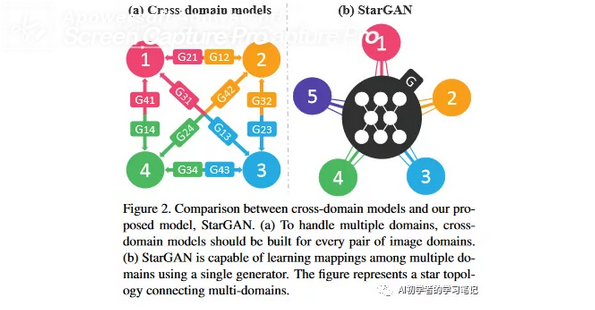
mask vector是一个张量其中包括了各种的图像标签,c1-c5,

4. the model
该模型结构在之前已经列出来了,本论文中所使用的数据集是celeba数据集,其中包括了hair color, gender, age, skin几方面进行输入图片的转换。均是由一个生成器进行图像的生成。以下是starGAN的整个工作流程。
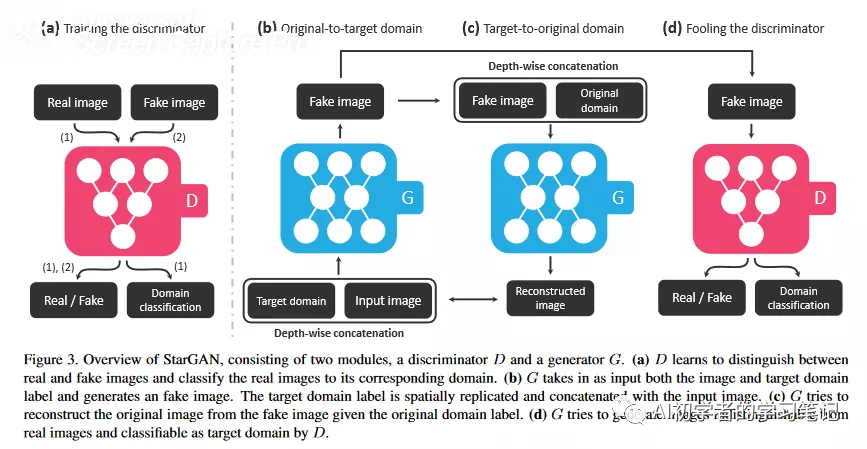
输入fake image的图片,具有原有的标签,生成重构的图片,将重构后的图片再输入生成器融入目标的标签,生成fake image,由判别器进行生成的图片判别,不仅仅要判别图片的真假,还要判别图片的domain label,进行训练,一直训练到生成器所生成的图片被判别器无法识别真假。实际的训练过程如下所示;
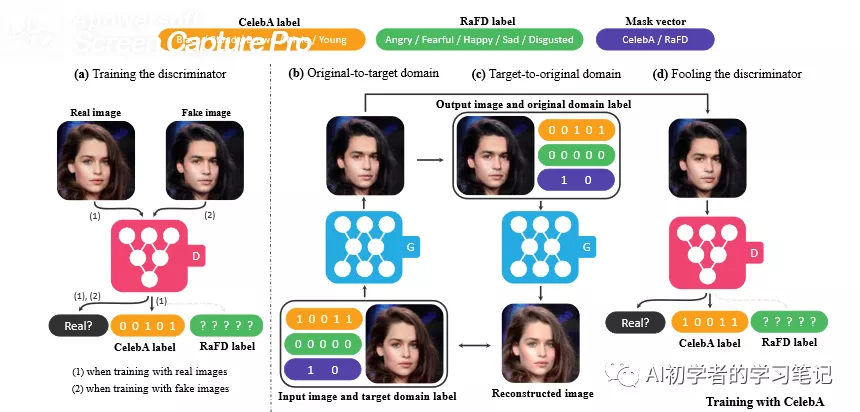
5. the code of model
(1)残差单元代码
class ResidualBlock(nn.Module):
"""Residual Block with instance normalization."""
def __init__(self, dim_in, dim_out):
super(ResidualBlock, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.Conv2d(dim_out, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True))
def forward(self, x):
return x + self.main(x)
(2)生成器代码
class Generator(nn.Module):
"""Generator network."""
def __init__(self, conv_dim=64, c_dim=5, repeat_num=6):
super(Generator, self).__init__()
layers = []
layers.append(nn.Conv2d(3+c_dim, conv_dim, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.InstanceNorm2d(conv_dim, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
# Down-sampling layers.
curr_dim = conv_dim
for i in range(2):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim*2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim * 2
# Bottleneck layers.
for i in range(repeat_num):
layers.append(ResidualBlock(dim_in=curr_dim, dim_out=curr_dim))
# Up-sampling layers.
for i in range(2):
layers.append(nn.ConvTranspose2d(curr_dim, curr_dim//2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim//2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim // 2
layers.append(nn.Conv2d(curr_dim, 3, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.Tanh())
self.main = nn.Sequential(*layers)
def forward(self, x, c):
# Replicate spatially and concatenate domain information.
# Note that this type of label conditioning does not work at all if we use reflection padding in Conv2d.
# This is because instance normalization ignores the shifting (or bias) effect.
c = c.view(c.size(0), c.size(1), 1, 1)
c = c.repeat(1, 1, x.size(2), x.size(3))
x = torch.cat([x, c], dim=1)
return self.main(x)
(3)判别器代码
class Discriminator(nn.Module):
"""Discriminator network with PatchGAN."""
def __init__(self, image_size=128, conv_dim=64, c_dim=5, repeat_num=6):
super(Discriminator, self).__init__()
layers = []
layers.append(nn.Conv2d(3, conv_dim, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = conv_dim
for i in range(1, repeat_num):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = curr_dim * 2
kernel_size = int(image_size / np.power(2, repeat_num))
self.main = nn.Sequential(*layers)
self.conv1 = nn.Conv2d(curr_dim, 1, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(curr_dim, c_dim, kernel_size=kernel_size, bias=False)
def forward(self, x):
h = self.main(x)
out_src = self.conv1(h)
out_cls = self.conv2(h)
return out_src, out_cls.view(out_cls.size(0), out_cls.size(1))
- the related work
starGAN是2018年CVPR的paper,在今年的CVPR2020已经推出了starGAN V2,在下一次可以读starGAN-vc的paper,将starGAN的方法放入语音领域,进行语音合成与转换。可以自己动手复现一下StarGAN,使用celebA的数据集进行效果复现。
博主微信公众号:
AI学习经历分享
内容更清晰,欢迎关注,一键三连~
最后
以上就是开心八宝粥最近收集整理的关于机器学习会议论文(二)StarGAN图像多域迁移转换的全部内容,更多相关机器学习会议论文(二)StarGAN图像多域迁移转换内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复