
摘要
语法纠错(GEC,Grammatical Error Correction,下同)是NLP的一个子领域,在搜索query纠错、语音纠错、舆情文本纠错等诸多直接与普通大众交互的场景得到应用。在深度学习被广泛使用的背景下,研究人员提出了多种方法来解决语法纠错问题,比如基于序列标注融合特征工程的方法[1],基于有限错误类别集合分类及定位的方法(e.g. CUUI:Columbia University-University of Illinois, CoNLL-2014 top-2),基于语言模型的方法[2](e.g. BERT model),基于神经机器翻译(Neural Machine Translation,NMT下同)方法及其变种或组合方法[3,4]等等。本文介绍的是基于NMT模型的语法纠错算法,并结合前沿文章具体介绍若干方法。
1 GEC&CGEC介绍
1.1 GEC简介
GEC是(Grammatical Error Correction)的简写,一般指英文语法纠错,中文语法纠错(称为CGEC)有一些差异性,发展过程包括三个阶段:(1)基于规则;(2)数据驱动的传统机器学习;(3)基于机器翻译[SMT(基于统计机器翻译)和NMT(神经机器翻译)]。随着深度学习的广泛应用,传统机器学习方法也基本使用深度学习方式实现替换,比如深度学习实现错误类别分类器或序列标注模型,这类方法对冠词、介词等错误的纠正效果十分明显,但也存在一些问题。而神经机器翻译(NMT)的方式,将有语法问题的“坏”句子翻译成“好”句子,这种系列的方法在研究中占比较多,所衍生出来的方法也比较广,这也是本文介绍的内容。
1.2 GEC评估指标
在各类标准测试集中或者比赛数据中,一般是会给出错误类别和位置信息,同时诸多比赛中一般也要求模型预测结果也要求给出错误类别和位置。对于这种数据集,直接按照各项指标(准确率(Precision)、召回率(Recall)以及F0.5)基本意义,将代数统计转换为相应集合计算即可,如释义公式(1)所示。语法纠错任务选择F0.5作为评价指标而非F1值的原因在于,对于模型纠正的错误中,更加看重编辑的准确性而非更多的编辑数量,所以将准确率的权重定为召回率的两倍大小。
事实上在实际工作中也一般推荐这种构造标准测试集的方式,简单且直观。但如果使用源数据检测效果,也可以采用人工抽样,或者进行n-gram对比统计的方式给出测试结果。

其中交集的计算方法为:

2 seq2seq介绍
由于当前使用较为广泛的NMT模型就是Seq2Seq 模型极其衍生模型,所以在此值得介绍一下。Seq2Seq 模型顾名思义,输入一个序列,用一个 RNN (Encoder)编码成一个向量u,再用另一个 RNN (Decoder)解码成一个序列输出,且输出序列的长度是可变的。该方法用途很广,可用于机器翻译,自动摘要,对话系统,多跳问答,语法纠错等领域。
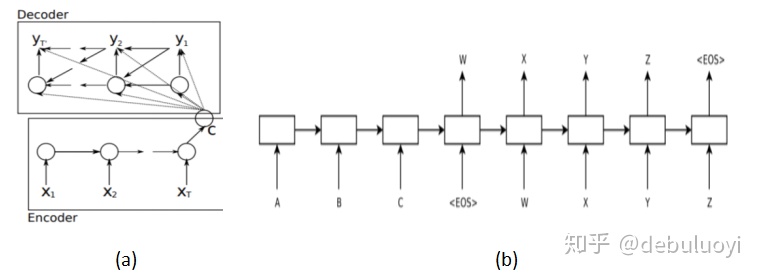
实际上这种Encoder–Decoder 结构也有两种,分别在两篇文章中提及:
- Cho, K.(2014)[5]在2014年提出了 Encoder-Decoder 结构,即由两个 RNN 组成,如图2-1(a)所示。encoder的语义向量C,Decoder 在 t 时刻的隐藏层状态 ht 由 ht−1,yt−1,C 决定,其Decoder初始状态向量是固定字符的embedding,与C无关。
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014)[6]在2014年也发表了论文,如图2-1(b)所示。encoder的语义向量C将作为 Decoder 的初始状态。
基本的seq2seq是比较简单的但是效果也差。相较于baseline模型,实际常应用的方法有几点值得介绍。
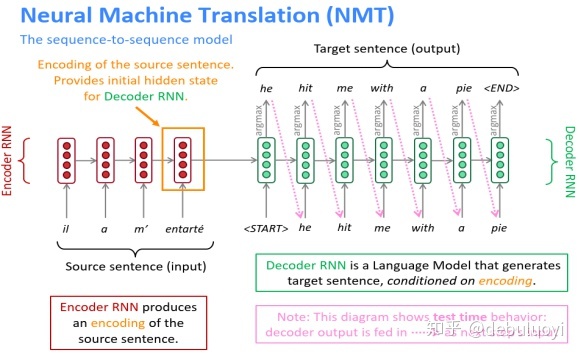
- Teacher Forcing model
Teacher Forcing实际就是在训练中加入了真实目标域数据编码,不管模型上一个时刻的实际输出的是什么,哪怕输出错了,下一个时间片的输入总是上一个时间片的期望输出,阻断错误积累,斧正模型训练,加快参数收敛。(如图2-2所示)
当然带来的问题就是预测时候是不知道目标域内容的。谷歌源码中用helper这个类来帮你自动地给 decoder rnn 的每个时刻提供不同的输入内容,用或不用 Teacher Forcing 的区别只在于将 helper 定义为 TrainingHelper 或是 GreedyEmbeddingHelper。 在实际应用中,训练阶段阶段新建一个用 TrainingHelper 的模型,训练完了保存模型参数;在推理阶段不知道目标域内容,新建另一个用 GreedyEmbeddingHelper 的模型,直接加载训练好的参数使用替代编码输入功能。
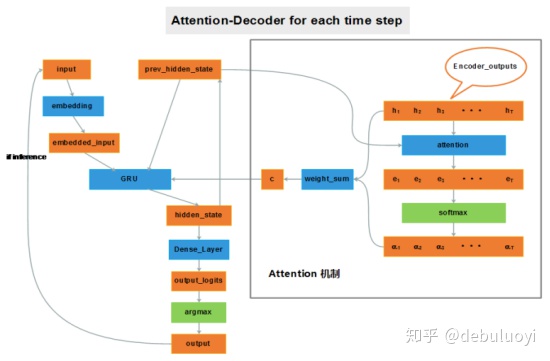
- Attention model
因为 encoder把很长的句子压缩只成了一个小向量“u”,decoder在解码的过程中容易遗忘,普通的seq2seq由于输入语句表示是存在瓶颈的,attention操作可以极大缓解这种问题。
如果给 decoder 多提供了一个输入“c”,在解码序列的每一步中都让“c”参与就可以缓解瓶颈问题。输入序列中每个单词对 decoder 在不同时刻输出单词时的帮助作用不一样,所以就需要提前计算一个 attention score 作为权重分配给每个单词,再将这些单词对应的 encoder output 带权加在一起,就变成了此刻 decoder 的另一个输入“c”。如图2-3所示。
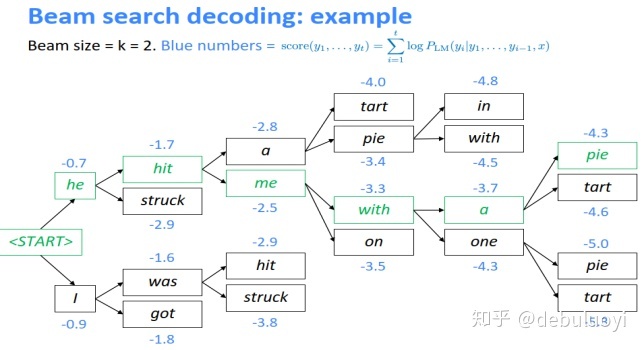
- Beam Search
这个可以自行对比一下:exhaustive search(穷举搜索),greedy search。Beam Search是个只在 test 阶段有用的设定。之前基础的 seq2seq 版本在输出序列时,仅在每个时刻选择概率 top 1 的单词作为这个时刻的输出单词(相当于局部最优解),然后把这些词串起来得到最终输出序列,实际上就是贪心策略。但如果使用了 Beam Search,如图2-4所示,在每个时刻会选择 top K 的单词都作为这个时刻的输出,逐一作为下一时刻的输入参与下一时刻的预测,然后再从这 K*L(L为词表大小)个结果中选 top K 作为下个时刻的输出,以此类推。在最后一个时刻也就是遇到结束标识符的时候,选 top 1 作为最终输出。
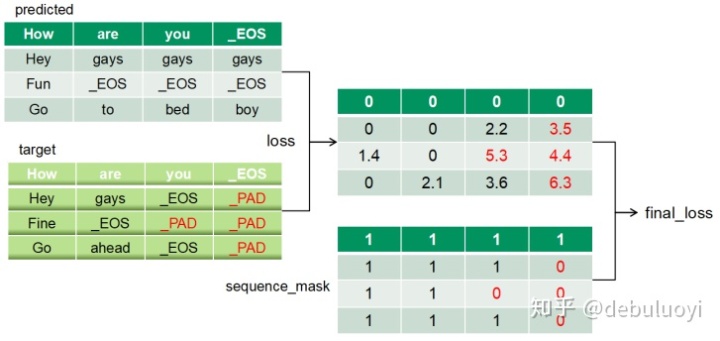
- Loss function
Loss设计是在正常的损失矩阵上面乘以一个sequence mask矩阵。如图2-5所示,实际上“_PAD”本身没有意义,其 loss 计算是没有用的,只是占位用的,计算 loss 反而带来副作用,影响参数的优化,所以增加一个mask矩阵把它去掉。
3方法&数据
3.1 基于Classify+MT纠错算法[3]
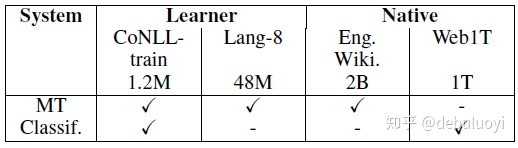
Rozovskaya, A., & Roth, D. (2016, August)[3]提出一种Classify+MT的语法纠错方法。文章使用数据包括含标注数据及无标签数据如表3-1所示。Classify模型中包含有监督和无监督:使用CoNLL-train训练多分类模型,利用标注在其中增加POS和语法特征,目标为有限类的error type;使用native data (Web1T)进行无监督训练(这里是朴素贝叶斯模型),即针对部分类别错误使用某个词周边 n-gram features取预测出该词是什么。
表 3-1 数据列表
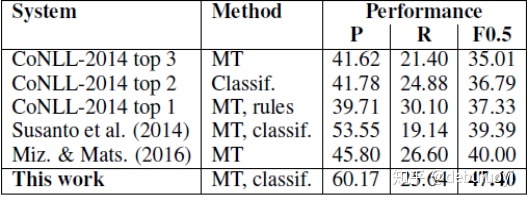
文章对比历年基于MT/Classify的SOTA方法对不同错误现象的效果,设计了Classify+MT的语法纠错方法达到同系列方法SOTA效果(如表3-2所示)。值得一提的是,该方法中分类模型模块预测结果可输出错误类别和校正词汇,并在错误类别中增加mechanical errors,包括标点,拼写和大写等,充分利用有监督和无监督模型将一些基本错误定位及修正在这一步完成,使得后续的MT模型的输入尽量准确有效。通过两段式的模型融合,可以结合两种模型的优势提升效果:分类方法能够归纳识别单个错误的类别,处理一些有限类的错误效果较好;而机器翻译方法从平行数据中学习而无需语言学知识输入,更擅长纠正复杂的错误。
这个是一个很明显的结论,MT在基于classify模块纠正后再纠正会好一些。至少在一个朴素的想法中,先行使用有限错误类集合实现分类和定位完成有限类错误纠正,然后输入到NMT模型中,不仅仅是语义更加完善准确,也可以进行错误位置标记、错误类型标记、错误加权表征,错误处损失加权等等操作,实现模型优化,所以这类多方式融合的模型思路是值得进一步探究的。
表 3-2 效果对比列表
3.2 基于流畅度提升方法的语法纠错[4]
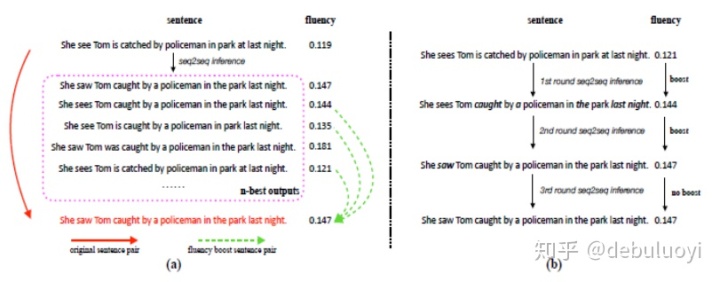
传统的seq2seq单次纠错在面对句子有多项错误时,容易纠错不全,甚至越纠越错。如图3-1所示纠错流程中,(a)过程其实是(b)+(c)完成的,如果模型只纠错其中一个步骤,那么其结果依然是错误的。这是seq2seq模型只纠错一次的缺陷,而这个问题在真实纠错问题中又很普遍:一个句子有多处不同的错误是很正常的。

Ge, T., Wei, F., & Zhou, M. (2018)[4]提出了一种基于流畅度提升的方法,本质是seq2seq的提升变种。这是一篇来自Microsoft Research Asia的相关文章,效果达到当年度SOTA。文章定义了流畅度计算方法,提出了一种基于流畅度提升的方法,如图3-2所示,基于流畅度比较可以将中间结果保存即图中的n-best output,与目标域数据形成新的配对并参与训练,直至流畅度比较结果达到停止条件。其主要贡献在于:
- 基于 seq2seq 框架,首次提出了一种新的流畅度提升学习和推断机制;
- 给出流畅度定义;
- 进行多轮/往返提升等操作效果显著。
Ø Methodology
(1)流畅度定义
流畅度定义为句子交叉熵加的函数,公式计算入公式(3)~(4)所示。

(2)提升方法
研究者展示了三种流畅度提升策略:反向提升(back-boost)、自提升(self-boost)和双向提升(dual-boost),它们以不同的方式生成流畅度提升句子对,如图3-3所示。
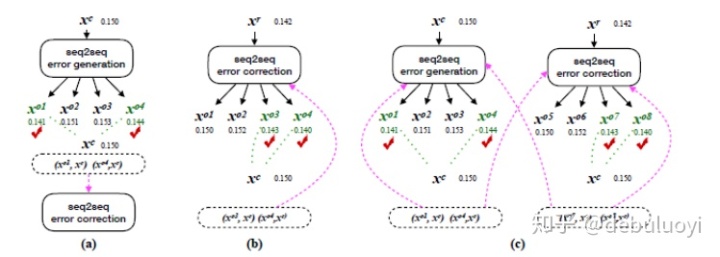
(3)多轮纠错
具有多个语法错误的语句通常不能通过一般的 Seq2Seq 推断(单轮推断)得到完美的修正。在GEC问题中源语言与目标语言相同,这一特征允许我们通过多轮模型推断多次编辑语句,也就产生了基于流畅度的多轮纠错提升推断过程。
具体来说,纠错 Seq2Seq 模型首先将原语句 xr 作为输入,并输出假设 xo1。然后流畅度提升推断将采用 xo1 作为输入以生成下一个输出 xo2,而不是将 xo1 直接作为最终的预测。除非 xot不再能提升 xot-1 的流畅度,否则这一过程就不会终止,即中间结果得到记录并可以配对作为输入,直至流畅度不提升。
(4)往返纠错
如图3-4所示,某些类型的错误(例如,冠词错误)由从右到左的 seq2seq 模型会更容易纠错,而某些错误(例如主谓一致)由从左到右的 seq2seq 模型更容易纠错。往返纠错使得二者互补,相对于单个模型能纠正更多的语法错误。

Ø Data&Performance
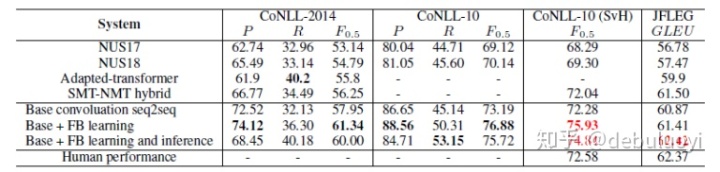
数据集使用Lang-8,CoNLL-2014等数据集,使用流畅度提升(FB)方法的模型较其他模型效果明显提升,并达到人类水准。(如表3-3所示)
表 3-3 CoNLL and JFLEG 数据集评估结果,标红为超越人类水准
4 结语与展望
小结。不论是序列标注类的、机器翻译类的或者是融合模型,目前的改错模型主要是基于对句子的浅层分析,并不涉及到对语义级别的深层理解,这就使得在涉及到深层语义理解的错误修改时,机器的能力要远弱于人类专家的水平;但对于大多数语法错误来说,机器自动语法改错的能力确实已经可以达到人类的水平了。
展望。目前自动语法改错通常只涉及到单句级别的修改,并不会考虑段落或者篇章级上下文语境。因此,机器自动改错想要真正超越人类水平,还有较长的一段路要走,期待学术界的进一步研究成果。
参考文献
[1] Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task:NLPTEA-2018 Task1(top 1)
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[3] Rozovskaya, A., & Roth, D. (2016, August). Grammatical error correction: Machine translation and classifiers. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2205-2215).
[4] Ge, T., Wei, F., & Zhou, M. (2018). Reaching human-level performance in automatic grammatical error correction: An empirical study. arXiv preprint arXiv:1807.01270.
[5] Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
[6] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in NIPS.
最后
以上就是伶俐小蜜蜂最近收集整理的关于统计机器翻译与神经机器翻译区别_基于神经机器翻译(NMT)的语法纠错算法的全部内容,更多相关统计机器翻译与神经机器翻译区别_基于神经机器翻译(NMT)内容请搜索靠谱客的其他文章。








发表评论 取消回复