回译
在网上学习nlp数据增强方法的时候看到了许多有趣的方法,看了看传统的中文EDA已经写的很完善了。自己就写了back translation方法方便自己用。
这边采用的翻译api是百度的,当然也可以用其他的api比如讯飞之类的,但里面架构得重新写。
首先写百度api对应接口,其实改一下官方给的demo就可以用
填入自己的appid和appkey
lang_list里是需要翻译的语种,我这里就放了5种,可根据自己需要修改
import requests
import random
from hashlib import md5
# Set your own appid/appkey.
appid = 'XXX'
appkey = 'XXX'
def get_trans(query, from_lang='en', to_lang='zh'):
# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + query + str(salt) + appkey)
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
r = requests.post(url, params=payload, headers=headers)
result = r.json()
# print(result)
return result['trans_result'][0]['dst']
def all_trans(query):
res_end = []
res_begin = []
# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`
lang_list = ['en', 'jp', 'fra', 'kor', 'ru']
for temp in lang_list:
res_begin.append(get_trans(query, 'zh', temp))
for temp in zip(res_begin, lang_list):
res_end.append(get_trans(temp[0], temp[1], 'zh'))
res_end.append(query)
return res_end
if __name__ == "__main__":
res = all_trans('童话说雨后终会出现彩虹,却不曾说过它也会转瞬成空')
下面写一个调用程序的文件
import utils
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("--input", required=True, type=str, help="原始数据的输入文件目录")
ap.add_argument("--output", required=False, type=str, help="增强数据后的输出文件目录")
args = ap.parse_args()
def back_trans(train_orig, output_file):
writer = open(output_file, 'w', encoding='utf-8')
lines = open(train_orig, 'r', encoding='utf-8').readlines()
print("正在使用回译生成增强语句...")
for i, line in enumerate(lines):
parts = line[:-1].split('t') # 使用[:-1]是把n去掉了
# print(parts)
label = parts[0]
sentence = parts[1]
aug_sentences = utils.all_trans(sentence)
for aug_sentence in aug_sentences:
writer.write(label + "t" + aug_sentence + 'n')
writer.close()
print("已生成增强语句!")
if __name__ == "__main__":
back_trans(args.input, args.output)
使用时,在终端调用命令,如
python code/augment.py --input train.txt --output train_aug.txt
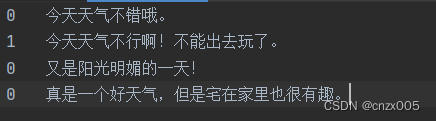
输入语料也有格式要求,如
0 今天天气不错哦。
1 今天天气不行啊!不能出去玩了。
0 又是阳光明媚的一天!
即,标签+一个制表符t+内容
即可运行,效果如下图所示
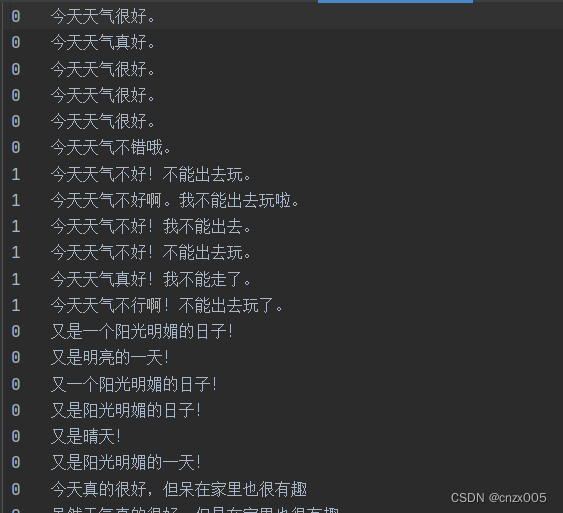
完整代码放github上了
代码地址
最后
以上就是沉默悟空最近收集整理的关于nlp数据增强-back translation的全部内容,更多相关nlp数据增强-back内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复