数据增强是扩充数据集的有效方法,本文介绍一种简单可行的 NLP 数据集扩充方法——回译,回译在文本分类中有比较好的效果,也被成功地用在 Kaggle 恶意评论分类比赛中。
1. 回译
上一篇文章《NLP 数据增强方法 EDA》介绍了一种 NLP 数据增强方法 EDA,本文介绍另一种简单的数据增强方法回译。回译指首先把句子翻译成另一种语言,然后再翻译回原来的语言。
原始句子:对面的女孩看过来
翻译成英文:The girl from the opposite looks over
回译:对面的女孩朝这边看了看
可以看到回译之后的句子和原始句子会存在不同,但是意思大体上一直。
2. 百度通用翻译 API
百度提供了通用翻译的 API,如下图所示。其中标准版是免费使用的,不限使用的字符量,但是每秒并发请求量是 1。通用翻译 API 地址:
http://api.fanyi.baidu.com/api/trans/product/prodinfo

百度通用翻译 API
点击下方的开始使用,然后注册成为开发者就可以获得 APPID。
在开发者信息查看 APPID 和密钥
得到 APPID 和密钥后可以通过 HTTP 接口获取翻译结果,需要通过翻译 API 传入待翻译的文本,源语言 (可自动识别) 和目标语言,即可得到翻译结果。
3. 代码
可以用下面的代码执行自动回译,用循环从文件中读取要回译的句子即可。注意事项:
- 在下面的代码中,使用的是百度通用翻译 API 的标准版,因此两个翻译请求之间需要等待一秒,否则会返回错误码,54003 (访问频率受限)。
- 需要输入自己的 appid 和 secretKey。
详细的可参考通用翻译 API 的技术文档,地址: http://api.fanyi.baidu.com/api/trans/product/apidoc#joinFile
# coding=utf-8import http.clientimport hashlibimport urllibimport randomimport jsonimport timeappid = '' # 填写你的appidsecretKey = '' # 填写你的密钥httpClient = Nonemyurl = '/api/trans/vip/translate'ChineseLang = 'zh' # 原文语种,填写中文 (zh),也可自动识别 (填auto)EnglishLang = 'en' # 译文语种,填英文 (en)for i in range(2): query = input('请输入要回译的句子: ') # 可以从数据集中读取 try: httpClient = http.client.HTTPConnection('api.fanyi.baidu.com') # 翻译成英文,from=ChineseLang,to=EnglishLang salt = random.randint(32768, 65536) sign = appid + query + str(salt) + secretKey sign = hashlib.md5(sign.encode()).hexdigest() first_url = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(query) + '&from=' + ChineseLang + '&to=' + EnglishLang + '&s&sign=' + sign httpClient.request('GET', first_url) response = httpClient.getresponse() result_all = response.read().decode("utf-8") english_result = json.loads(result_all) english_result = english_result['trans_result'][0]['dst'] print('翻译结果: ', english_result) # 本人使用的是通用翻译 API 的标准版,请求之间要限制频率,等待一秒 time.sleep(1) # 翻译回中文,from=EnglishLang,to=ChineseLang salt = random.randint(32768, 65536) sign = appid + english_result + str(salt) + secretKey sign = hashlib.md5(sign.encode()).hexdigest() second_url = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(english_result) + '&from=' + EnglishLang + '&to=' + ChineseLang + '&s&sign=' + sign httpClient.request('GET', second_url) response = httpClient.getresponse() result_all = response.read().decode("utf-8") chinese_result = json.loads(result_all) chinese_result = chinese_result['trans_result'][0]['dst'] print('回译结果: ', chinese_result) except Exception as e: print(e) finally: if httpClient: httpClient.close()运行效果如下图所示
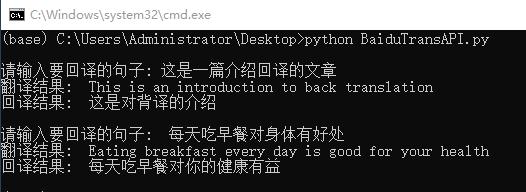
运行效果
4. 总结
- 通过回译可以比较好的增加文本的多样性,有时可以在改变语法结构的情况下保留正确的语义信息。
- 但是回译依赖于翻译的质量,可能会有不少文本的翻译结果不准确。
5. 参考文献
百度通用翻译 API 技术文档
最后
以上就是笨笨嚓茶最近收集整理的关于数据增强_NLP 数据增强方法回译1. 回译2. 百度通用翻译 API3. 代码4. 总结5. 参考文献的全部内容,更多相关数据增强_NLP内容请搜索靠谱客的其他文章。








发表评论 取消回复