Abstractive Summarization: A Survey of the State of the Art
Conference: AAAI 2019
Authors:Hui Lin, Vincent Ng
Human Language Technology Research Institute University of Texas at Dallas Richardson, TX 75083–0688 {hui,vince}@.hlt.utdallas.edu
论文链接:https://www.aaai.org/ojs/index.php/AAAI/article/view/5056
文本摘要可以分为两个种类:
- 抽取式摘要-从原始文档中选取句子
- 生成式(抽象式)摘要-创建输入文本的抽象表达,然后通过自然语言成生的方法生成摘要
这篇Paper主要用于对生成式摘要进行汇总和分析
1、评估方法
用于评估生成摘要的方法可以分为两种:
-
manual evaluation
- 人工判断摘要的质量
- 评价维度:accurcy,clarity,completeness
-
automatic evaluation
- 使用评估矩阵
- BLEU
- METEOR
- Pyramid
- ROUGE
2.数据集
通常在文本摘要任务中会使用如下的数据集。
-
DUC
- Document Understanding Conference (DUC) (2000–2007)
- 英文报纸和新闻文章的摘要
- 这些语料库相对较小,它们不能提供训练神经模型通常需要的足够数据
-
Annotated English Gigaword Annotated
- 2015年发表,相比较于DUC,数据集较大
- 它包含了过去二十年来来自各种国际外新闻机构的近1000万份文档(超过40亿字),为训练神经模型提供了丰富的数据。
- 使用文章的第一句作为源,其标题作为摘要,从每篇文章中自动创建一个source-summary对。
-
CNN/Daily Mail
- Nallapati等人(2016)对CNN/《每日邮报》语料库中的每一篇报道进行了人为的总结。
- 该语料库有286,817对训练对、13,368对验证对和11,487对测试对,广泛应用于许多抽象摘要任务。
- 该语料库不仅提供了丰富的训练数据,还提出了两个值得研究的点:
- 首先,与Gigaword和DUC的文档相比,CNN/Daily Mail的文档要长得多(平均781个token),因此产生了一个比较具有挑战性的摘要任务。
- 其次,与Gigaword不同的是,CNN/Daily Mail包含了多句摘要(平均3.75句或56个token),因此能够刺激从长文档中生成多句摘要的研究。
3.神经网络的方法
在经典的生成摘要方法中,信息提取(information extraction),内容选择(content selection)和文章实现(surface realization)都是具有挑战性的子任务。相比之下,神经方法提供了一种端到端抽象摘要的方法,学习如何从源文档中抽象并在一个网络中生成相应的摘要。
3.1 Encoder-Decoder框架
现有的绝大多数神经抽象摘要模型都是序列到序列(seq2seq)模型,采用了编码器-解码器架构(Sutskever et al. 2014)。该体系结构由编码器和解码器组成。编码器将源句子编码为一列固定长度的向量表示,每个表示捕获一个单词及其周围的上下文。然后,解码器根据编码的向量输出摘要。该体系结构在文档-摘要对上联合训练,以最大限度地提高每个输入文档的正确摘要的概率。
3.1.1 编码
类似于信息抽取的过程,捕捉与摘要生成的相关信息。此过程主要关注两个方面:
- (1) data preprocessing
- (2) encoder selection
Preprocessing
通常会选择以单词为单位进行编码,但是在某些语言上会因为避免分词导致的误差而选择以字符为单位进行编码,比如汉语。
对于较长的文本,也可以预先抽取文本使得整体变得比较紧凑后再进行编码。(Chen and Bansal 2018; Hsu et al. 2018; Lebanoff et al. 2018).
最近也有人尝试利用从知识库中提取的背景知识来改进抽象摘要。例如,Amplayo等人(2018)在输入文档中提取关于实体的额外知识(例如足球队赢得的比赛),然后利用由此获得的外部知识引导解码器生成更好的摘要。
Encoder selection
为了更好地学习输入文本的抽象表示,控制从编码器到译码器的信息流,一些研究者将重点放在了编码器的选择和设计上。
Rush et al.(2015)以卷积神经网络(CNN)作为编码器,前馈神经网络作为解码器构建其编解码器体系结构。在最近的方法中,cnn通常被回归神经网络(RNNs)所取代,部分原因是CNNs缺乏处理长序列的能力(Chopra et al. 2016;Nallapati等(2016)。通常选取的是LSTM网络。
在某些情况下,GRUs (Cho et al. 2014)被证明是LSTMs的更好选择(Chen et al. 2016;Kim等人2016年;Li et al. 2017;(Chung et al. 2014),因为他们的参数更少,在达到可比结果的同时训练速度更快(Chung et al. 2014);(Greff等,2017)。
最近关于编码的研究专注于设计复杂的网络,以利用长文档中的现有信息(C¸elikyilmaz等人2018; Cohan等人2018)。尽管如此,如何编码长序列仍然是seq2seq模型中的一个悬而未决的问题。
3.1.2 解码
通常使用RNN实现解码器。 在每个时间步,RNN将两个向量(先前生成的单词的表示和通过编码步骤获得的输入序列的表示)作为输入,并生成一个与词汇量匹配的向量,随后使用softmax层将其转换为在词汇表上的分布。
给定这种分布,要么生成最有可能的单词作为输出,要么更常见的是,通过波束搜索(Beam Search)来确定到该时间步长为止的k个最佳路径,其中k是波束大小(Rush等人,2015; Chopra等人2016; Nallapati等人2016; Paulus等人2017;请参见等人2017)。
3.2 Encoder-Decoder框架的改进
3.2.1 Attention
在文档中某些单词/短语比其他单词/短语更重要。 这些重要的单词/短语比不太重要的单词/短语更容易出现在摘要中。 要识别重要的单词/短语,可以利用注意力方法。
注意力背后的关键思想是向解码器提供额外的输入向量(称为上下文向量),用于编码重要的短语(Bahdanau et al. 2014)。在较高的层次上,可以首先使用注意力来计算每个时间步中每个元素的权重,以指示其重要性,然后可以使用在元素上产生的权重分布来计算上下文向量。从直观上看,上下文向量放大了到目前为止处理过的输入中的有用信息(即注意力分布中与高权重相关的信息),而对不重要的信息(即注意力分布中与低权重相关的信息)不强调。
根据我们使用的是全局注意(句子级)还是局部注意(单词级),产生的神经模型具有检索文档不同级别重要信息的能力。
3.2.2 Distraction/Coverage
虽然注意力使我们能够识别和关注重要的短语,但它也不是没有问题。研究人员发现,同一区域/内容可能过于集中,从而导致摘要冗余。分散注意力可以用来避免专注于同一内容(Nema等人,2017年)。其思想是使用一个约束来减少重复内容的概率或与该内容相关的权重。
虽然注意力使我们能够识别和关注重要的短语,但它也不是没有问题。研究人员发现,同一区域/内容可能过于集中,从而导致摘要冗余。分散注意力可以用来避免专注于同一内容(Nema等人,2017年)。其思想是使用一个约束来减少重复内容的概率或与该内容相关的权重。
Chen et al.(2016)表明,分散注意力可以应用于上下文向量、注意力权重向量和解码,尽管分散注意力的应用并不局限于这三个地方。例如,在训练步骤中,他们通过从当前的上下文向量中减去历史上下文向量来实现分散注意力,有效地分散网络对之前关注过的内容的注意力。
一些研究者将分心称为覆盖(See et al. 2017)。覆盖度这个概念起源于统计机器翻译(Koehn et al. 2007),随后被Tu et al.(2016)用于神经机器翻译。参见等人(2017)对承保损失的定义,与原始损失相比,承保损失对重复有额外的惩罚条款(即,更多的重复意味着更少的承保)。
3.3.3 Pointer networks / Copy mechanism
经常出现的词很可能被一个注意机制识别为重要的词。相比之下,众所周知,神经序列模型缺乏生成罕见词和词汇外词的能力,即使生成的上下文使预测没有歧义。为了解决这个问题,Vinyals等人(2015)提出了一种指针网络,它将一个元素从输入直接复制到输出。更一般地,指针可以被看作是注意力的延伸,它允许我们关注那些罕见的或重要的OOV词。
3.3.4 Reinforcement learning
编码器-解码器框架有两个缺点。
- 首先,当网络被训练以最大限度地生成正确摘要的概率时,生成的摘要被自动度量如ROUGE评估。换句话说,最小化最大似然(ML)损失不一定等同于优化所需的评估指标。
- 其次,在对解码器进行摘要训练时,它会使用测试时间中最后一个时间步生成的摘要对下一个单词进行解码。 换句话说,解码性能会受到这种曝光偏差的不利影响(Ranzato等人,2015年)。
为了解决这些问题,研究人员最近利用了强化学习(RL)(Paulus等人2017; Pasunuru and Bansal 2018)。 RL使我们能够训练代理与特定环境进行交互,从而最大化回报。
4. The State of the Art
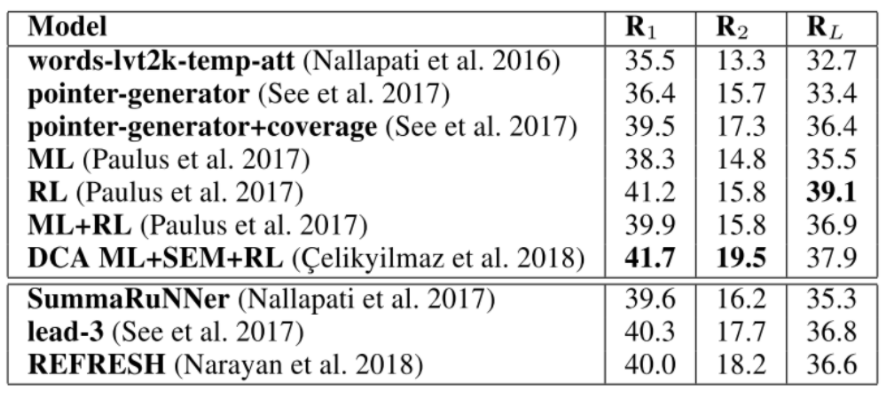
上表中显示了近年来最频繁使用的评估语料库CNN/Daily Mail数据集上最先进的摘要器的ROUGE得分。有几项观察值得提及。
-
首先,与编码器-解码器RNN的指针组件被训练为仅针对OOV单词和命名实体(第1行)进行激活相比,指针-生成器网络可以自由地学习何时使用指针(第2行),特别是当与覆盖率(第3行)结合使用,可获得更好的结果。
-
其次,比较使用RL(第5行)的模型和使用ML目标(第4行)的模型,RL有助于在句子层面生成更好的总结,获得最高的ROUGE-L分数。
-
第三,有人尝试将ML和RL组合在一起:根据它们组合的方式,结果系统的性能可能会提高(第7行)或降低(第6行)。
- 一个原因是,提取摘要器做出句子级决策,这使得创建的摘要比抽象摘要更具可读性。然而,如果在句子层面上做决定也会使他们很难记住所有重要的内容,如果这些内容分散在输入文本中。
- 这可以解释为什么提取摘要器不如基于RL的抽象性摘要器:RL可以解决抽象性摘要器在做句子级决策时的弱点。
最后
以上就是和谐春天最近收集整理的关于【论文阅读 - AAAI 2019】Abstractive Summarization: A Survey of the State of the Art1、评估方法2.数据集3.神经网络的方法4. The State of the Art的全部内容,更多相关【论文阅读内容请搜索靠谱客的其他文章。








发表评论 取消回复