Transformer-XL学习笔记
一、Transformer-XL出现的原因
首先说明Transformer的变形版本Transformer-XL出现的原因:
transformer作为一种特提取器,在NLP中有广泛的应用,但是transformer需要对输入的序列设置固定的长度,例如在Bert中,默认设置长度为512,若文本序列长度小于固定长度,可以通过填充0的方式补充序列;若文本序列长度大于固定长度,则会采用不同的处理方式。一种是:在处理时将文本划分为多个segments,训练模型时将对每个segment单独处理,segment之间没有联系(如图1a)。
这样导致的问题是:(1) segment之间独立训练,不同的token之间,最长的依赖关系取决于segment的长度;(2) 由于考虑到效率,在划分segments时,不考虑句子的自然边界,而是根据固定的长度来划分序列,导致分割出来的segments在语义上不是完整的。
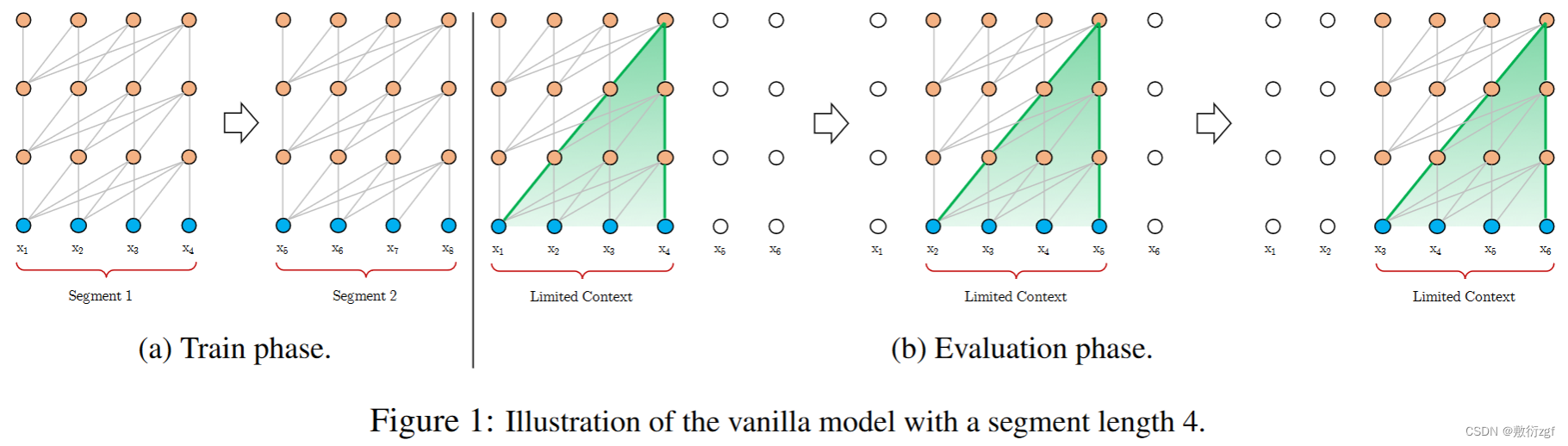
如图1(a) 所示,对于所有的文本序列,我们都可以将其以4作为长度划分成无数的segments,对于每一个segments都可以独立做attention。那么导致的问题是,若x4与x5在文本序列中,语义是连贯的,在划分过后,就会导致训练时连贯的语义被切割。
对此提出的稍微改进是图1(b)部分,在模型预测时,会对固定长度的segment做计算,一般取最后一个位置的隐向量作为输出,为了充分利用上下文关系,在每做完一次预测之后,就对整个序列向右移动一个位置,在做一次计算。每一次的移动步长为1,滑动窗口大小为4,每一步学习的过程中都可以将前三步的信息考虑在内。但缺点是:并没有从根本上改变连贯语义被分割的问题;同时模型计算量巨大。
二、Segment-Level Recurrence(片段级递归机制)
为了解决上面提到的问题,在Transformer的基础上,Transformer-XL提出了一个改进是在对当前segment进行处理时,缓存并利用上一个segment中所有的layer的隐向量序列,而且上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播,这就是所谓的Segment-Level Recurrence
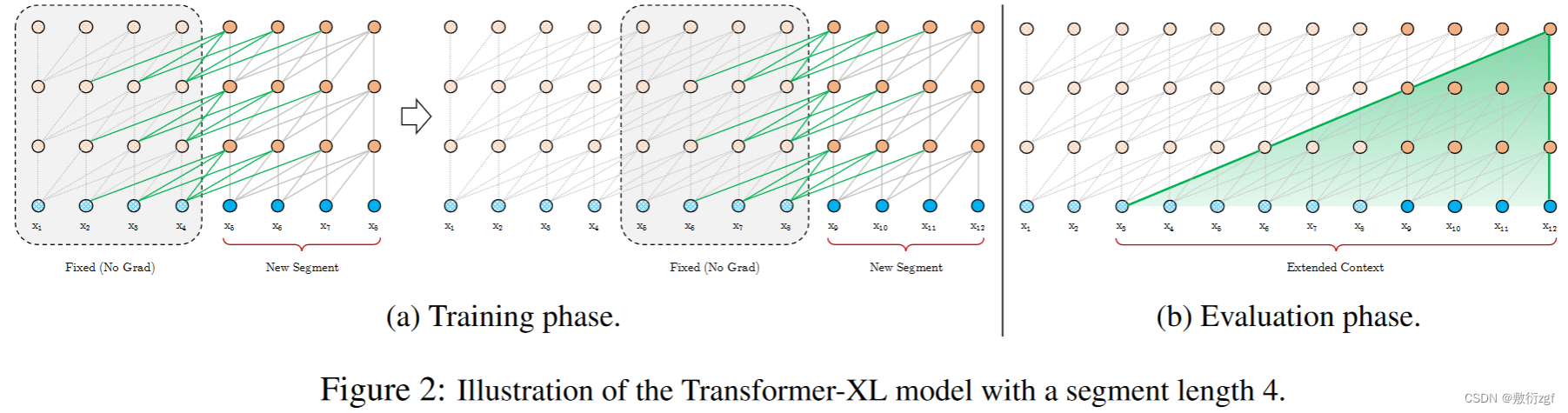
在上面的描述中只保存了一个segment,实际操作过程中,可以保存尽可能多的segments,只要内存或者显存放得下,在论文中作者训练时只缓存了一个segment,在进行预测时,会缓存多个segments。
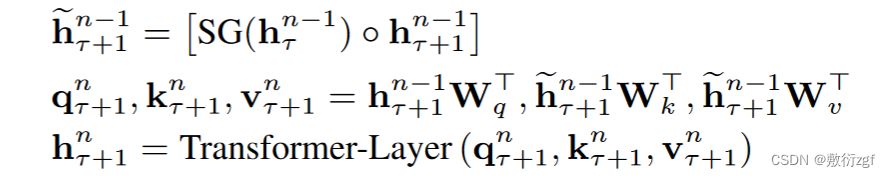
Transformer本身可以设置multi-heads,将两个连续的segments表示为sτ=[xτ,1,xτ,2,……,xτ,L],sτ+1=[xτ+1,1,xτ+1,2,……,xτ+1,L],L表示序列长度。在整个模型中,包含N层Transformer,那么每一个segment中就有N组长度为L的隐向量序列,将第τ个segment的第n层隐向量序列表示为hτn∈RL×d,d是隐向量的维度。那么第τ+1个segment的第n层隐向量序列可以通过上述的计算公式得出,SG表示Stop-gradient,不再对sτ的隐向量做反向传播。
三、Relative Positional Encodings(相对位置编码)
在实现片段级递归时遇到一个问题:如果采用绝对位置编码,不同片段的位置编码是一样的,这很显然是不对的。公式如下:
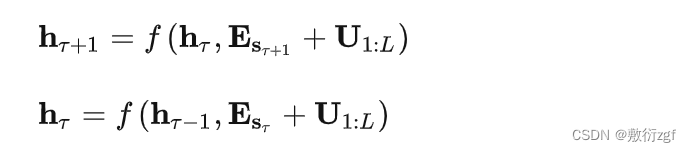
ESτ表示片段Sτ的词向量,U1:L表示绝对位置向量,可以看出两个片段之间所用到的位置向量是一样的,如果一个词出现在两个片段中xτ,j、xτ+1,j,按照绝对位置编码方式,他们的表示向量是一样的,难以区分。论文引入相对位置编码机制,计算self-attention公式如下: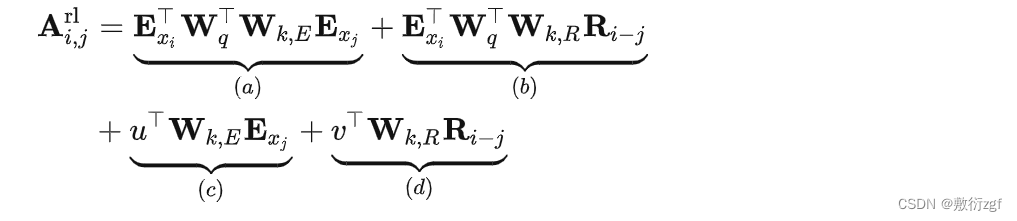
- 引入相对位置编码,用的是Transformer中的sinusoid encoding matrix,不需要模型自己学习;
- μ和ν是需要学习的参数,计算self-attention时,由于query所有位置对应的query向量是一样的,因此不管query的位置如何,对不同单词的attention偏差应保持相同。
- Wk,E、Wk,R也是需要学习的参数,分别产生基于内容的key向量和基于位置的key向量
最后经过Masked-Softmax、Layer-Normalization、Positionwise-Feed-Forward得最终的预测结果。
四、结论
Transformer-XL从提高语言模型的长距离依赖建模能力出发,提出了片段级递归机制,设计了更好的相对位置编码机制,对长文本的编码更有效。不仅如此,在评估阶段速度更快,很巧妙。在此基础上,XLNet从无监督预训练方法出发,对比自回归语言模型和自编码语言模型的优缺点,设计出了排队语言模型,在自然语言处理下游任务中大放异彩。预训练语言模型属于自监督学习的范畴,这两篇论文从语言模型的根本问题出发(建模长距离依赖/更好地编码上下文),提出一个主要方法(片段级递归机制/排列语言模型),在实现过程中发现需要重新设计子模块(相对位置编码/双流注意力机制),最后完成significant work,使得设计的任务很有说服力,理论性强。
最后
以上就是甜蜜萝莉最近收集整理的关于Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context_学习笔记的全部内容,更多相关Transformer-XL:内容请搜索靠谱客的其他文章。


![[论文阅读]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context前言摘要1、Introduction & Motivation2、How to do ?3、Experiments Analysis(main)总结](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)





发表评论 取消回复