Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
前记: 【预训练语言模型】系列文章是对近几年经典的预训练语言模型论文进行整理概述,帮助大家对预训练模型进行全局的理解。本系列文章将不断更新,敬请关注博主。本文分享一个对Transformer进行改进的模型Transformer-XL,其认为原始的Transformer在处理超过预定长度的文本采用分段(chunk)策略,但各个片段(segment)独立地训练,忽略了segment之间的语义信息传递使得不能够充分解决长距离依赖问题。
开源:https://github.com/kimiyoung/transformer-xl
一、摘要:
Transformer在学习长距离依赖问题上有巨大的潜力,但是其由于语言模型的设置而限定于固定长度的文本。我们提出了一种新的神经网络架构Transformer-XL,其可以学习到超出固定长度的依赖,不中断时间相关性(without disrupting termporla coherence)。我们的方法不仅可以捕捉长距离依赖,也可以解决文本分段问题。因此,Transformer-XL可以学习到的依赖的长度比RNN高80%,比原始的Transformer长450%,在长或短的文本上有很好的表现。
二、动机:
- 语言模型中存在的一个重要的问题就是长距离依赖问题;
- RNN为代表的方法存在着长距离依赖问题,串行的计算整个序列使得其容易遭受梯度消失或梯度爆炸,带有门控单元的LSTM也不能完全解决这个问题;
- 现如今的以Transformer为主的语言模型不能很好地处理超过预定义长度的文本。即模型不能捕获任何超过预定义上下文长度的长期依赖
在现如今包括BERT在内的一些以Transformer的方法中,预定义的序列长度为512。当输入序列不足512个字符时,则通过填充0的方式;如果超过512,则会将整个序列进行分段(segment),并对分好的段分别独立地处理。因为分段的处理使得段之间失去了语义的传递,然而理想状态下,那些段的边界部分的语义和依赖应该来自于相邻的段。先前的方法都忽略了这些,也就是作者认为的不能够处理超过预定义长度的长距离依赖
三、方法:
- 为了解决上述的问题,我们提出一种Transformer-XL模型。具体地,在对超过预定义长度的文本分段后,对于每一段不是独立的训练,当前段的隐状态信息则充分利用来自于前一个分段,并当做一个记忆memory,因此这样每个段之间都可以完成信息的传递,从而缓解超过固定大小的文本的长距离依赖问题
- 我们介绍了一种简单但更有效的相对位置编码方式,该方式可以将注意力长于训练期间观察到的长度。
四、贡献:
- 在self-attention模型中引入一种递归的概念,以缓解长距离依赖问题;
- 提出一种新的相对位置表征方案;
- 两个模型结合起来可以解决提出的问题,Transformer-XL是第一个自注意力模型并可以在字符或词级别上超越RNN获得显著提升的方法
五、Vanilla Transformer:
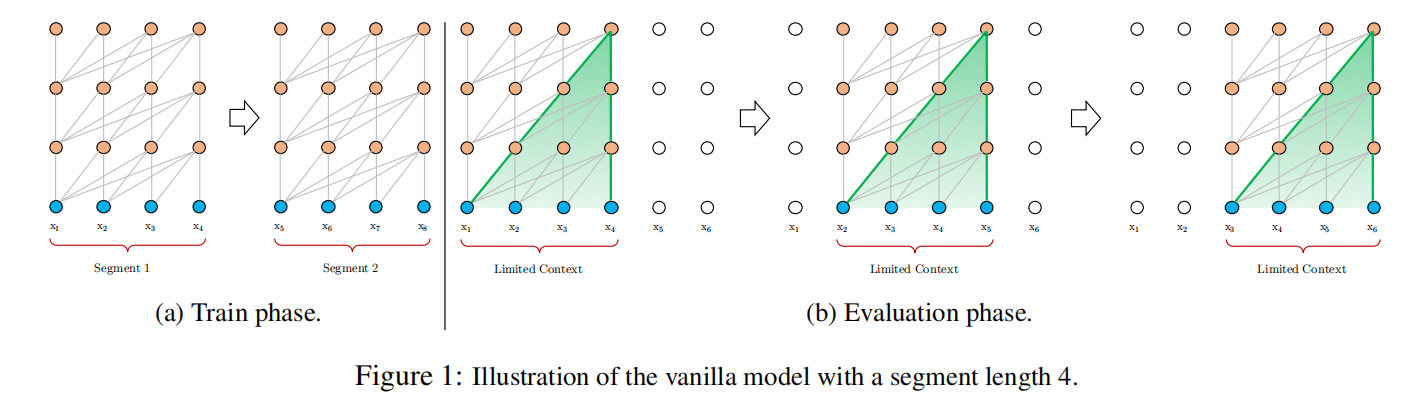
如上图(a),Transformer通常是将长文本划分为独立的片段,并独立的进行训练。在这种情况下,片段之间的依赖信息是不会存在传递的。即简单的chunk(分片)机制会导致上下文出现语义碎片化的问题。
如上图(b),依然是固定长度,但是每次通过向右移动一个单位位置来捕捉当前范围内的长距离依赖,这种方法可以缓解上面提出的问题,但是计算复杂度过高
六、Segment-Level Recurrence with State Reuse
为了解决上述提出的问题,我们将递归机制引入到Transformer中。简单的来说,当计算当前segment段时,将前面的segment的隐状态固定保存下来(保存下来作为memory),并参与到当前segment的计算。由于分段是在事先完成的,因此此时的梯度无法完成传递,但是可以通过保存隐状态向量。这样模型可以在学习当前段的信息是时,充分挖掘历史信息。
形式化的描述,假设模型包含 n n n 层隐层,当前是第 τ tau τ 个分段,每个分段长度为 L L L 。则第 n n n 层 τ + 1 tau +1 τ+1 个分段的隐状态向量可计算为:
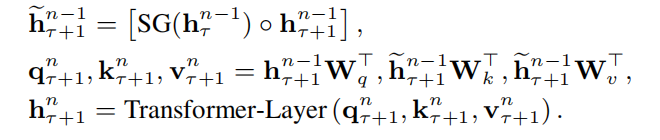
其中
S
G
SG
SG 表示无梯度。上面说了,前一个片段只能保留对应的隐状态,但无法实现梯度传递,因此在当前segment的训练时,无须计算这个梯度。整个计算可视化如下图(a):
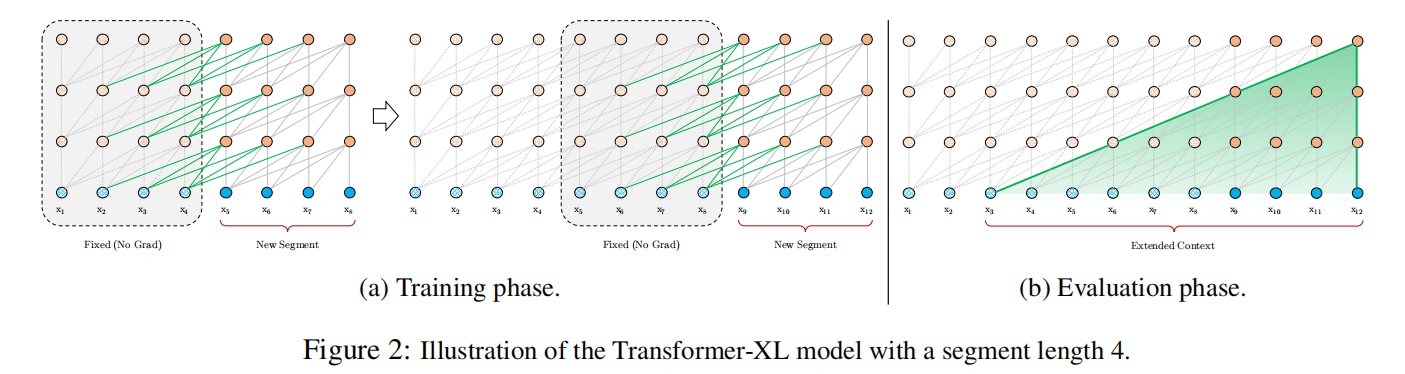
默认情况下,我们可以只保存前一个segment,如果GPU显存和内存允许,则可以保存多个segment隐状态向量
七、Relative Postional Encodings
Transformer结构中,为了让模型记住不同token的位置信息,使用了绝对位置表征,并将其与word embedding求和(或拼接等)方式进行前向传播计算。然而对于分段来说,不同segment的相同的位置,对应的位置表征也是一样的(例如两个片段 x t a u , j x_{tau, j} xtau,j 和 x t a u + 1 , j x_{tau +1, j} xtau+1,j 对应的是第 j j j 个位置的表征向量是一样的),这样模型无法识别当前位置是属于哪一个segment。
因此,我们只使用相对位置。当query的token是 q t a u , i q_{tau,i} qtau,i ,如果其要和某个token k τ , j ( j ≤ i ) k_{tau,j}(jleq i) kτ,j(j≤i) 计算attention,则只需要使用将它们的相对位置 i − j i-j i−j 对应的位置表征向量。这样就可以区分不同segment之间处于相同绝对位置的token了。作者认为,相对位置不会损失一些位置信息,因为其是可以推出绝对位置的。
如何将位置表征融入到attention的计算中呢?传统标准的Transformer的方法如下所示:
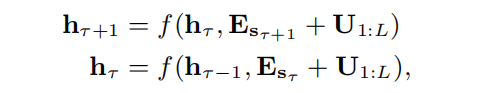
即直接将绝对位置信息 U U U 与词向量 E E E 进行拼接。作者为了提高attention计算的泛化能力,将其进行了分解,如下所示:
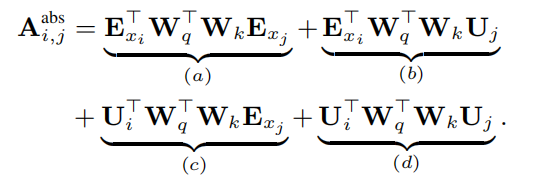
由于作者提出了新的相对位置,因此将绝对位置 U U U 进行了替换:
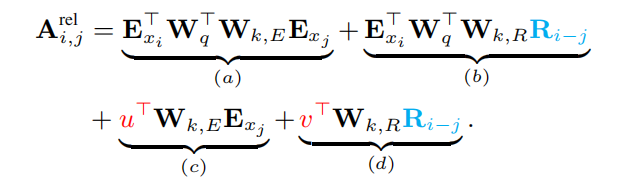
很显然:
(1)如果query的位置是
i
i
i ,key的位置是
j
j
j ,则相对位置为
i
−
j
i-j
i−j ,对应的向量是
R
i
−
j
R_{i-j}
Ri−j ;
(2)将
U
i
T
W
q
T
U_{i}^T W_{q}^T
UiTWqT 更换为
u
u
u 或
v
v
v 。作者认为,当某个query与其他的key进行计算attention时,其位置是不变的,因此在对不同位置进行计算attention时应该使用同一个位置信息。
(3)(a)部分表示上下文、(b)表示上下文与位置的偏向、(c)表示全局上下文偏向、(d)表示全局位置偏向。
总的来看,Transformer-XL架构可总结为:

实验细节:
(1)作者在word-level和character-level的语言模型上进行了实验,数据集包括WikiText-103,enwik8,text8,One Billion Word,Penn Treebank。并分别在这四个数据集上与baseline进行对比。
(2)消融实验,分别验证提出的两个改进点(recurrence mechanism和position encoding)的作用。
对于本文如若有疑难,错误或建议可至评论区或窗口私聊,【预训练语言模型】 系列文章将不断更新中,帮助大家梳理现阶段预训练模型及其重点。
最后
以上就是无聊抽屉最近收集整理的关于【预训练语言模型】Transformer-XL: Attentive Language Models Beyond a Fixed-Length ContextTransformer-XL: Attentive Language Models Beyond a Fixed-Length Context的全部内容,更多相关【预训练语言模型】Transformer-XL:内容请搜索靠谱客的其他文章。
![[Z]Creating an OpenGL Context](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)


![[论文阅读]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context前言摘要1、Introduction & Motivation2、How to do ?3、Experiments Analysis(main)总结](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)




发表评论 取消回复