作者:韩
单位:燕山大学
论文地址:https://arxiv.org/pdf/1901.02860.pdf
代码地址:https://github.com/kimiyoung/transformer-xl
目录
- 一、Transformer
- 二、vanilla Transformer
- 三、Transformer-XL
-
- 3.1 片段级递归机制
- 3.2 相对位置编码机制
- 四、实验分析
- 五、总结
一、Transformer
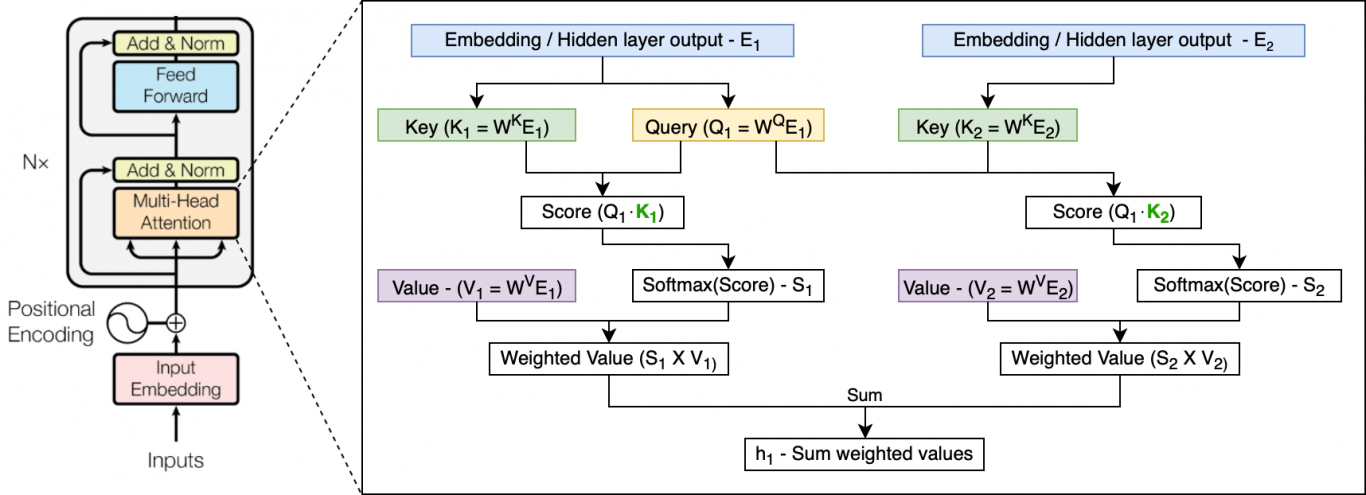
目前在NLP领域中,处理语言建模问题最先进的基础架构即Transformer。2017年6月,Google Brain在论文《Attention Is All You Need》中提出了Transformer架构,其模型设计完全摒弃了RNN的循环机制,采用一种self-attention的方式进行全局处理。接收一整段文本序列,并使用三个可训练的权重矩阵——Query、Key和Value来一次性学习输入序列中各个部分之间的依赖关系。因此解决了RNN中的长距离依赖、无法并行计算的缺点,也解决了CNN中远距离特征捕获难的问题。
Transformer网络由多个层组成,每个层都由多头注意力机制和前馈网络构成。由于在全局进行注意力机制的计算,忽略了序列中最重要的位置信息。因此Transformer为输入添加了位置编码(Positional Encoding),使用正余弦函数为每个部分生成位置向量,用于帮助网络学习其位置信息。其结构如下图所示:
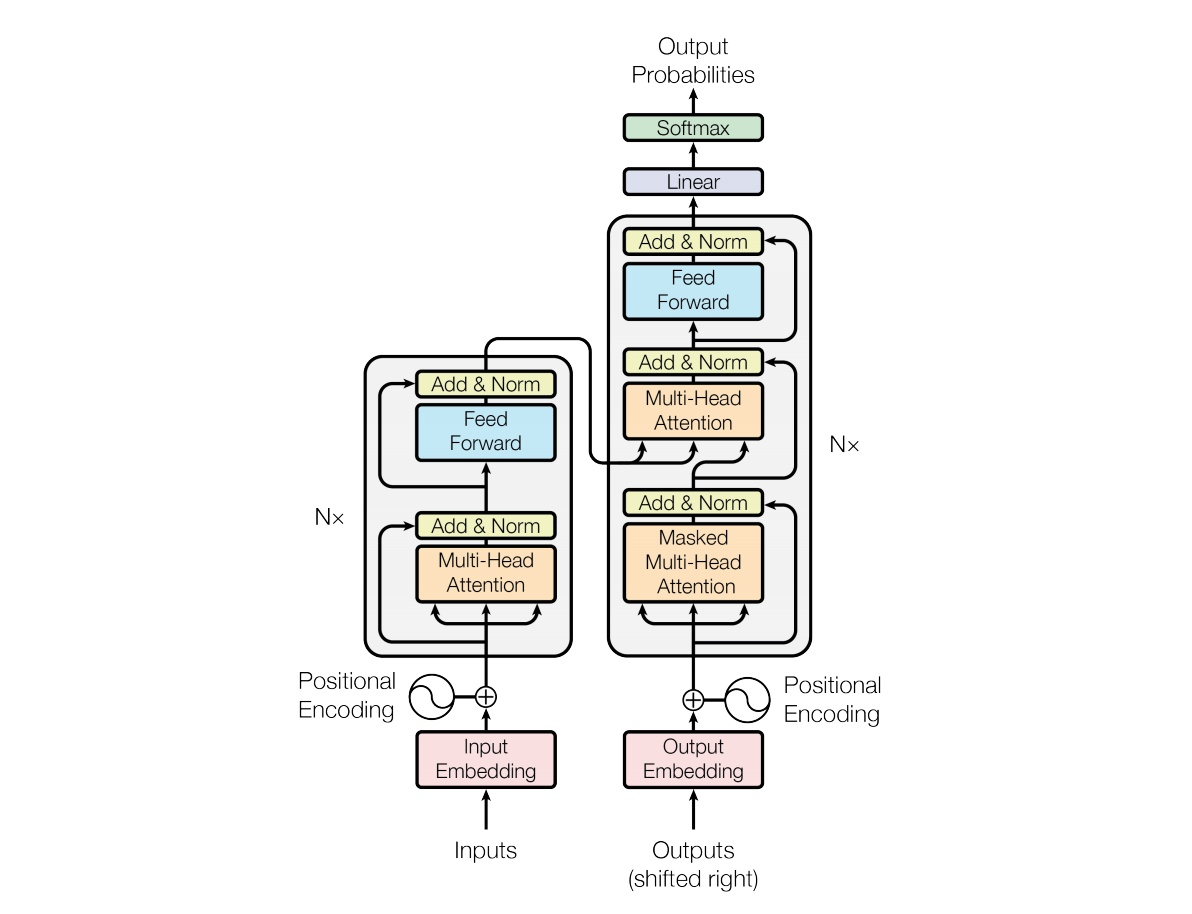
这种架构目前来看已经取得了令人瞩目的成就,但其存在的缺点也极为明显:
- 首先在理论上Transformer模型可以学习到输入文本的长距离依赖关系和全局特性,但在语言建模中受到固定长度上下文的限制,一般默认设置的最大序列长度为512,因此Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。
- 其次在处理长文本时传统的做法为对输入的文本进行分段,即将文本划分为多个segment,将每一个segment分别进行计算,这就造成了每个segment之间没有任何的信息交互进而导致上下文碎片化(context fragmentation)。
二、vanilla Transformer
2018年Al-Rfou等人基于Transformer提出了一种训练语言模型的方法《Character-Level Language Modeling with Deeper Self-Attention》,根据之前的字符预测序列中的下一个字符。例如:它使用 x 1 , x 2 , . . . , x n − 1 x_1,x_2,...,x_{n-1} x1,x2,...,xn−1预测字符 x n x_n xn
最后
以上就是留胡子银耳汤最近收集整理的关于论文笔记 | Transformer-XL:Attentive Language Models Beyond a Fixed-Length Context一、Transformer二、vanilla Transformer三、Transformer-XL四、实验分析五、总结的全部内容,更多相关论文笔记内容请搜索靠谱客的其他文章。
![[论文阅读]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context前言摘要1、Introduction & Motivation2、How to do ?3、Experiments Analysis(main)总结](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)







发表评论 取消回复