文章目录
- Vanilla Transformer Language Models
- Segment-Level Recurrence with State Reuse
- Relative Positional Encodings
Reference
1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
2. Transformer-XL: Unleashing the Potential of Attention Models
3. Transformer-XL介绍
代码基于tensorlfow2.3实现,仓库地址:https://github.com/dwdb/transformer-xl
Transformers潜在地学习长期依赖,但受到上下文固定长度限制,当处理序列长度超过固定长度时,会出现以下问题:
- 训练阶段,需将输入文本分割成不同分段,不同分段独立训练,由于分段未考虑语义边界,可能造成模型缺乏上下文信息学习分段的完整表示,模型不易优化,这种现象称为上下文碎片问题;
- 预测阶段,每次移动一个输入单元,引入大量重复计算,预测效率低;
Transformer-XL使用两种技术: 循环分段 和 相对位置编码,克服vanilla Transformers的缺陷,并解决上下文碎片问题。使用循环分段机制,在处理当前分段时,重用之前分段的隐状态(缓存),可不是从头计算新分段的隐状态,不同分段之间不再独立,解决了上下文碎片的问题。使用相对位置编码,而非绝对位置编码,避免利用之前分段隐状态造成的时序混乱问题。
实验结果表明,Transformer-XL在学习上下文依赖上,比RNNs网络长0.8倍、比vanilla Transformers网络长4.5倍,Transformer-XL是首个在字和词级别上均优于RNNs的使用自我注意力的模型。
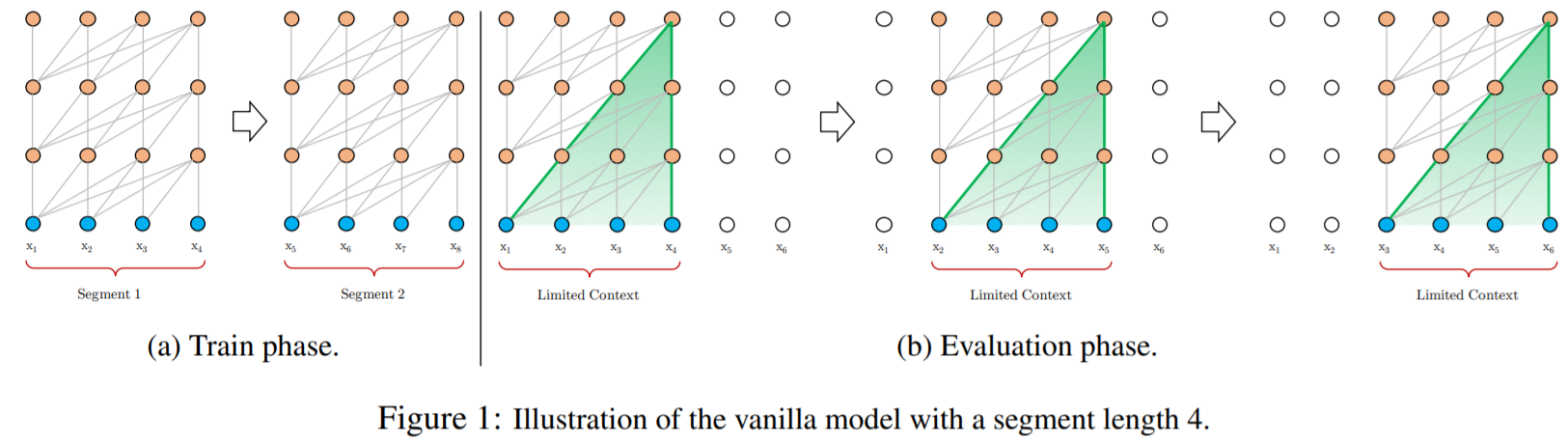
Vanilla Transformer Language Models
使用Transformer或者self-attention的语言模型,最核心问题是怎样把任意长、具有上下文信息的序列编码为固定长度的向量表示。有限的计算资源下,无法处理较长序列,可行地做法是将长序列分割成数个固定长度序列,各分段独立训练,忽略各分段间的语义关系,随意分割会造成上下文碎片。
Segment-Level Recurrence with State Reuse
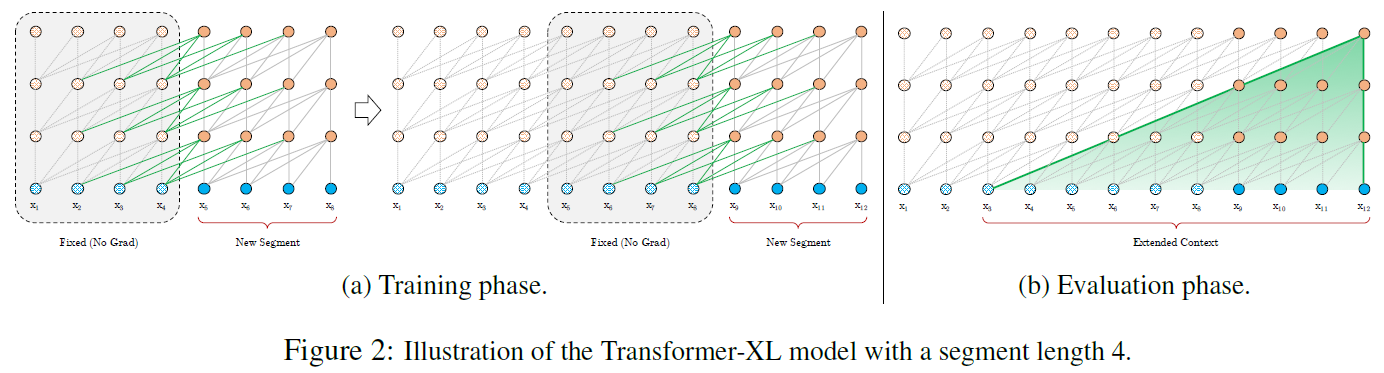
训练阶段,缓存一定长度的之前片段的各层隐状态向量,在处理新分段时,缓存向量作为新分段的扩展上下文重用,使得模型可以学习长期依赖,以避免学习上下文碎片。
对于两个连续分段
s
τ
=
[
x
τ
,
1
,
⋯
,
x
τ
,
L
]
s_{tau}=[x_{tau,1},cdots,x_{tau,L}]
sτ=[xτ,1,⋯,xτ,L]和
s
τ
+
1
=
[
x
τ
+
1
,
1
,
⋯
,
x
τ
+
1
,
L
]
s_{tau+1}=[x_{tau+1,1},cdots,x_{tau+1,L}]
sτ+1=[xτ+1,1,⋯,xτ+1,L],
s
τ
s_tau
sτ在第
n
n
n层的隐状态为
h
τ
n
∈
R
L
×
d
bm h_{tau}^ninR^{Ltimes d}
hτn∈RL×d,其中
d
d
d是隐状态向量维度,则
h
~
τ
+
1
n
−
1
=
[
SG
(
h
τ
n
−
1
)
∘
h
τ
+
1
n
−
1
]
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
=
h
τ
+
1
n
−
1
W
q
⊤
,
h
~
τ
+
1
n
−
1
W
k
⊤
,
h
~
τ
+
1
n
−
1
W
v
⊤
h
τ
+
1
n
=
Transformer-Layer
(
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
)
begin{aligned} &tildebm h_{tau+1}^{n-1}=[text{SG}(bm h_{tau}^{n-1})circbm h_{tau+1}^{n-1}]\[1ex] &bm q_{tau+1}^n,bm k_{tau+1}^n,bm v_{tau+1}^n=bm h_{tau+1}^{n-1}W_q^top,tildebm h_{tau+1}^{n-1}W_k^top,tildebm h_{tau+1}^{n-1}W_v^top\[1ex] &bm h_{tau+1}^n=text{Transformer-Layer}(bm q_{tau+1}^n,bm k_{tau+1}^n,bm v_{tau+1}^n) end{aligned}
h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1]qτ+1n,kτ+1n,vτ+1n=hτ+1n−1Wq⊤,h~τ+1n−1Wk⊤,h~τ+1n−1Wv⊤hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)
式中函数 SG ( ⋅ ) text{SG}(cdot) SG(⋅)表示不计算梯度, [ h u ∘ h v ] [bm h_ucirc bm h_v] [hu∘hv]表示序列长度方向拼接两个隐藏状态序列。
循环分段状态重用与标准Tranformer最大的不同在于,利用当前分段的 q bm q q向量,以及之前分段和当前分段的 k bm k k和 v bm v v向量,计算当前分段的Transformer层输出,使得当前分段输出考虑到之前分段信息(self-attention注意之前分段)。
从图二左图中可看出,在训练阶段当仅利用前一个分段信息时,两个分段的不同层的隐状态 h τ + 1 n bm h_{tau+1}^n hτ+1n和 h τ n − 1 bm h_{tau}^{n-1} hτn−1具有依赖关系,为保持时序信息,需考虑相对位置信息,下节介绍。
循环分段机制除能够学习长期依赖、解决上下文碎片化之外,对预测的性能上也有较大提高。模型通过学习转换矩阵得到固定嵌入,而不是直接学习嵌入,使得预测阶段可以学习更长期的依赖。。此外,在当GPU内存允许条件下,也可利用之前多个分段信息。
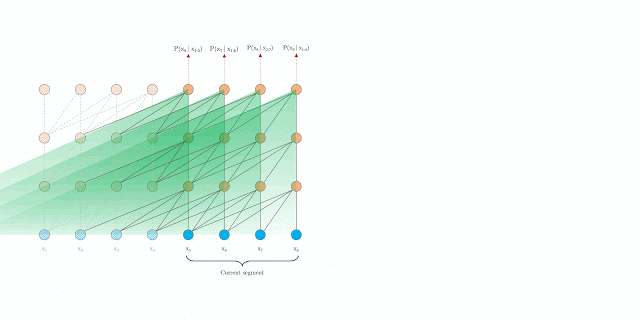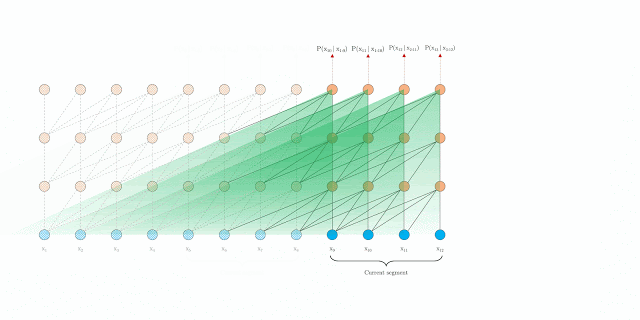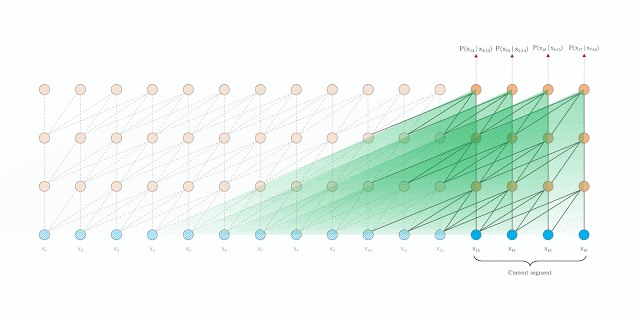
Relative Positional Encodings
在使用之前隐状态时,如何保证连贯的位置信息? 传统的Transformer中,使用绝对位置编码 U ∈ R L max × d UinR^{L_{max}times d} U∈RLmax×d,其第 i i i行表示分段中的第 i i i个绝对位置的编码向量, L max L_{max} Lmax表示最大编码长度,实际是直接将词向量和绝对位置编码向量按元素相加作为实际输入,各分段的处理方式相同。显然,不同分段同时参与运算时,会造成时序混乱。
避免时序混乱的思想是仅在隐状态中引入相对位置信息。位置嵌入目的是给予模型各输入点的时序线索或偏差,以决定如何收集信息,因此,可向每一层的注意力分数中注入相对时序信息,取代将位置编码直接加入初始词向量。
举例来说,对于计算查询向量 q τ , i bm q_{tau,i} qτ,i在键向量 k τ , ≤ i bm k_{tau,leq i} kτ,≤i的注意力,我们不需知道 k τ , j bm k_{tau,j} kτ,j在时序中绝对位置,只需要知道其相对 q τ , i bm q_{tau,i} qτ,i的时序偏差(相对查询的位置偏差)即可,如 i − j i-j i−j。
因此,创建一系列相对位置编码向量 R ∈ R L max × d RinR^{L_{max}times d} R∈RLmax×d(正弦信号),其中 R i R_i Ri表示两位置相对距离为 i i i对应的编码向量,通过在注意力分数中动态地引入相对距离,查询向量可通过相对距离的不同区分 x τ , j x_{tau,j} xτ,j和 x τ + 1 , j x_{tau+1,j} xτ+1,j。
标准Transformer使用绝对位置编码,同一分段中查询向量
q
i
bm q_i
qi对键向量
k
j
bm k_j
kj的注意力分数为
A
i
,
j
abs
=
W
q
(
E
x
i
+
U
i
)
⋅
W
k
(
E
x
j
+
U
j
)
=
E
x
i
⊤
W
q
⊤
W
k
E
x
j
⏟
(
a
)
+
E
x
i
⊤
W
q
⊤
W
k
U
j
⏟
(
b
)
+
U
i
⊤
W
q
⊤
W
k
E
x
j
⏟
(
c
)
+
U
i
⊤
W
q
⊤
W
k
U
j
⏟
(
d
)
begin{aligned} A_{i,j}^{text{abs}} &=W_q(E_{x_i}+U_i)cdot W_k(E_{x_j}+U_j)\[1ex] &=underbrace{E_{x_i}^top W_q^top W_kE_{x_j}}_{(a)} +underbrace{E_{x_i}^top W_q^top W_kU_j}_{(b)} +underbrace{U_i^top W_q^top W_kE_{x_j}}_{(c)} +underbrace{U_i^top W_q^top W_kU_j}_{(d)} end{aligned}
Ai,jabs=Wq(Exi+Ui)⋅Wk(Exj+Uj)=(a)
Exi⊤Wq⊤WkExj+(b)
Exi⊤Wq⊤WkUj+(c)
Ui⊤Wq⊤WkExj+(d)
Ui⊤Wq⊤WkUj
使用相对位置编码,则同一分段中查询向量
q
i
bm q_i
qi对键向量
k
j
bm k_j
kj的注意力分数为
A
i
,
j
rel
=
E
x
i
⊤
W
q
⊤
W
k
,
E
E
x
j
⏟
(
a
)
+
E
x
i
⊤
W
q
⊤
W
k
,
R
R
i
−
j
⏟
(
b
)
+
u
⊤
W
k
,
E
E
x
j
⏟
(
c
)
+
v
⊤
W
k
,
R
R
i
−
j
⏟
(
d
)
begin{aligned} A_{i,j}^{text{rel}} &=underbrace{E_{x_i}^top W_q^top W_{k,E}E_{x_j}}_{(a)} +underbrace{E_{x_i}^top W_q^top W_{k,R}R_{i-j}}_{(b)} +underbrace{u^top W_{k,E}E_{x_j}}_{(c)} +underbrace{v^top W_{k,R}R_{i-j}}_{(d)} end{aligned}
Ai,jrel=(a)
Exi⊤Wq⊤Wk,EExj+(b)
Exi⊤Wq⊤Wk,RRi−j+(c)
u⊤Wk,EExj+(d)
v⊤Wk,RRi−j
相对位置编码的改动在于:
- 将用于计算键向量的绝对位置编码 U j U_j Uj,替换为不需要学习的正弦的相对位置编码 R i − j R_{i-j} Ri−j,使得扩展上下文长度在预测阶段可大于训练阶段;
- 引入参数 u u u取代 ( c ) (c) (c)项中的 W q U i W_qU_i WqUi,此时 ( c ) (c) (c)项仅与内容有关。为使序列中任意位置对其它任意位置的注意力偏差相同,引入参数 v v v取代 ( d ) (d) (d)项中的 W q U i W_qU_i WqUi,此时 ( d ) (d) (d)项仅与相对位置有关;
- 使用权重矩阵 W k , E W_{k,E} Wk,E生成基于内容的键向量(右乘词向量), W k , R W_{k,R} Wk,R生成基于位置的键向量(右乘相对位置向量);
- 四项意义: ( a ) (a) (a)项为内容表示, ( b ) (b) (b)项为依赖位置的内容偏差, ( c ) (c) (c)项为全局内容偏差, ( d ) (d) (d)项为全局位置偏差;
Transformer-XL的整体架构表示为
h
~
τ
n
−
1
=
[
SG
(
m
τ
n
−
1
)
∘
h
τ
n
−
1
]
q
τ
n
,
k
τ
n
,
v
τ
n
=
h
τ
n
−
1
W
q
n
⊤
,
h
~
τ
n
−
1
W
k
,
E
n
⊤
,
h
~
τ
n
−
1
W
v
n
⊤
A
τ
,
i
,
j
n
=
q
τ
,
i
n
⊤
k
τ
,
j
n
+
q
τ
,
i
n
⊤
W
k
,
R
n
R
i
−
j
+
u
⊤
k
τ
,
j
+
v
⊤
W
k
,
R
n
R
i
−
j
a
τ
n
=
Masked-Softmax
(
A
τ
n
)
v
τ
n
o
τ
n
=
LayerNorm
(
Linear
(
a
τ
n
)
+
h
τ
n
−
1
)
h
τ
n
=
Positionwise-Feed-Forward
(
o
τ
n
)
begin{aligned} tildebm h_{tau}^{n-1}&=[text{SG}(bm m_{tau}^{n-1})circbm h_{tau}^{n-1}]\[1ex] bm q_{tau}^n,bm k_{tau}^n,bm v_{tau}^n&=bm h_{tau}^{n-1}{W_q^n}^top,tildebm h_{tau}^{n-1}{W_{k,E}^n}^top,tildebm h_{tau}^{n-1}{W_v^n}^top\[1ex] A_{tau,i,j}^n&={bm q_{tau,i}^n}^top bm k_{tau,j}^n+{bm q_{tau,i}^n}^top W_{k,R}^nR_{i-j}+u^top bm k_{tau,j}+v^top W_{k,R}^nR_{i-j}\[1ex] bm a_{tau}^n&=text{Masked-Softmax}(A_{tau}^n)bm v_{tau}^n\[1ex] bm o_tau^n&=text{LayerNorm}(text{Linear}(bm a_tau^n)+bm h_tau^{n-1})\[1ex] bm h_tau^n&=text{Positionwise-Feed-Forward}(bm o_tau^n) end{aligned}
h~τn−1qτn,kτn,vτnAτ,i,jnaτnoτnhτn=[SG(mτn−1)∘hτn−1]=hτn−1Wqn⊤,h~τn−1Wk,En⊤,h~τn−1Wvn⊤=qτ,in⊤kτ,jn+qτ,in⊤Wk,RnRi−j+u⊤kτ,j+v⊤Wk,RnRi−j=Masked-Softmax(Aτn)vτn=LayerNorm(Linear(aτn)+hτn−1)=Positionwise-Feed-Forward(oτn)
式中,计算
A
τ
n
A_{tau}^n
Aτn,意味着需对所有位置对
(
i
,
j
)
(i,j)
(i,j)计算
W
k
,
R
n
R
i
−
j
W_{k,R}^nR_{i-j}
Wk,RnRi−j,时间复杂度
O
(
n
2
)
O(n^2)
O(n2),优化后可降至
O
(
n
)
O(n)
O(n)。
最后
以上就是包容冬日最近收集整理的关于Transformer-XL: 非固定长度上下文的注意力语言模型(Attentive Language Models Beyond a Fixed-Length Context)的全部内容,更多相关Transformer-XL:内容请搜索靠谱客的其他文章。


![[Z]Creating an OpenGL Context](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)


![[论文阅读]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context前言摘要1、Introduction & Motivation2、How to do ?3、Experiments Analysis(main)总结](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)


发表评论 取消回复