长度可以不一样的语言模型 (就是依赖下一层和下一层的前一段)
https://arxiv.org/pdf/1901.02860.pdf
transformer 框架有学习长期依赖的潜能,但是 受限于语言模型设置的固定长度。作为一种解决方法,我们提出一种新颖的网络结构 Transformer-XL,它能使 Transformer 在不打乱输入文本的时间序列(文本顺序)的情况下,学习不止固定长度的长期依赖 。具体的,它包含了 语句级别的循环机制和一种新颖的位置编码方案。我们的方法不仅能捕获长期依赖,而且能够解决上下文分裂的问题。因此,Transformer-xl 在学习长期依赖 比rnn长80%, 比 vanilla Transformer长450%,在长短序列获得了好的性能并且 在评价阶段比 vanilla Transformer 快1800倍。此外,我们提高了 。。。。我们的代码,预训练模型和超参数tensorflow 和pytorch版都能找到。
语言模型是 重要的问题 需要 给长期依赖建立模型,并成功应用比如无监督预训练。然而,配置 有能力给序列化数据建立长期模型 的神经网络 已经是一个挑战。Rnn,特别是lstm网络,已经是 语言建模的一种标准方法并在多个基准上取得了很好的结果。尽管RNN具有广泛的适应性,但由于梯度消失和爆炸,RNN很难优化,引进LSTM的gate和梯度截断技术可能不足以完全解决这一问题。根据经验,先前的研究发现,LSTM语言模型平均使用200个上下文词,这表明还有进一步改进的空间。另一方面,在注意力机制中远距离单词对的直连,可能会更容易优化并能够学习长期依赖 。最近,Al-Rfou为训练字符级语言模型 设计了一套备用损失 来 训练深度transformer 网络 。虽然 用 Al-Rfou训练的语言模型 来训练 (把几百个字符 分割成固定长度的片段),但是在片段上没有任何信息流。由于固定的上下文长度,模型不能捕获超出预定义上下长度的任何长期依赖。此外,通过选择连续的符号块而不考虑句子或任何其他语义边界 创建固定长度片段。因此,该模型缺乏必要的上下文信息,无法很好地预测前几个符号,导致优化不足和性能低下。我们把这个问题认为上下文碎片。
为了解决之前提到的固定长度上下文的限制,我们提出一种新的结构 叫transformer-xl(意思是超长)。我们将循环的观念引入到深层self-attention网络。特别是,我们重用了前面片段获得的隐藏状态,而不是从头开始为每一个新的片段计算隐藏状态。重用的隐藏状态为现在的片段作为记忆,这在片段之间构建了循环联系 。因此,长期依赖的模型变成了可能,因为信息能够通过循环联系传播。同时,之前片段的信息也能解决上下文碎片化问题。更重要的是,我们展示了 使用相对位置编码而不是绝对位置编码的必要性,为了在不造成时序混乱的情况下实现状态重用。因此,作为一种额外的技术贡献,我们引进一种简单但是十分有效的相对位置编码公式,该公式能推广到 比训练时看到的 更长的注意力长度。
Transformer-xl从词级别到字符级别的语言模型 在五个数据集上获得了非常好的结果 。Transformer-xl提高了之前最先进的结果 在 enwiki8上 bpc 从1.06到0.99,在text8 上bpc 从1.13到1.08,在wikitext-103上困惑度从20.5到18.3,在One Billion Word困惑度从23.7变化到21.8。在小数据集上,Transformer-xl在Penn Treebank数据集上 没有微调 的困惑度是54.5,在考虑可比设置时,这是最先进的结果。
我们使用两种方法来量化研究 tranformer-xl和 基线 的有效长度。与Khandelwal et al 类似,我们在测试时间逐渐增加注意力长度,直到不能观察到显著的提高(%0.1的相对增加)。我们在wikitext-103和enwiki8最好的模型的注意力长度分别是1600和3800。此外,我们设计了一种测量方法叫 相对有效上下文长度(recl),旨在对不同模型增加上下文长度 带来的收益进行公平比较。在上下文长度,transformer-xl 在wikitext-103的recl是900,循环网络和transformer的上下文长度仅仅是500和128.
2相对工作
在过去的几年,语言建模领域取得了许多重大进展,包括但不限于设计新颖的结构更好的encoder上下文,提高正则化和优化算法;Press&Wolf 加速了softmax 计算并丰富了 输出分布族。
为了捕获语言模型的长范围的上下文,直接将更广泛的上下文表示作为附加输入 输入到网络中。目前的工作 从 手动自定上下文向量 到 依赖 从数据当中学到的文档级的话题。
更广泛地说,在通用序列建模中,如何捕获长期依赖性一直是一个长期存在的研究问题。从这个角度来看,自LSTM的自普遍适应以来,人们一直致力于消除消失梯度问题,包括更好的初始化、额外的丢失信号、增强记忆结构和其他修改RNN内部结构以简化优化。与之不同的是,我们的工作是基于Transformer体系结构的,并且表明语言建模作为一个现实世界的任务 有益于学习长期依赖的能力。
3 模型
假设一个 词集 x = (x1, . . . , xT ),语言模型的任务是 来估计联合概率 P(x) ,P(x)通常 被自动回归分解成 P(x) = Ⅱt P(xt | x<t)。
通过因式分解,问题 简化为估计每个条件因子。在这项工作中,我们坚持使用标准的神经方法来建模条件概率。特别的,一个训练的神经网络需要去把 X<t 编码成一个 固定大小的隐藏状态,用它乘以 词向量获得 logits.然后将 logits 输入到softmax函数当中,产生一个 关于下一个词 的 类别可能性(就是具体判断下一个词是什么)
3.1 普通的transformer框架
为了 把transformer 或self-attention引用到语言模型上,中心问题是如何 训练一个transformer 来有效的 把一个任意长度的上下文 编码 成一个 固定长度的向量。假设给无限的 内存和计算力,一个简单的方案就是 把整个上下文序列 作为一个 绝对的transformer 解码器 ,类似于前馈神经网络。然而,这个在实际中通常是行不通。

图1
一个可行但粗糙的近似方法是将整个语料库分割成易处理大小的较短片段,仅仅用 每个片段来训练模型,忽略以前段中的所有上下文信息。这个想法 被Al-Rfou采纳。我们称他为 通用模型,直观的图如Fig1.a。在这种训练模式下,信息在向前或向后的传递过程中都不会跨段流动。使用固定长度上下文有两个关键限制。首先,最长的可能依赖长度是由分段的长度限制,这是字符级语言建模上的几百个长度。因此,虽然self-attention 机制 相对于Rnns 受到梯度消失的影响更小,但是 通用模型 不能充分利用这种优化优势。第二,虽然可以用padding来关注 句子或者其他语义边界,但是实际上为了效率 标准做法是 将长文本简单地分成固定长度的段。然而简单的 将长文本简单地分成固定长度的段将会导致 section1讨论的上下文碎片问题。
在评估过程中,在每个步骤中,Vanilla模型也会消耗 和训练阶段相同长度的 segment,但只在最后一个位置做预测。然后,在下一步中,该段只向右移动一个位置,新段必须从头开始处理。如图1b所示,此过程确保预测每个 使用 在训练过程中暴露的 尽可能长的上下文,这也减轻了训练过程中遇到的上下文碎片问题。然而,这种评估程序非常昂贵。我们将展示我们提出的架构能够大幅度提高评价速度。
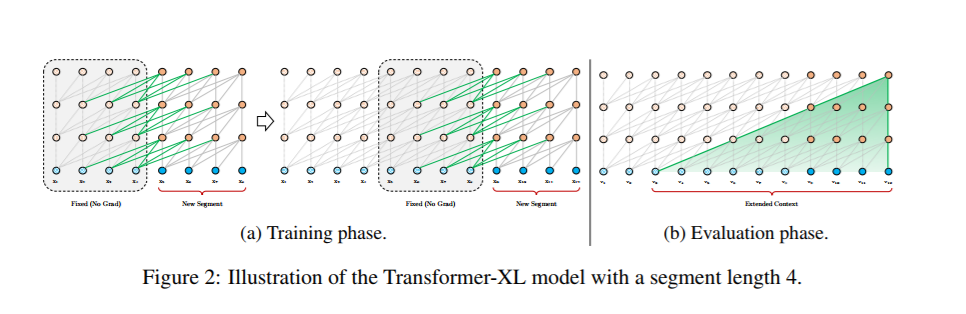
3.2 segment-level 循环,状态重用
为了解决使用固定长度上下文的局限性,我们建议在Transformer架构中引入一种递归机制。在训练过程中,为前一段计算的隐藏状态序列是固定的,并 缓存 以在模型处理下一个新段时作为扩展上下文重用,如Fig,2a所示。尽管梯度仍然保留在一个段中,但是这种额外的输入允许网络利用 之前的信息,从而能够建模长期依赖关系并避免上下文碎片化。形式上,让长度L的两个连续段分别为sτ=[xτ,1,···,xτ,l]和sτ+1=[xτ+1,1,···,xτ+1,l]。用![]() 来表示第n层第i 段 序列的隐藏状态,d是隐藏维度。然后,生成段sτ+1的第n层隐藏状态(示意图),如下所示:
来表示第n层第i 段 序列的隐藏状态,d是隐藏维度。然后,生成段sτ+1的第n层隐藏状态(示意图),如下所示:
#
其中,函数sg(·)代表停止梯度,符号![]() 表示沿两个隐藏序列在长度维度 上串联,w·表示模型参数。与标准transformer相比,关键的区别在于
表示沿两个隐藏序列在长度维度 上串联,w·表示模型参数。与标准transformer相比,关键的区别在于![]() 和值
和值![]() 取决于扩展上下文
取决于扩展上下文![]() ,因此上一段 的
,因此上一段 的![]() 被缓存。我们通过图Fig.2a中的绿色路径强调这种特殊设计。
被缓存。我们通过图Fig.2a中的绿色路径强调这种特殊设计。
这种循环机制应用于语料库的每两个连续片段,它本质上是在隐藏状态方面创建segment循环。因此,利用的有效上下文可以远远超出两个部分。然而,注意,![]() 之间的循环依赖 每段向下移动一层,这与传统RNN LMS中的相同层循环不同。因此,最长的可能依赖长度 随着 层数和 segment长度 线性增长,也就是O(N*L),如Fig2b阴影区显示的。
之间的循环依赖 每段向下移动一层,这与传统RNN LMS中的相同层循环不同。因此,最长的可能依赖长度 随着 层数和 segment长度 线性增长,也就是O(N*L),如Fig2b阴影区显示的。
这类似于截断的BPTT(Mikolov等人,2010),一种技术训练RNN LMS而开发。但是,与截断的BPTT不同,我们的方法缓存一系列隐藏状态,而不是最后一个状态,并且它应该与Section 3.3节中描述的相对位置编码技术一起应用。
除了实现超长的上下文和解决碎片化,循环机制带来的另一个好处是评估速度显著加快。具体来说,在评估过程中,可以重复使用前面部分的表示,而不是像普通模型那样从头开始计算。在我们在enwiki8上的实验中,Transformer XL的速度是评估期间普通模型的1800倍以上(见第4节)。
最后,请注意,循环机制不需要仅限于前一个段,理论上,只要GPU内存允许,我们可以缓存尽可能多的前一个段,
在处理当前段时 将它们全部重用为额外的上下文。
我们可以缓存一个预先定义的长度为m的、尽可能跨越多个段的隐藏状态,由于与记忆增强神经网络有明确的联系,它们称为
m nτ∈rm×d,。在我们的实验中,在训练期间 我们将m设置为段的长度,并在评估期间将其增加多倍。
3.3相对位置编码
虽然我们发现上一小节中提出的想法非常有吸引力,但为了重用隐藏状态,我们还没有解决一个关键的技术挑战。也就是说,当我们重用状态时,如何保持位置信息的一致性?
回想一下,在Transformer-xl中,顺序信息由一组位置编码提供,
用符号 ![]() 表示,其中i-th (第i行 )
表示,其中i-th (第i行 )![]() 对应于一句话(就是 一个segmnet)中第i个 绝对位置,
对应于一句话(就是 一个segmnet)中第i个 绝对位置,![]() 是 要建模的最大可能长度(就是 最长的那句话的长度)。真正的输入到Transfromer 的是 wordembedding和 postion embedding 字方向的和。我们简单地将这种位置编码与上面介绍的递归机制相适应,隐藏状态序列将按照下图计算 :
是 要建模的最大可能长度(就是 最长的那句话的长度)。真正的输入到Transfromer 的是 wordembedding和 postion embedding 字方向的和。我们简单地将这种位置编码与上面介绍的递归机制相适应,隐藏状态序列将按照下图计算 :
![]() ,
,![]() 代表 序列
代表 序列![]() 的词向量,f表示 转变函数。注意,
的词向量,f表示 转变函数。注意,![]() 这两个都和 相同的位置编码
这两个都和 相同的位置编码 ![]() 有关。因此,模型没有信息去区分
有关。因此,模型没有信息去区分 ![]() 和
和![]() (第 r段的 第 j个字 和第r+1段的第 j个字)的位置信息 对于任何 j=1...L,导致了完全的性能损失。
(第 r段的 第 j个字 和第r+1段的第 j个字)的位置信息 对于任何 j=1...L,导致了完全的性能损失。
为了避免这种失败的模型,基本思想是只对隐藏状态下的相对位置信息进行编码。从概念上讲,位置编码为模型提供了时间了线索or bias (偏见),关于应该如何收集信息,即去哪里学习。出于同样的目的, 不是 在初始 embedding 中静态地加入偏差,而是可以将相同的信息注入到每个层的注意力得分中。更重要的是,以相对的方式定义时间偏差更为直观和通用。
例如,当![]() 向量和
向量和![]() (相互作用时 ,我理解的就是 第r 段的 第i个字 和 第i个位置之前的字 相互作用时),不需要知道每个key 向量的绝对位置 就可以确定 segment的时间顺序。它足以知道每个
(相互作用时 ,我理解的就是 第r 段的 第i个字 和 第i个位置之前的字 相互作用时),不需要知道每个key 向量的绝对位置 就可以确定 segment的时间顺序。它足以知道每个![]() 与他自己
与他自己![]() 之间的相对距离,即i−j。实际上,我们可以创建一组相对位置编码
之间的相对距离,即i−j。实际上,我们可以创建一组相对位置编码![]() ,其中第i行
,其中第i行![]() 表示两个位置的相对距离i。(这段我的理解是 创建一个 seq *seq的矩阵 ,比如第一行表示 seg的第一个字 和seg其他字的相对位置信息)。通过动态地将相对距离注入注意力得分中,q vector 可以从他们的不同距离 很容易地区分
表示两个位置的相对距离i。(这段我的理解是 创建一个 seq *seq的矩阵 ,比如第一行表示 seg的第一个字 和seg其他字的相对位置信息)。通过动态地将相对距离注入注意力得分中,q vector 可以从他们的不同距离 很容易地区分 ![]() ,使得状态循环机制可行。同时,我们不会丢失任何时间信息,因为绝对位置可以从相对距离递归恢复。
,使得状态循环机制可行。同时,我们不会丢失任何时间信息,因为绝对位置可以从相对距离递归恢复。
在此之前,在机器翻译和音乐生成的背景下,已经探讨了相对位置编码的idea。在这里,我们提供了一个不同的推导,得出了一种新的相对位置编码形式,它不仅与绝对位置编码有一对一的对应关系,而且在经验上具有更好的泛化(见Seciton 4)。首先,在标准 Transformer中,同一segment 的 ![]() 和
和 ![]() 的注意力 得分可以 分解为
的注意力 得分可以 分解为
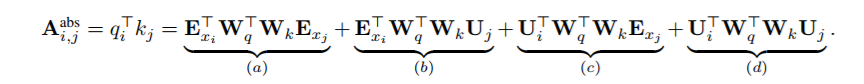
根据只依赖相对位置信息的思想,我们建议 按照如下 重新构建 这四个术语 :
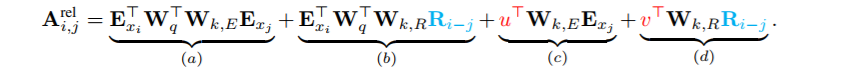
第一个变化是 我们把 b 和d 中 计算 k vectors时的 绝对位置embedding ![]() 全部用
全部用 ![]()
替换 。这从本质上反映了优越性 ,就是只有相对距离才对 在那里相互作用 才重要。注意,R是一个 不可学习参数,是正弦编码矩阵。
第二,我们引入了一个可训练参数 ![]() 来替换 C中的
来替换 C中的 ![]() 。在这种情况下,由于所有q 位置q vector都是相同的,因此建议不管q 位置如何,对不同单词的关注偏差都应该保持不变。同理,在d中 用可训练参数
。在这种情况下,由于所有q 位置q vector都是相同的,因此建议不管q 位置如何,对不同单词的关注偏差都应该保持不变。同理,在d中 用可训练参数
![]() 来替换
来替换 ![]()
最后,为了 生成基于内容的 k vectors 和基于位置的 q vectors,我们故意将两个权重矩阵![]() 分开。
分开。
它表明,不管q的位置如何,对不同单词的关注偏差应该保持不变。
在新的参数下,每个术语有直接的意义:a 表示基于内容的 addressing,b 捕获了与内容相关的位置偏差,术语(c)控制全局
内容偏差,(d)表示 全局位置偏差。
![]() 的公式 仅有术语a和b,没有c和d两个偏执。此外,
的公式 仅有术语a和b,没有c和d两个偏执。此外,![]() 把 乘法
把 乘法![]() 合并成了一个可训练矩阵
合并成了一个可训练矩阵![]() ,它丢失了 以 原正弦位置的 构建的 偏差(意思就是 正弦编码距正构建了 d ,d是偏差 就是 丢失了d).
,它丢失了 以 原正弦位置的 构建的 偏差(意思就是 正弦编码距正构建了 d ,d是偏差 就是 丢失了d).
相比之下,我们的相对位置embedding R 改变 正弦曲线公式。作为归纳偏差的一个好处,一个在某个特定长度的 上训练的模型 ,在评估过程中可以 自动地通用 至原来的几倍。
将递推机制与我们提出的相对位置embedding 相结合,最终得到Transformer-XL结构。为了完整性,
我们将单注意头 n层Transformer-xl的计算过程总结如下:

![]() 定义为 序列的词向量。此外,值得一提的 是 计算A一种蠢的方式是 为 all pairs(i,j) 的计算
定义为 序列的词向量。此外,值得一提的 是 计算A一种蠢的方式是 为 all pairs(i,j) 的计算 ![]()
,这个 消耗 是序列长度的二次方。然而,注意,值i-j是从 0变化到到 seq length,我们在附录B里展示了 一种简单的计算方法,这会是 cost 和 序列长度是线性相关的
4.实验
4.1主要结果
我们将Transformer-xl 在多种数据集上 建立word-level 和character-level的语言模型,以便与最先进的系统进行比较,
包括 WikiText-103 (Merity et al.,2016), enwiki8 (LLC, 2009), text8 (LLC, 2009), One Billion Word (Chelba et al., 2013), and PennTreebank (Mikolov & Zweig, 2012).
wikitext-103是目前最大的 具有长期依赖性的单词级语言建模基准。它包含来自28K篇文章的103M训练词,每篇文章平均长度为3.6K个词,这可以测试 长期依赖模型 的能力。我们在训练期间将注意力长度设置为384,在评估期间将注意力长度设置为1600。我们采用自适应SoftMax和input representations 。如表1所示,Transformer-XL将以前的Sota困惑度 从20.5减少到18.3,这展示了 transformer-XL架构的优越性。
数据集enwiki8包含100M 未处理的wikipedia文本。我们将我们的架构与Table2中以前的结果进行了比较。在模型大小限制下,12层变Transformer-XL获得了一个最先进的结果,比al-rfou等人的12层普通 Transformer高出0.05,而这两种Transformer 变体比传统的基于RNN的模型有较大的 增加 。值得注意的是,我们的12层架构实现了与通用 Transformer 64层网络相同的结果,但仅使用17%的参数预算。为了观察增大模型大小 是否能获得更好的性能,我们对18层和24层Transformer-XLS训练。在训练时注意力集中度为784,评估时注意力集中度为3800,我们获得了一个新的SOTA结果,我们的方法是在广泛研究字符级 基准 的基础上首次突破1.0。与Al Rfou不同,transformer-XL不需要任何辅助损失,因此所有的好处都归功于一个更好的体系结构。
text8与Enwiki8相似但不同的是,text8包含100M 处理过的wikipedia字符,这100M字符 是通过降低文本大小写并删除26个字母a到z 以及空格 以外的任何字符 创建。由于相似性,我们只需将Enwiki8上的最佳模型和相同的超参数 应用在text8上,而无需进一步调整。与以前方法的比较总结在Table3。同样,Transformer XL以明显的优势实现了新的SOTA结果。
One Billion Word 并没有保留任何长期的依赖关系,因为句子已经被打乱了。因此,这个数据集主要测试 短期依赖建模的能力 。
Transformer-XL与其他方法的比较见Table4。虽然Transformer XL主要是为了更好地捕获长期依赖性,但它显著地将单模型SOTA从23.7提高到21.8。具体来说,Transformer XL超过 同时代 使用通用Transformers的方法,表明Transformer-XL的优点可推广到对短序列的建模。
我们也在Table5中报告了word-level 的penn treebank的结果。与AWD-LSTM类似,我们将变分辍学和加权平均应用于变压器XL。通过适当的正则化,Transformer XL在没有两步微调的模型中获得了一个新的SOTA结果。Penn Treebank只有1百万个训练标记,这意味着Transformer XL即使在小数据集上也能很好地推广。
。。。。。这个就不翻译了 主要就是看这个模型的优越性,很容易看
5总结
我们提出了一种新的架构Transformer XL,对 不止固定长度的上下文 使用 self-attention 架构进行语言建模。我们的主要技术贡
我们的主要技术贡献包括在一个纯粹的self-attention 模型中引入递归的概念,并提出一种新的位置编码方案。这两种技术形成了一套完整的解决方案,因为它们中的任何一种都不能解决定长上下文的问题。Transformer XL是第一个在字符级和词级别的 语言模型 上都比RNN取得显著效果的 self-attention模型。Transformer XL还能够 比RNN和Transformer 建模更长期的依赖关系,并且与普通 Transformers 相比,在评估过程中实现了实质性的加速。
论文 临近新年,大家新年快乐
最后
以上就是朴实芒果最近收集整理的关于Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context的全部内容,更多相关Transformer-XL:内容请搜索靠谱客的其他文章。








发表评论 取消回复