
对于想入门学习数据分析的同学来说,大家基本都知道数据分析指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。那我们今天就来聊一下统计的相关内容。

PART
01
统计及其应用领域
1)什么是统计学
统计学(statistics)是收集、处理、分析、解释数据并从数据中得出结论的科学。
数据分析所用的方法可分为描述统计方法和推断统计方法。描述统计(descriptivestatistics)研究的是数据收集、处理汇总、图标描述、概括与分析等统计方法。推断统计(inferentialstatistics)是研究如何利用样本数据来推断总体特征的统计方法。
2)统计的应用领域
统计方法是适用于所有学科领域的通用数据分析方法,只要有数据的地方就会用到统计方法。统计无处不在,如市场研究、产品质量管理(统计合格产品)、财务分析、经济预测、人力资源管理、人口统计等等。
站日常流量数据的重要指标。PV可重复累计,以用户访问网站作为统计依据,用户每刷新一次即重新计算一次。
PART
02
统计数据的分类
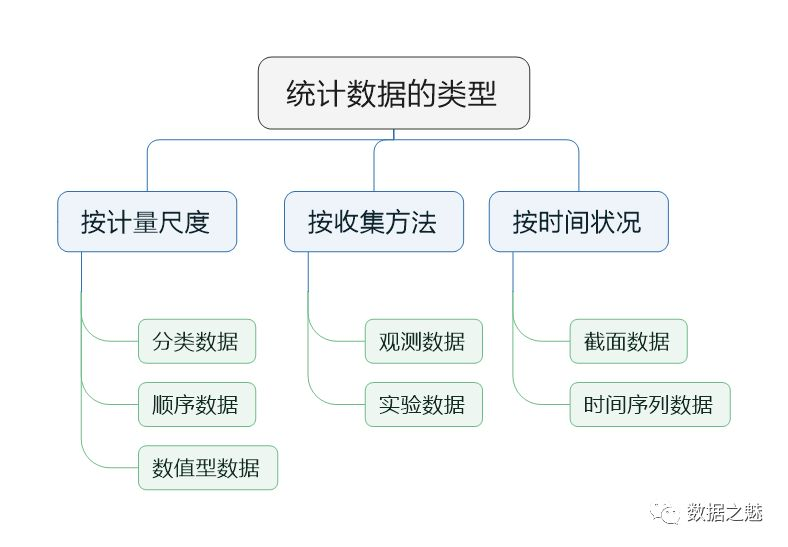
统计数据是对现象进行测量的结果。统计数据有许多分类,下图展示了统计数据的类型,供大家参考学习。这里没有详细列举,后面用到会用实例来验证。
PART
03
统计学中的基本概念
统计学中的概念很多,其中有几个是经常要用到的,这里统一说一下,至于没有提到的概念,后面用到的时候会做详细说明。
总体和样本
总体(population):是包含所研究的全部个体(数据)的集合,通常由所研究的一些个体组成。但是需要注明一点:总体分为有限总体(本校本年级学生)和无限总体(所有学生)。
样本(sample):是从总体中抽取的一部分元素的集合,构成样本的元素数目称为样本量。
参数和统计量
参数(parameter):用于描述总体特征的指标;
统计量(statistic):用于描述样本特征的指标;
变量
变量(variable)是说明现象某种特征的概念,特点是从一次观测到下一次观测结果会呈现出差别或变化。
变量的三种类型:分类变量、顺序变量、数值型变量。
误差
误差:观察值与真知之差。即我们通过一次试验得到的结果与事件真实结果之间的差值。误差根据其产生的原因,分为四种:系统误差(systematic error)、随机误差(random error)、抽样误差(sampling error)、过失误差(gross error)。
概率和频率
概率(P):用于反映某一事物发生可能性大小的一种量度。一般用大写的斜体P表示。
我们根据食物发生概率的大小,把事件分为3类:P=1为必然事件,发生率为100%;P=0为不可能事件,发生率为0;0<P<1为偶然事件,在未发生时即可能发生,又可能不发生。其中P小于等于0.05为小概率事件,应用意义为在一次试验或研究过程中不可能发生。
频率(f):是指我们进行了N次试验,其中一个事件出现的次数m与总的试验次数N的比值。
问题是:我们到底如何能够得到某一事件发生的概率呢,比如说谁能够告诉我一个半截粉笔从讲台上掉下摔断的概率P=?。我们至今的科学发展也没有办法通过公式去计算该值。那我们是怎么做的呢?有句话叫做“有些事情越想越烦,做起来却极其简单”。我们只需要那两盒同样的粉笔进行重复摔就可以了,如果总共100支粉笔,断了98只,那断的频率就等于f=98/100=0.98。而统计学上证实,当某事件发生次数较多时,频率就会收敛于概率。意即f=P。因此,其实我们就是通过频率去估计概率的。
欢迎关注微信公众号,访问更多精彩:数据之魅。
如需转载,请联系授权,谢谢合作。
最后
以上就是老迟到抽屉最近收集整理的关于数据分析系列 4/32 | 数据分析必知统计学的全部内容,更多相关数据分析系列内容请搜索靠谱客的其他文章。








发表评论 取消回复