ElasticSearch学习笔记之二十一 指标聚合
- 指标聚合
- Avg Aggregation
- Script
- Value Script
- Missing value
- Weighted Avg Aggregation
- weighted_avg Parameters
- value Parameters
- weight Parameters
- Cardinality Aggregation
- Precision control
- Counts are approximate
指标聚合
这种聚合从需要聚合的文档中提取出值进行指标计算。这些值通常从文档的字段中提取出来,但是也可以使用 scripts。
数字型指标聚合是一个可以输出数字类型值的指标聚合。 一些聚合输出一个数组指标 (例如. avg) 我们称之为单值数字型聚合 ,产生多个指标的(例如stats) 我们称为多值数字型聚合。当这些聚合直接作为一些分组聚合的子聚合时,单值数字型聚合和多值数字型聚合就可以发挥巨大的作用,例如分组聚合可以对指标聚合后的返回结果进行排序。
Avg Aggregation
Avg Aggregation是一个从需要聚合的文档中提取字段平均值的单值数字型聚合. 这些值既可以从文档中提取也可以从script获取。
假设有一组记录学生成绩的文档(0~100),我们可以这样计算平均分:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { #聚合的名称
"avg" : { #聚合的类型
"field" : "grade"
}
}
}
}
上面的聚合会对所有的文档计算平均值。聚合的类型是avg ,field 属性指明了文档需要计算平均数的数字字段。
返回的结果如下:
{
...
"aggregations": {
"avg_grade": {#聚合的名称
"value": 75.0
}
}
}
聚合的名称 (例如avg_grade ) 也会在返回的信息作为关键字返回。
Script
通过script计算平均成绩:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"source" : "doc.grade.value"
}
}
}
}
}
上面的语言会使用系统内置的脚本语言进行解释,并且不带参数。使用一个文件脚本的完整语言如下:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
Value Script
结果表明,考试的水平远远高于学生的水平,需要进行等级更正。我们可以使用值脚本来获得新的平均值。:
POST /exams/_search?size=0
{
"aggs" : {
"avg_corrected_grade" : {
"avg" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
Missing value
missing 参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也有可能将它们视为具有值。
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段中没有值的文档将与具有值10的文档落入相同的桶中。
Weighted Avg Aggregation
Weighted Avg Aggregation是一个从需要聚合的文档中提取字段加权平均值的单值数字型聚合. 这些值既可以从文档中提取也可以从script获取。
当计算一个规则平均值时,每个数据点都有一个相等的“权重”…它对最终值有同样的贡献。另一方面,加权平均值对每个数据点的权重不同。每个数据点对最终值的贡献量是从文档中提取的,或者由脚本提供。
加权平均值的计算公式
∑(value * weight) / ∑(weight)
正则平均值可以被认为是每个值都具有1的隐式权重的加权平均值。
weighted_avg Parameters
| 参数名称 | 描述 | 是否需要默认值 |
|---|---|---|
| value | 字段或者脚本的加权配置值 | Required |
| weight | 字段或者脚本的加权配置 | Required |
| format | 返回数字的格式化 | Optional |
| value_type | 无映射的字段或者纯脚本的默认值类型 | Optional |
每个字段特定的值和权重对象配置
value Parameters
| 参数名称 | 描述 | 是否需要默认值 |
|---|---|---|
| field | 提取值的字段 | Required |
| missing | 默认缺省值 | Optional |
weight Parameters
| 参数名称 | 描述 | 是否需要默认值 |
|---|---|---|
| field | 权重值提取的字段 | Required |
| missing | 权重缺省默认值 | Optional |
例如
如果我们的文档有一个包含0-100个数字分数“grade”字段和一个包含任意的数字权重“weight”字段,,那么我们可以使用:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
返回结果如下
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
虽然每个字段允许多个值,但只允许一个权重。如果聚合遇到具有多于一个权重的文档(例如,权重字段是多值字段),它将抛出异常。如果存在这种情况,则需要为权重字段指定脚本,并使用脚本将多个值组合成要使用的单个值。
此单个权重将独立地应用于从多值字段中提取的每个值。
这个例子展示了一个具有多个值的单个文档将如何以单个权重平均化:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这3个值(1, 2, and 3) 都会被包含进去和2的权重计算。
{
…
“aggregations”: {
“weighted_grade”: {
“value”: 2.0
}
}
}
聚合返回2作为结果,它与我们手工计算时的期望值相匹配: ((12) + (22) + (3*2)) / (2+2+2) == 2
Cardinality Aggregation
Cardinality Aggregation是一个从需要聚合的文档中计算不同值的近似计数(去重) 的单值数字型聚合. 这些值既可以从文档中提取也可以从script获取。
假设您索引了商店销售情况,并希望通过查询计算销售产品数量。
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
返回结果如下
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}
Precision control
聚合也支持precision_threshold 精度控制参数:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "_doc",
"precision_threshold": 100
}
}
}
}
precision_threshold 参数允许交易内存的准确性,并定义了一个独特的计数以下计数预期接近准确。高于这个值,计数可能会变得更模糊。最大支持值是40000,高于这个数的阈值将具有与阈值40000相同的效果。默认值为3000。
Counts are approximate
计算精确计数需要将值加载到哈希集并返回其大小。当处理高基数集和/或大值作为所需的内存使用以及节点之间通信那些每碎片集的需要时,这无法扩展,这会利用集群的许多资源。
这种基数聚合是基于HyperLog++算法的,它基于具有以下一些有趣的属性的值的散列进行计数:
- 可配置的精度,决定如何交易内存的准确性,
- 低基数集精度高,
- 固定内存使用率:无论存在数百或数十亿个惟一值,内存使用率仅取决于配置的精度。
-对于C的精确阈值,我们使用的实现需要大约c* 8字节。
下面的图表显示了阈值前后的误差是如何变化的:
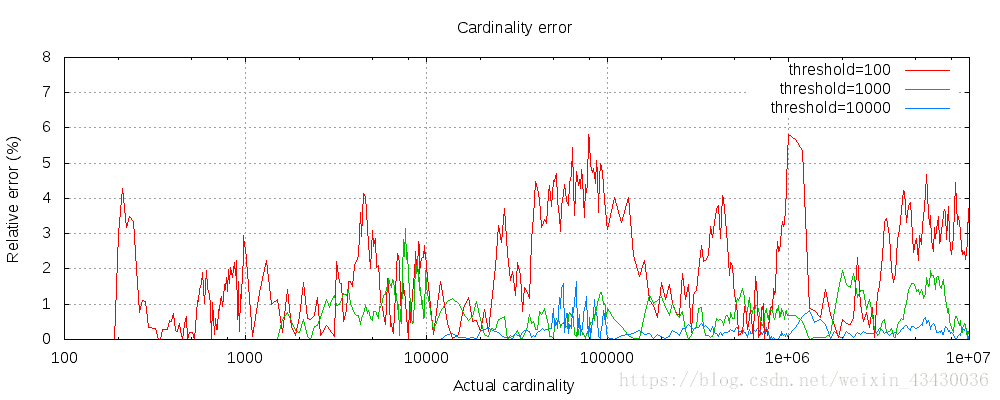
对于所有3个阈值,计数一直精确到配置的阈值(尽管不能保证,但很可能是这样)。请注意,即使阈值低至100,错误仍然很低,即使在数以百万计的项目。
最后
以上就是激昂黄豆最近收集整理的关于ElasticSearch学习笔记之二十一 指标聚合指标聚合的全部内容,更多相关ElasticSearch学习笔记之二十一内容请搜索靠谱客的其他文章。








发表评论 取消回复