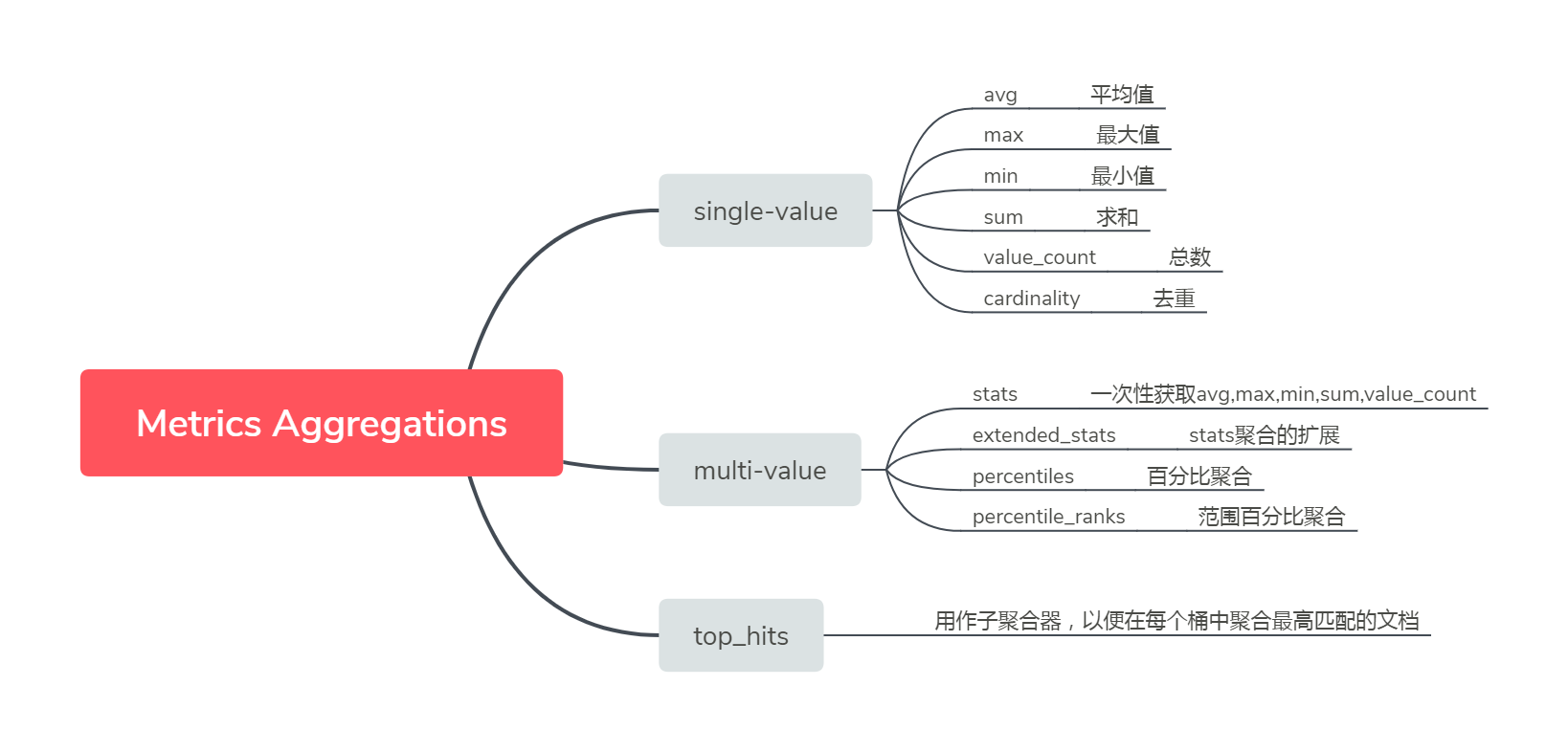
我是靠谱客的博主 飘逸水池,这篇文章主要介绍Elasticsearch-Metrics Aggregations(度量聚合/指标聚合)前言聚合的基本结构准备测试数据avg,max,min,sum,value_count,stats,extended_statscardinalitypercentilespercentile_rankstop_hits,现在分享给大家,希望可以做个参考。
前言
本文基于elasticsearch7.3.0版本
聚合的基本结构
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
准备测试数据
PUT my_index
{
"mappings": {
"properties": {
"tag": {
"type": "keyword"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
PUT my_index/_doc/1
{
"tag": "没有价格的水果"
}
PUT my_index/_doc/2
{
"tag": "橘子",
"price": "1.00"
}
PUT my_index/_doc/3
{
"tag": "苹果",
"price": "9.00"
}
avg,max,min,sum,value_count,stats,extended_stats
这几种聚合语法都差不太多,所以一起看
- avg:平均值
- max:最大值
- min:最小值
- sum:求和
- value_count:总数
- stats:一次性返回avg,max,min,sum,value_count
- extended_stats:stats聚合的扩展
求水果价格的平均值
GET my_index/_search
{
"size": 0,
"aggs": {
"price_avg": {
"avg": {
"field": "price",
// 设置字段的缺省值
"missing": 1
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : []
},
"aggregations" : {
"price_avg" : {
"value" : 3.6666666666666665
}
}
}
使用脚本
GET my_index/_search
{
"size": 0,
"aggs": {
"price_avg": {
"avg": {
"script": {
"source": "doc['price']"
}
}
}
}
}
使用value script
GET my_index/_search
{
"size": 0,
"aggs": {
"price_avg": {
"avg": {
"field": "price",
"script": {
"lang": "painless",
"source": "_value * params.number",
"params": {
"number": 1.5
}
}
}
}
}
}
stats聚合
GET my_index/_search
{
"size": 0,
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price_stats" : {
"count" : 2,
"min" : 1.0,
"max" : 9.0,
"avg" : 5.0,
"sum" : 10.0
}
}
}
cardinality
去重,去重的结果是近似值,并不是准确的
这个precision_threshold选项允许用内存来换取准确性,并定义了一个唯一的计数,在此计数以下的计数预计接近准确。在此值之上,计数可能变得更加模糊。最大支持值为40000,高于此数字的阈值将具有与阈值40000相同的效果。默认值是3000.
# 聚合tag去重数量
GET my_index/_search
{
"size": 0,
"aggs": {
"tag_cardinality": {
"cardinality": {
"field": "tag",
"precision_threshold": 3000
}
}
}
}
使用脚本
这个cardinality度量支持脚本,但是性能受到显著影响,因为散列需要动态计算
GET my_index/_search
{
"size": 0,
"aggs": {
"tag_cardinality": {
"cardinality": {
"script": {
"lang": "painless",
"source": "doc['tag']+' '+doc['price']"
}
}
}
}
}
percentiles
百分位聚合
GET my_index/_search
{
"size": 0,
"aggs": {
"price_percentiles": {
"percentiles": {
// field必须是数字字段
"field": "price"
}
}
}
}
默认情况下,percentile度量将生成一系列百分位数:[ 1, 5, 25, 50, 75, 95, 99 ]
响应
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price_percentiles" : {
"values" : {
"1.0" : 1.0,
"5.0" : 1.0,
"25.0" : 1.0,
"50.0" : 5.0,
"75.0" : 9.0,
"95.0" : 9.0,
"99.0" : 9.0
}
}
}
}
使用percents参数指定要计算的特定百分位数
GET my_index/_search
{
"size": 0,
"aggs": {
"price_percentiles": {
"percentiles": {
"field": "price",
// 以数组的方式返回
"keyed": false,
"percents": [
95,
99,
99.99
]
}
}
}
}
响应
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price_percentiles" : {
"values" : [
{
"key" : 95.0,
"value" : 9.0
},
{
"key" : 99.0,
"value" : 9.0
},
{
"key" : 99.99,
"value" : 9.0
}
]
}
}
}
使用脚本
GET my_index/_search
{
"size": 0,
"aggs": {
"price_percentiles": {
"percentiles": {
"field": "price",
"script": {
"lang": "painless",
"source": "_value * params.number",
"params": {
"number": 10
}
}
}
}
}
}
percentile_ranks
和percentiles类似,可以指定百分位区间
GET my_index/_search
{
"size": 0,
"aggs": {
"price_percentile_ranks": {
"percentile_ranks": {
// field必须是数字字段
"field": "price",
"values": [
90,
99
],
"keyed": false,
"script": {
"lang": "painless",
"source": "_value * params.number",
"params": {
"number": 10
}
}
}
}
}
}
响应
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price_percentile_ranks" : {
"values" : [
{
"key" : 90.0,
"value" : 100.0
},
{
"key" : 99.0,
"value" : 100.0
}
]
}
}
}
top_hits
此聚合器将用作子聚合器,以便在每个桶中聚合最高匹配的文档
GET my_index/_search
{
"size": 0,
"aggs": {
"tag_terms": {
"terms": {
"field": "tag",
"size": 10
},
"aggs": {
"tag_top": {
"top_hits": {
"from": 0,
"size": 10,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
}
}
}
}
}
响应
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"tag_terms" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "橘子",
"doc_count" : 1,
"tag_top" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"tag" : "橘子",
"price" : "1.00"
},
"sort" : [
1.0
]
}
]
}
}
},
{
"key" : "没有价格的水果",
"doc_count" : 1,
"tag_top" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"tag" : "没有价格的水果"
},
"sort" : [
"-Infinity"
]
}
]
}
}
},
{
"key" : "苹果",
"doc_count" : 1,
"tag_top" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"tag" : "苹果",
"price" : "9.00"
},
"sort" : [
9.0
]
}
]
}
}
}
]
}
}
}
最后
以上就是飘逸水池最近收集整理的关于Elasticsearch-Metrics Aggregations(度量聚合/指标聚合)前言聚合的基本结构准备测试数据avg,max,min,sum,value_count,stats,extended_statscardinalitypercentilespercentile_rankstop_hits的全部内容,更多相关Elasticsearch-Metrics内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复