转自:https://blog.csdn.net/mzpmzk/article/details/53083579
Loss Function
softmax_loss的计算包含2步:
(1)计算softmax归一化概率
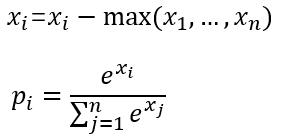
# 为什么要减去最大值?数值稳定性的解释。#
在求 exponential 之前将x 的每一个元素减去x_i 的最大值。这样求 exponential 的时候会碰到的最大的数就是 0 了,不会发生overflow 的问题,但是如果其他数原本是正常范围,现在全部被减去了一个非常大的数,于是都变成了绝对值非常大的负数,所以全部都会发生 underflow,但是underflow 的时候得到的是 0,这其实是非常 meaningful 的近似值,而且后续的计算也不会出现奇怪的 NaN。
当然,总不能在计算的时候平白无故地减去一个什么数,但是在这个情况里是可以这么做的,因为最后的结果要做 normalization,很容易可以证明,这里对x 的所有元素同时减去一个任意数都是不会改变最终结果的——当然这只是形式上,或者说“数学上”,但是数值上我们已经看到了,会有很大的差别。
(2)计算损失
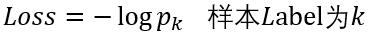
这里以batchsize=1的2分类为例:
设最后一层的输出为[1.2 0.8],减去最大值后为[0 -0.4],
然后计算归一化概率得到[0.5987 0.4013],
假如该图片的label为1,则Loss=-log0.4013=0.9130
# loss function 的解释#

也很直观,对于某个样本i,他对应的gt label是j,那么对于loss function来说,显然只需要关心第k路是否是一个概率很大的值,所以就用一个l{·}的示性函数来表示只关心第路(即label对应的那一路),其他路都忽略为0。然后log的部分其实就是第k路的概率值取log。最后需要注意到前面还有一个负号。
所以总的来说,这个loss function的意思是说,对于某个样本,我只看他gt对应的那个路子输出的概率,然后取一个-log从最大化概率变成最小化能量。
可选参数
(1) ignore_label
int型变量,默认为空。
如果指定值,则label等于ignore_label的样本将不参与Loss计算,并且反向传播时梯度直接置0.
(2) normalize
bool型变量,即Loss会除以参与计算的样本总数;否则Loss等于直接求和
(3) normalization
enum型变量,默认为VALID,具体代表情况如下面的代码。
enum NormalizationMode {
// Divide by the number of examples in the batch times spatial dimensions.
// Outputs that receive the ignore label will NOT be ignored in computing the normalization factor.
FULL = 0;
// Divide by the total number of output locations that do not take the
// ignore_label.
If ignore_label is not set, this behaves like FULL.
VALID = 1;
// Divide by the batch size.
BATCH_SIZE = 2;
//
NONE = 3;
}归一化case的判断:
(1) 如果未设置normalization,但是设置了normalize。
则有normalize==1 -> 归一化方式为VALID
normalize==0 -> 归一化方式为BATCH_SIZE
(2) 一旦设置normalization,归一化方式则由normalization决定,不再考虑normalize。
使用方法
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc1"
bottom: "label"
top: "loss"
top: "prob"
loss_param{
ignore_label:0
normalize: 1
normalization: FULL
}
}
扩展使用
(1) 如上面的使用方法中所示,softmax_loss可以有2个输出,第二个输出为归一化后的softmax概率
(2) 最常见的情况是,一个样本对应一个标量label,但softmax_loss支持更高维度的label。
当bottom[0]的输入维度为N*C*H*W时,
其中N为一个batch中的样本数量,C为channel通常等于分类数,H*W为feature_map的大小通常它们等于1.
此时我们的一个样本对应的label不再是一个标量了,而应该是一个长度为H*W的矢量,里面的数值范围为0——C-1之间的整数。
至于之后的Loss计算,则采用相同的处理。
参考blog
1.softmax数值稳定性讨论2.softmaxwithloss的解释
最后
以上就是可耐背包最近收集整理的关于caffe softmax—loss源码公式分析的全部内容,更多相关caffe内容请搜索靠谱客的其他文章。








发表评论 取消回复