#手写识别系统
#准备数据
#为了使用前面两个分类器,因为前面的例子都是只有一行的,我们必须将图像格式化处理为一个向量。我们将把一个32*32的
#二进制图像矩阵转换为1*1024的向量,这样前两节使用的分类器就可以处理数字图像信息了。
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
#手写数字识别系统
def handwritingClassTest():
hwLabels = []
#listdir():用于返回指定的文件夹包含的文件或文件夹名字的列表
trainingFilelist = listdir('digits/trainingDigits')
m = len(trainingFilelist)
#创建一个m行1024列的训练矩阵,该矩阵的每行数据储存一个图像
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFilelist[i]
fileStr = fileNameStr.split('.')[0]# 比如'digits/testDigits/0_13.txt',被拆分为0,13,txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)#将类代码储存在hwLabels向量中
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = listdir('digits/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
#vectorUnderTest = img2vector('D:/pythonml/testDigits/%s' % (fileNameStr))
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest,trainingMat,hwLabels,3)
print("the classifier came back with: %d, the real answer is:%d" %(classifierResult,classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
print("n the total number of errors is: %d" %errorCount)
print("n the total error rate is :%f" %(errorCount/float(mTest)))
if __name__ == "__main__":
handwritingClassTest()listdir():用于返回指定的文件夹包含的文件或文件夹名字的列表
运行效果如下:
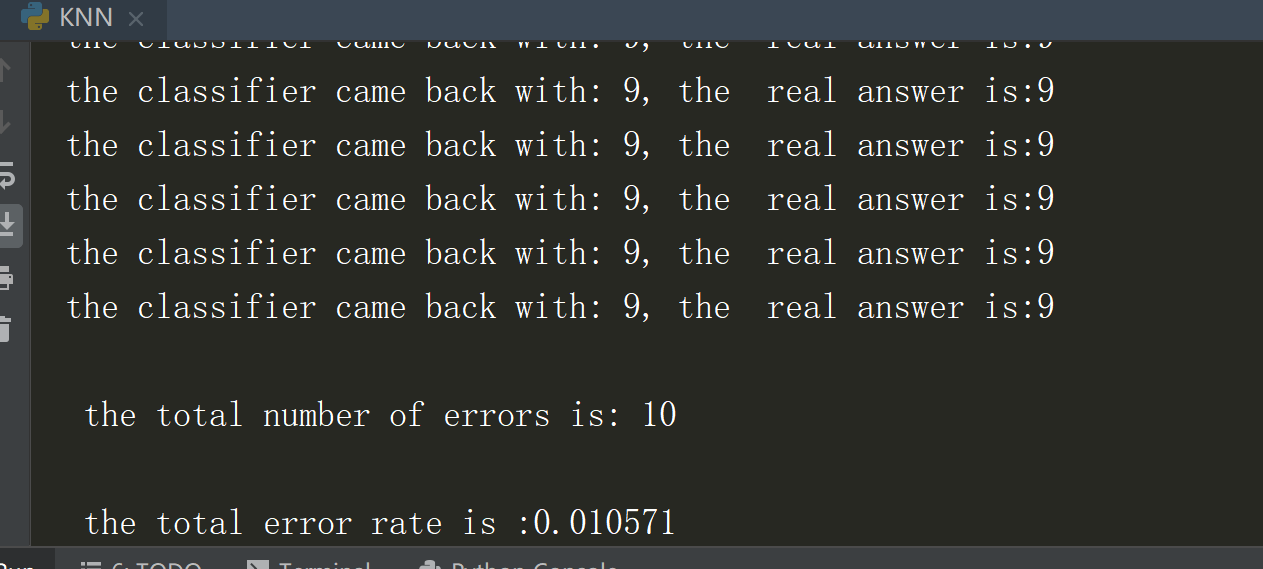
手写数字识别系统我的理解:
分两步:1.将训练样本读取出来,转化成向量后,并读取他的数据点及其分类标签。
2.将测试数据读取出来,转化成向量后,调用KNN算法进行分类,并计算错误率,以之前的第一部得出的数据和标签作为训练样本和标签。
最后
以上就是鳗鱼蓝天最近收集整理的关于2.3测试算法:使用k近邻算法识别手写数字的全部内容,更多相关2内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复