本文介绍K-近邻算法(KNN:K- Nearest Neighbor)
1、K-近邻模型
KNN模型是一种用于回归任务和分类任务的简单模型
算法中的“邻居”代表的事度量空间中的训练实例
度量空间事定义了集合中所有成员之间距离的特征空间。
邻居用于估计一个测试实例对应的响应变量值。
超参是用来控制算法如何学习的参数,他不通过训练数据来估计,一般需要人为指定
最后,算法通过某种距离函数,从度量空间中选出k个距离测试实例最近的邻居
对于分类任务,训练集由一组特征向量的元祖和标签类组成。
最简单的KNN分类器使用KNN标签模式对测试实例进行分类,但是我们也可以使用其他策略。
超参k经常设置为一个奇数来防止出现平局现象。
在回归任务中,每一个特征向量都会和一个响应变量相关联,此处的响应变量是一个实值标量而不是一个标签,预测结果为KNN响应变量的均值或者权重均值。
2、惰性学习和非参数模型
KNN 是一种惰性学习模型,也被称为基于实例的学习模型,会对训练数据集进行少量的处理或者完全不处理。
和简单线性回归这样的勤奋学习模型不同,KNN在训练阶段不会估计由模型生成的参数。
惰性学习有利有弊。训练勤奋学习模型通常很耗费计算资源,但是在模型预测阶段代价并不昂贵。例如在简单线性回归中,预测阶段只需要将特征城西系数,再加上截断参数即可。
惰性学习模型几乎可以进行即可预测,但是需要付出高昂的代价。在kNN模型最简单的视线中,进行预测要求计算出一个测试实例和所有训练实例之间的距离。
KNN是一种非参数模型。参数模型使用固定数量的参数或者系数去定义能够对数据进行总结的模型,参数的数量独立于训练实例的数量。
非参数模型意味着模型的参数个数并不固定,他可能随着训练实例数量的增加而增加。
当训练数据数量庞大,而你对响应变量和解释变量之间的关系所知甚少时,非参数模型会非常有用。
KNN模型只基于一个假设:互相接近的实例拥有类似的响应变量值。
3、KNN模型分类
import numpy as np
import matplotlib.pyplot as plt
X_train= np.array([
[158, 64],
[170, 86],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[170, 67]
])
y_train = ['male','male','male','male',"female","female","female","female","female"]
plt.figure()
plt.title('Human Heights and Weights by Sex')
plt.xlabel('Height in cm')
plt.ylabel('Weights in kg')
for i, x in enumerate(X_train):
plt.scatter(x[0], x[1], c='k', marker='x' if y_train[i] == 'male' else 'D')
plt.grid(True)
plt.show()
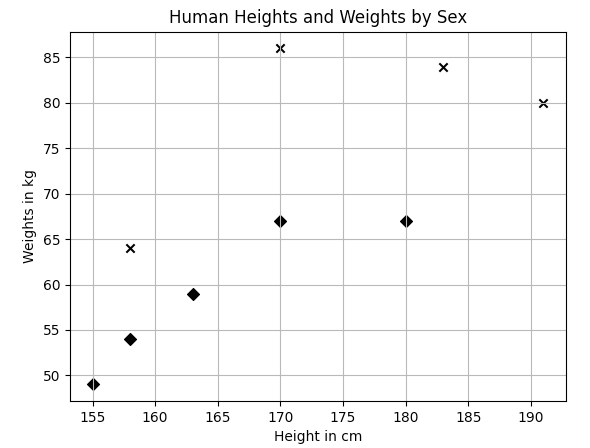
我们使用欧几里得空间中两点之间的直线距离。
我们选取测试点155, 70],首先计算测试点与所有点之间的距离,然后取3个最近的点,并找出3个最普遍的性别
如代码所示,预测测试点为女性。
x = np.array([[155, 70]])
distances = np.sqrt(np.sum((X_train - x)**2, axis=1))
print(distances)
nearest_neighbor_indices = distances.argsort()[:3]
nearest_neighbor_genders = np.take(y_train, nearest_neighbor_indices)
print(nearest_neighbor_genders)
from collections import Counter
b = Counter(np.take(y_train, distances.argsort()[:3]))
print(b.most_common(1)[0][0])
[ 6.70820393 21.9317122 31.30495168 37.36308338 21. 13.60147051
25.17935662 16.2788206 15.29705854]
['male' 'female' 'female']
female
现在使用scikit-learn类库实现一个KNN分类器
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
#
lb = LabelBinarizer()
y_train_binarized = lb.fit_transform(y_train)
K = 3
clf = KNeighborsClassifier(n_neighbors=K)
clf.fit(X_train, y_train_binarized.reshape(-1))
prediction_binartzed = clf.predict(np.array([155, 70]).reshape(1, -1))[0]
predicted_label = lb.inverse_transform(prediction_binartzed)
print(predicted_label)
['female']
使用LabelBinarizer 将字符串标签转化为整数
fit 方法进行了一些转换准备工作,在此处是将标签字符串映射到证书
transform 方法则是将映射关系运用于输入标签
fit_transform 方法同时调用了fit和transform方法
接着,我们将KNeighborsClassifier类实例化,并调用fit和predict方法进行预测,最后使用已经完成拟合的LabelBinarizer 进行逆向转换返回字符串标签。
精准率,召回率,真正率的计算
有时使用一个统计变量来总结精准率和召回率很有用,这个统计变量称为F1得分或者F1度量,F1得分是精准率和召回率的调和平均值
精准率和召回率的算术平均值是F1得分的上界,当分类器的精准率和召回率之间的差异增加是,F1得分对分类器的惩罚程度也会增加。
马修斯相关系数(MCC)是除F1外,另一种对二元分类器性能进行衡量的选择。
一个完美分类器的MCC值为1,随机进行预测的分类器MCC得分为0,完全预测错误的分类器MCC得分为-1
KNN模型回归

下面我们使用身高和性别数据预测体重
特征缩放
当特征有相同的取值范围时,许多学习算法将会运行得更好。
在上一部分中:二元值特征表示性别,另一个连续值特征表示单位为厘米的身高
StandardScaler类是一个用于特征缩放的转换器,,它首先将所有实例特征值减去均值来将其居中,然后除以特征的标准差对其进行缩放。
均值为0,方差为1的数据称为标准化数据。
from sklearn.preprocessing import StandardScaler
X_train = np.array(
[[158, 1],
[170, 1],
[183, 1],
[191, 1],
[155, 0],
[163, 0],
[180, 0],
[158, 0],
[170, 0]]
)
ss = StandardScaler()
X_train_scaled = ss.fit_transform(X_train)
print(X_train)
print(X_train_scaled)
[[158 1]
[170 1]
[183 1]
[191 1]
[155 0]
[163 0]
[180 0]
[158 0]
[170 0]]
[[-0.9908706 1.11803399]
[ 0.01869567 1.11803399]
[ 1.11239246 1.11803399]
[ 1.78543664 1.11803399]
[-1.24326216 -0.89442719]
[-0.57021798 -0.89442719]
[ 0.86000089 -0.89442719]
[-0.9908706 -0.89442719]
[ 0.01869567 -0.89442719]]
最后
以上就是单纯导师最近收集整理的关于【scikit-learn】2、使用K-近邻算法分类和回归1、K-近邻模型2、惰性学习和非参数模型3、KNN模型分类KNN模型回归的全部内容,更多相关【scikit-learn】2、使用K-近邻算法分类和回归1、K-近邻模型2、惰性学习和非参数模型3、KNN模型分类KNN模型回归内容请搜索靠谱客的其他文章。








发表评论 取消回复